K-均值算法(K-means)
前言
聚类是将数据集中某些方面相似的数据划分在一起,给定简单的规则,对数据集进行分堆,是一种无监督学习。聚类集合中,处于相同聚类中的数据彼此是相似的,处于不同聚类中的元素彼此是不同的。
由于在聚类中那些表示数据类别的分组信息或类标是没有的,即这些数据是没有标签的,所有聚类又被称为无监督学习(Unsupervised Learning)。
聚类算法模型
聚类是将本身没有类别的样本聚集成不同类型的组,每一组数据对象的集合都叫做簇。聚类的目的是让属于同一个类簇的样本之间彼此相似,而不同类簇的样本应该分离。
算法模型图为:
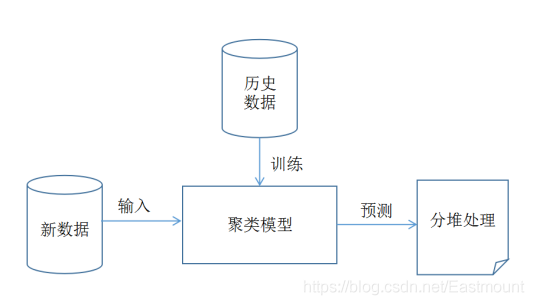
聚类模型的基本步骤包括:
- 训练:通过历史数据训练得到一个聚类模型,该模型用于后面的预测分析。需要注意的是,有的聚类算法需要预先设定类簇数,如KMeans聚类算法。
- 预测:输入新的数据集,用训练得到的聚类模型对新数据集进行预测,即分堆处理,并给每行预测数据计算一个类标值。
- 可视化操作及算法评价:得到预测结果之后,可以通过可视化分析反应聚类算法的好坏,如果聚类结果中相同簇的样本之间距离越近,不同簇的样本之间距离越远,其聚类效果越好。同时采用相关的评价标准对聚类算法进行评估。
常见的聚类算法模型有·:
K-Means聚类
层次聚类
DBSCAN
Affinity
Propagatio
MeanShift
常见的聚类算法
聚类算法在Scikit-Learn机器学习包中,主要调用sklearn.cluster子类实现。
1)K-means算法
K-Means聚类算法最早起源于信号处理,是一种最经典的聚类分析方法。sklearn包调用方法为:
from sklearn.cluster import KMeans
clf = KMeans(n_clusters=2)
# clf.fit(X,y)
2)Mini Batch K-Means
Mini Batch K-means是KMeans的一种变换,目的为了减少计算时间。sklearm包调用方法为:
from sklearn.cluster import MiniBatchKMeans
X= [[1],[2],[3],[4],[3],[2]]
mbk = MiniBatchKMeans(init='k-means++', n_clusters=3, n_init=10)
clf = mbk.fit(X)
print(clf.labels_) # 聚类后的label, 从0开始的数字
# 输出为
[2 2 0 1 0 2]
3)Birch
Birch是平衡迭代归约及聚类算法,全称为Balanced Iterative Reducing and Clustering using Hierarchies,是一种常用的层次聚类算法。该算法通过聚类特征(Clustering Feature,CF)和聚类特征树(Clustering Feature Tree,CFT)两个概念描述聚类。聚类特征树用来概括聚类的有用信息,由于其占用空间小并且可以存放在内存中,从而提高了算法的聚类速度,产生了较高的聚类质量,Birch算法适用于大型数据集。sklearm包调用方法为:
from sklearn.cluster import Birch
X = [[1],[2],[3],[4],[3],[2]]
clf = Birch(n_clusters=2)
clf.fit(X)
y_pred = clf.fit_predict(X)
print(clf)
print(y_pred)
# 输出为
Birch(n_clusters=2)
[1 1 0 0 0 1]
上述代码调用聚类算法Birch算法分成了两类,并对X数据进行训练,共6个点(1、2、3、4、3、2),然后预测其聚类后的类标,输出为0或1两类结果,其中点1、2、2输出类标为1,点3、4、3输出类标为0。将值较大的点(3、4)聚集为一类,将值较小的点(1、2)聚集为另一类。
4)DBSCAN
DBSCAN是一个典型的基于密度的聚类算法,它与划分聚类方法、层次聚类方法不同,它将簇定义为密度相连的点的最大集合,能够把具有足够高密度的区域划分为簇,并可在噪声的空间数据库中发现任意形状的聚类。sklearm包调用方法为:
from sklearn.cluster import dbscan
# core_samples, cluster_ids = dbscan(X, eps=0.2, min_samples=20)
5)Mean Shift
Mean Shift是均值偏移或均值漂移聚类算法,它是一种无参估计算法,沿着概率梯度的上升方向寻找分布的峰值。Mean Shift算法先算出当前点的偏移均值,移动该点到其偏移均值,然后以此为新的起始点,继续移动,直到满足一定的条件结束。
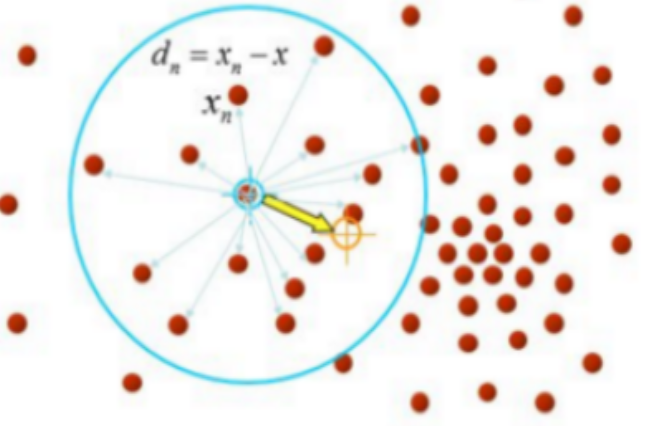
一、K-means算法描述
K-Means算法的思想首先随机指定类中心,根据样本与类中心的远近划分类簇,接着重新计算类中心,迭代直至收敛。但是其中迭代的过程并不是主观地想象得出,事实上,若将样本的类别看做为“隐变量”(latentvariable),类中心看作样本的分布参数,这一过程正是通过EM算法的两步走策略而计算出,其根本的目的是为了得到最小化平方误差函数E:
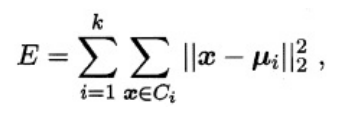
K-means算法流程:
- 第一步,确定K值,即将数据集聚集成K个类簇或小组。
- 第二步,从数据集中随机选择K个数据点作为质心(Centroid)或数据中心。
- 第三步,分别计算每个点到每个质心之间的距离,并将每个点划分到离最近质心的小组,跟定了那个质心。
- 第四步,当每个质心都聚集了一些点后,重新定义算法选出新的质心。
- 第五步,比较新的质心和老的质心,如果新质心和老质心之间的距离小于某一个阈值,则表示重新计算的质心位置变化不大,收敛稳定,则认为聚类已经达到了期望的结果,算法终止。
- 最后,如果新的质心和老的质心变化很大,即距离大于阈值,则继续迭代执行第三步到第五步,直到算法终止。
二、示例说明K-means算法流程
假设存在如下表1所示六个点,需要将其聚类成两堆:
| 坐标点 | X | Y |
|---|---|---|
| P1 | 1 | 1 |
| P2 | 2 | 1 |
| P3 | 1 | 3 |
| P4 | 6 | 6 |
| P5 | 8 | 5 |
| P6 | 7 | 8 |
算法流程:
第一步:随机选取质心。假设选择P1和P2点,以它们为聚类的中心。
第二步:计算其他所有点到质心的距离。采用勾股定理(取一位小数)可得:
| 坐标点 | 到P1点的距离 | 到P2点的距离 |
|---|---|---|
| P3 | 2.0 | 2.2 |
| P4 | 7.1 | 6.4 |
| P5 | 8.1 | 7.2 |
| P6 | 9.2 | 8.6 |
此时聚类分组为:
- 第一组为P1、P3
- 第二组为P2、P4、P5、P6
第三步:组内从新选择质心。
这里涉及到距离的计算方法,通过不同的距离计算方法可以对K-Means聚类算法进行优化。这里计算组内每个点X坐标的平均值和Y坐标的平均值,构成新的质心,它可能是一个虚拟的点。
- 第一组新质心:
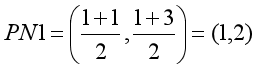
- 第二组新质心:
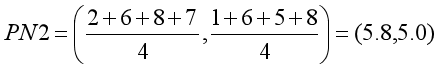
第四步:再次计算各点到新质心的距离。可得表格为:
| 坐标点 | 到P1点的距离 | 到P2点的距离 |
|---|---|---|
| P1 | 1.0 | 6.2 |
| P2 | 1.4 | 5.5 |
| P3 | 1.0 | 5.2 |
| P4 | 6.4 | 1.0 |
| P5 | 7.6 | 2.2 |
| P6 | 8.5 | 3.2 |
则有P1、P2、P3离PN1比较近,P4、P5、P6离PN2比较近。故再次分组为:
- 第一组为P1、P2、P3
- 第二组为P4、P5、P6
第五步:同理,按照第三步计算新的质心。
第一组新质心:
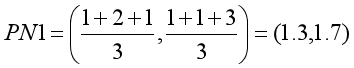
第二组新质心:

第六步 :继续计算点到新质点的距离,可得表格为:
| 坐标点 | 到P1点的距离 | 到P2点的距离 |
|---|---|---|
| P1 | 1.0 | 6.2 |
| P2 | 1.4 | 5.5 |
| P3 | 1.0 | 5.2 |
| P4 | 6.4 | 1.0 |
| P5 | 7.6 | 2.2 |
| P6 | 8.5 | 3.2 |
- 由于第四步和第六步分组情况都是一样的,说明聚类已经稳定收敛,算法就结束,其聚类结果P1、P2、P3一组,P4、P5、P6是另一组,这和我们最初预想的结果完全一致,说明聚类效果良好。
三、K-means算法中Kmean()函数说明
在Sklearn机器学习包中,调用cluster聚类子库的Kmeans()函数即可进行Kmeans聚类运算,该算法要求输入聚类类簇数。KMeans聚类构造方法如下:
clf = KMeans(n_clusters=8
, init='k-means++'
, n_init=10
, max_iter=300
, tol=0.0001
, precompute_distances=True
, verbose=0
, random_state=None
, copy_x=True
, n_jobs=1)
参数说明:
- n_clusters:表示K值,聚类类簇数。
- init:是初始值选择的方式,可以为完全随机选择’random’,优化过的’k-means++‘或者自己指定初始化的K个质心,建议使用默认的’k-means++’。
- n_init:表示用不同初始化质心运算的次数,由于K-Means结果是受初始值影响的局部最优的迭代算法,因此需要多运行几次算法以选择一个较好的聚类效果,默认是10,一般不需要更改,如果你的K值较大,则可以适当增大这个值。
- max_iter:表示最大迭代次数,可以省略。
- tol:float形,默认值= 1e-4。
- precompute_distances:三个可选值,‘auto’,True 或者 False。
预计算距离,计算速度更快但占用更多内存。
(1)‘auto’:如果 样本数乘以聚类数大于 12 million 的话则不予计算距离。This corresponds to about 100MB overhead per job using double precision.
(2)True:总是预先计算距离。
(3)False:永远不预先计算距离。 - random_state:整形或 numpy.RandomState 类型,可选用于初始化质心的生成器(generator)。如果值为一个整数,则确定一个seed。此参数默认值为numpy的随机数生成器。
- copy_x:布尔型,默认值=True。若为Ture的话则原始数据不会改变,若为False的话则直接在原始数据上修改并且在函数返回值时将其还原。
- n_jobs:整形数。 指定计算所用的进程数。内部原理是同时进行n_init指定次数的计算。
(1)若值为 -1,则用所有的CPU进行运算。若值为1,则不进行并行运算,这样的话方便调试。
(2)若值小于-1,则用到的CPU数为(n_cpus + 1 + n_jobs)。因此如果 n_jobs值为-2,则用到的CPU数为总CPU数减1。
四、K-means算法分析篮球数据
篮球数据集下载地址:http://sci2s.ugr.es/keel/dataset.php?cod=1293
该数据集主要包括5个特征,共96行数据,特征包括运动员身高(height)、每分钟助攻数(assists_per_minute)、运动员出场时间(time_played)、运动员年龄(age)和每分钟得分数(points_per_minute)。其特征和值域如下图所示,比如每分钟得分数为0.45,一场正常的NBA比赛共48分钟,则场均能得21.6分。

1.K-means算法聚类
先读取篮球数据前20行数据 :
f = open("basketballData.txt","r") #设置文件对象
for i in range(20):
print(f.readline().strip())
# 输出为
0.0888, 201, 36.02, 28, 0.5885
0.1399, 198, 39.32, 30, 0.8291
0.0747, 198, 38.8, 26, 0.4974
0.0983, 191, 40.71, 30, 0.5772
0.1276, 196, 38.4, 28, 0.5703
0.1671, 201, 34.1, 31, 0.5835
0.1906, 193, 36.2, 30, 0.5276
0.1061, 191, 36.75, 27, 0.5523
0.2446, 185, 38.43, 29, 0.4007
0.167, 203, 33.54, 24, 0.477
0.2485, 188, 35.01, 27, 0.4313
0.1227, 198, 36.67, 29, 0.4909
0.124, 185, 33.88, 24, 0.5668
0.1461, 191, 35.59, 30, 0.5113
0.2315, 191, 38.01, 28, 0.3788
0.0494, 193, 32.38, 32, 0.559
0.1107, 196, 35.22, 25, 0.4799
0.2521, 183, 31.73, 29, 0.5735
0.1007, 193, 28.81, 34, 0.6318
0.1067, 196, 35.6, 23, 0.4326
现在需要通过篮球运动员的数据,判断该运动员在比赛中属于什么位置。如果某个运动员得分能力比较强,他可能是得分后卫;如果身高比较高、篮板能力比较强,他可能是中锋;如果是运球能力比较强,他可能是控球后卫。
下面获取助攻数和得分数两列数据的20行,相当于20*2矩阵。主要调用Sklearn机器学习包的KMeans()函数进行聚类。代码如下:
from sklearn.cluster import KMeans # 导入KMeans聚类模型
# 取上面读取20行文件数据的助攻数和得分数两列数据
X = [[0.0888, 0.5885],
[0.1399, 0.8291],
[0.0747, 0.4974],
[0.0983, 0.5772],
[0.1276, 0.5703],
[0.1671, 0.5835],
[0.1906, 0.5276],
[0.1061, 0.5523],
[0.2446, 0.4007],
[0.1670, 0.4770],
[0.2485, 0.4313],
[0.1227, 0.4909],
[0.1240, 0.5668],
[0.1461, 0.5113],
[0.2315, 0.3788],
[0.0494, 0.5590],
[0.1107, 0.4799],
[0.2521, 0.5735],
[0.1007, 0.6318],
[0.1067, 0.4326],
[0.1956, 0.4280]
]
# print(X)
# Kmeans聚类
clf = KMeans(n_clusters=3) # 将数据集聚集成类簇数为3后的模型赋值给clf
y_pred = clf.fit_predict(X) # 将X数据集进行聚类分析,聚类为3类,对应类标分别为0,1,2
print("SSE = {0}".format(clf.inertia_))# SSE是误差平方和,这个值越接近0说明效果越好
# print(clf)
print(y_pred) # 预测结果
# 可视化操作
import numpy as np
import matplotlib.pyplot as plt
#分别获取获取第1列和第2列值,并赋值给x和y变量。通过for循环获取,n[0]表示X第一列,n[1]表示X第2列。
x = [n[0] for n in X]
y = [n[1] for n in X]
# x,y分别为第一、二列数据,c=y_pred为预测的聚类结果类标;marker='o’说明用点表示图形
plt.scatter(x, y, c=y_pred, marker='x')
plt.title("Basketball Data")
plt.xlabel("assists_per_minute") # 助攻数
plt.ylabel("points_per_minute") # 得分数
plt.legend(["Rank"]) # 设置右上角图例
plt.show()
输出为:
SSE = 0.07931375095238095
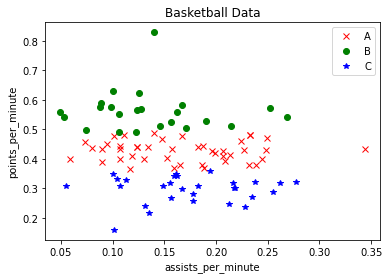
[2 1 2 2 2 2 2 2 0 0 0 2 2 2 0 2 2 2 2 0 0]

从图中可以看到聚集成三类,顶部绿色点所代表的球员比较厉害,得分和助攻都比较高,可能类似于NBA中乔丹、科比等得分巨星;中间黄色点代表普通球员那一类;右下角紫色表示助攻高得分低的一类球员,可能是控位。代码中y_pred表示输出的聚类类标,类簇数设置为3,则类标位0、1、2,它与20个球员数据一一对应。
2.K-means算法聚类优化
前面的代码定义了X数组(共20行、每行2个特征),再对其进行数据分析,而实际数据集通常存储在TXT、CSV、XLS等格式文件中,并采用读取文件的方式进行数据分析的。自己定义数组来聚类分析比较容易,如果是读取文件数据来进行聚类分析。如下:
将上面下载的数据存为.txt文件,再调用K-Means算法聚类分析,并将聚集的三类数据绘制成想要的颜色和形状。txt文件如图所示:

代码如下:
# 第一步 读取数据
import os
data = []
for line in open("basketballData.txt", "r").readlines():
line = line.rstrip() #删除换行
result = ' '.join(line.split()) #删除多余空格,保存一个空格连接
#获取每行的五个值,如'0 0.0888 201 36.02 28 0.5885',并将字符串转换为小数
s = [float(x) for x in result.strip().split(' ')]
data.append(s) #数据存储至data
#输出结果:['0', '0.0888', '201', '36.02', '28', '0.5885']
print(s)
# print(data) # 输出完整数据集
print(type(data)) # 变量类型
# 第二步 获取两列数据
L2 = [n[0] for n in data] # 第一列表示球员每分钟助攻数:assists_per_minute
L5 = [n[4] for n in data] # 第五列表示球员每分钟得分数:points_per_minute
T = dict(zip(L2,L5)) # 两列数据生成二维数据字典
# print('第一列数据', L2)
# print('第五列数据', L5)
type(T)
print('字典=', T)
# 将T从dict类型转换为list
X = list(map(lambda x,y: (x,y), T.keys(),T.values()))
print(type(X))
print('坐标列表=', X)
# 第三步 聚类分析
from sklearn.cluster import KMeans
clf = KMeans(n_clusters=3) # 将数据集聚集成类簇数为3后的模型赋值给clf
# 将X数据集进行聚类分析,聚类为3类,对应类标分别为0,1,2,并将预测赋给y_predict
y_predict = clf.fit_predict(X)
print("SSE = {0}".format(clf.inertia_))# SSE是误差平方和,这个值越接近0说明效果越好
# print(clf)
print('预测结果=', y_predict) # 输出预测结果
# 第四步 绘制图形
import numpy as np
import matplotlib.pyplot as plt
# 获取第一列和第二列数据,使用for循环获取,n[0]表示X第一列
x = [n[0] for n in X]
y = [n[1] for n in X]
# 坐标,初始化为空
x1, y1 = [], []
x2, y2 = [], []
x3, y3 = [], []
# 分布获取类标为0、1、2的数据并赋值给(x1,y1) (x2,y2) (x3,y3)
i = 0
while i < len(X):
# 若y_predict[i]==0时(x1,y1)为(X[i][0],X[i][1])
if y_predict[i]==0:
x1.append(X[i][0])
y1.append(X[i][1])
elif y_predict[i]==1:
x2.append(X[i][0])
y2.append(X[i][1])
elif y_predict[i]==2:
x3.append(X[i][0])
y3.append(X[i][1])
i = i + 1
# 三种颜色 红 绿 蓝,marker='x'表示类型,o表示圆点、*表示星型、x表示点
plot1, = plt.plot(x1, y1, 'or', marker="x")
plot2, = plt.plot(x2, y2, 'og', marker="o")
plot3, = plt.plot(x3, y3, 'ob', marker="*")
plt.title("Basketball Data") # 绘制标题
plt.xlabel("assists_per_minute") # 绘制x轴(助攻数)
plt.ylabel("points_per_minute") # 绘制y轴(得分数)
plt.legend((plot1, plot2, plot3), ('A', 'B', 'C'), fontsize=10) # 设置右上角图例
plt.show()
输出为:
[0.0888, 201.0, 36.02, 28.0, 0.5885]
[0.1399, 198.0, 39.32, 30.0, 0.8291]
[0.0747, 198.0, 38.8, 26.0, 0.4974]
[0.0983, 191.0, 40.71, 30.0, 0.5772]
[0.1276, 196.0, 38.4, 28.0, 0.5703]
[0.1671, 201.0, 34.1, 31.0, 0.5835]
[0.1906, 193.0, 36.2, 30.0, 0.5276]
[0.1061, 191.0, 36.75, 27.0, 0.5523]
[0.2446, 185.0, 38.43, 29.0, 0.4007]
[0.167, 203.0, 33.54, 24.0, 0.477]
[0.2485, 188.0, 35.01, 27.0, 0.4313]
[0.1227, 198.0, 36.67, 29.0, 0.4909]
[0.124, 185.0, 33.88, 24.0, 0.5668]
[0.1461, 191.0, 35.59, 30.0, 0.5113]
[0.2315, 191.0, 38.01, 28.0, 0.3788]
[0.0494, 193.0, 32.38, 32.0, 0.559]
[0.1107, 196.0, 35.22, 25.0, 0.4799]
[0.2521, 183.0, 31.73, 29.0, 0.5735]
[0.1007, 193.0, 28.81, 34.0, 0.6318]
[0.1067, 196.0, 35.6, 23.0, 0.4326]
[0.1956, 188.0, 35.28, 32.0, 0.428]
[0.1828, 191.0, 29.54, 28.0, 0.4401]
[0.1627, 196.0, 31.35, 28.0, 0.5581]
[0.1403, 198.0, 33.5, 23.0, 0.4866]
[0.1563, 193.0, 34.56, 32.0, 0.5267]
[0.2681, 183.0, 39.53, 27.0, 0.5439]
[0.1236, 196.0, 26.7, 34.0, 0.4419]
[0.13, 188.0, 30.77, 26.0, 0.3998]
[0.0896, 198.0, 25.67, 30.0, 0.4325]
[0.2071, 178.0, 36.22, 30.0, 0.4086]
[0.2244, 185.0, 36.55, 23.0, 0.4624]
[0.3437, 185.0, 34.91, 31.0, 0.4325]
[0.1058, 191.0, 28.35, 28.0, 0.4903]
[0.2326, 185.0, 33.53, 27.0, 0.4802]
[0.1577, 193.0, 31.07, 25.0, 0.4345]
[0.2327, 185.0, 36.52, 32.0, 0.4819]
[0.1256, 196.0, 27.87, 29.0, 0.6244]
[0.107, 198.0, 24.31, 34.0, 0.3991]
[0.1343, 193.0, 31.26, 28.0, 0.4414]
[0.0586, 196.0, 22.18, 23.0, 0.4013]
[0.2383, 185.0, 35.25, 26.0, 0.3801]
[0.1006, 198.0, 22.87, 30.0, 0.3498]
[0.2164, 193.0, 24.49, 32.0, 0.3185]
[0.1485, 198.0, 23.57, 27.0, 0.3097]
[0.227, 191.0, 31.72, 27.0, 0.4319]
[0.1649, 188.0, 27.9, 25.0, 0.3799]
[0.1188, 191.0, 22.74, 24.0, 0.4091]
[0.194, 193.0, 20.62, 27.0, 0.3588]
[0.2495, 185.0, 30.46, 25.0, 0.4727]
[0.2378, 185.0, 32.38, 27.0, 0.3212]
[0.1592, 191.0, 25.75, 31.0, 0.3418]
[0.2069, 170.0, 33.84, 30.0, 0.4285]
[0.2084, 185.0, 27.83, 25.0, 0.3917]
[0.0877, 193.0, 21.67, 26.0, 0.5769]
[0.101, 193.0, 21.79, 24.0, 0.4773]
[0.0942, 201.0, 20.17, 26.0, 0.4512]
[0.055, 193.0, 29.07, 31.0, 0.3096]
[0.1071, 196.0, 24.28, 24.0, 0.3089]
[0.0728, 193.0, 19.24, 27.0, 0.4573]
[0.2771, 180.0, 27.07, 28.0, 0.3214]
[0.0528, 196.0, 18.95, 22.0, 0.5437]
[0.213, 188.0, 21.59, 30.0, 0.4121]
[0.1356, 193.0, 13.27, 31.0, 0.2185]
[0.1043, 196.0, 16.3, 23.0, 0.3313]
[0.113, 191.0, 23.01, 25.0, 0.3302]
[0.1477, 196.0, 20.31, 31.0, 0.4677]
[0.1317, 188.0, 17.46, 33.0, 0.2406]
[0.2187, 191.0, 21.95, 28.0, 0.3007]
[0.2127, 188.0, 14.57, 37.0, 0.2471]
[0.2547, 160.0, 34.55, 28.0, 0.2894]
[0.1591, 191.0, 22.0, 24.0, 0.3682]
[0.0898, 196.0, 13.37, 34.0, 0.389]
[0.2146, 188.0, 20.51, 24.0, 0.512]
[0.1871, 183.0, 19.78, 28.0, 0.4449]
[0.1528, 191.0, 16.36, 33.0, 0.4035]
[0.156, 191.0, 16.03, 23.0, 0.2683]
[0.2348, 188.0, 24.27, 26.0, 0.2719]
[0.1623, 180.0, 18.49, 28.0, 0.3408]
[0.1239, 180.0, 17.76, 26.0, 0.4393]
[0.2178, 185.0, 13.31, 25.0, 0.3004]
[0.1608, 185.0, 17.41, 26.0, 0.3503]
[0.0805, 193.0, 13.67, 25.0, 0.4388]
[0.1776, 193.0, 17.46, 27.0, 0.2578]
[0.1668, 185.0, 14.38, 35.0, 0.2989]
[0.1072, 188.0, 12.12, 31.0, 0.4455]
[0.1821, 185.0, 12.63, 25.0, 0.3087]
[0.188, 180.0, 12.24, 30.0, 0.3678]
[0.1167, 196.0, 12.0, 24.0, 0.3667]
[0.2617, 185.0, 24.46, 27.0, 0.3189]
[0.1994, 188.0, 20.06, 27.0, 0.4187]
[0.1706, 170.0, 17.0, 25.0, 0.5059]
[0.1554, 183.0, 11.58, 24.0, 0.3195]
[0.2282, 185.0, 10.08, 24.0, 0.2381]
[0.1778, 185.0, 18.56, 23.0, 0.2802]
[0.1863, 185.0, 11.81, 23.0, 0.381]
[0.1014, 193.0, 13.81, 32.0, 0.1593]
<class 'list'>
字典= {
0.0888: 0.5885, 0.1399: 0.8291, 0.0747: 0.4974, 0.0983: 0.5772, 0.1276: 0.5703, 0.1671: 0.5835, 0.1906: 0.5276, 0.1061: 0.5523, 0.2446: 0.4007, 0.167: 0.477, 0.2485: 0.4313, 0.1227: 0.4909, 0.124: 0.5668, 0.1461: 0.5113, 0.2315: 0.3788, 0.0494: 0.559, 0.1107: 0.4799, 0.2521: 0.5735, 0.1007: 0.6318, 0.1067: 0.4326, 0.1956: 0.428, 0.1828: 0.4401, 0.1627: 0.5581, 0.1403: 0.4866, 0.1563: 0.5267, 0.2681: 0.5439, 0.1236: 0.4419, 0.13: 0.3998, 0.0896: 0.4325, 0.2071: 0.4086, 0.2244: 0.4624, 0.3437: 0.4325, 0.1058: 0.4903, 0.2326: 0.4802, 0.1577: 0.4345, 0.2327: 0.4819, 0.1256: 0.6244, 0.107: 0.3991, 0.1343: 0.4414, 0.0586: 0.4013, 0.2383: 0.3801, 0.1006: 0.3498, 0.2164: 0.3185, 0.1485: 0.3097, 0.227: 0.4319, 0.1649: 0.3799, 0.1188: 0.4091, 0.194: 0.3588, 0.2495: 0.4727, 0.2378: 0.3212, 0.1592: 0.3418, 0.2069: 0.4285, 0.2084: 0.3917, 0.0877: 0.5769, 0.101: 0.4773, 0.0942: 0.4512, 0.055: 0.3096, 0.1071: 0.3089, 0.0728: 0.4573, 0.2771: 0.3214, 0.0528: 0.5437, 0.213: 0.4121, 0.1356: 0.2185, 0.1043: 0.3313, 0.113: 0.3302, 0.1477: 0.4677, 0.1317: 0.2406, 0.2187: 0.3007, 0.2127: 0.2471, 0.2547: 0.2894, 0.1591: 0.3682, 0.0898: 0.389, 0.2146: 0.512, 0.1871: 0.4449, 0.1528: 0.4035, 0.156: 0.2683, 0.2348: 0.2719, 0.1623: 0.3408, 0.1239: 0.4393, 0.2178: 0.3004, 0.1608: 0.3503, 0.0805: 0.4388, 0.1776: 0.2578, 0.1668: 0.2989, 0.1072: 0.4455, 0.1821: 0.3087, 0.188: 0.3678, 0.1167: 0.3667, 0.2617: 0.3189, 0.1994: 0.4187, 0.1706: 0.5059, 0.1554: 0.3195, 0.2282: 0.2381, 0.1778: 0.2802, 0.1863: 0.381, 0.1014: 0.1593}
<class 'list'>
坐标列表= [(0.0888, 0.5885), (0.1399, 0.8291), (0.0747, 0.4974), (0.0983, 0.5772), (0.1276, 0.5703), (0.1671, 0.5835), (0.1906, 0.5276), (0.1061, 0.5523), (0.2446, 0.4007), (0.167, 0.477), (0.2485, 0.4313), (0.1227, 0.4909), (0.124, 0.5668), (0.1461, 0.5113), (0.2315, 0.3788), (0.0494, 0.559), (0.1107, 0.4799), (0.2521, 0.5735), (0.1007, 0.6318), (0.1067, 0.4326), (0.1956, 0.428), (0.1828, 0.4401), (0.1627, 0.5581), (0.1403, 0.4866), (0.1563, 0.5267), (0.2681, 0.5439), (0.1236, 0.4419), (0.13, 0.3998), (0.0896, 0.4325), (0.2071, 0.4086), (0.2244, 0.4624), (0.3437, 0.4325), (0.1058, 0.4903), (0.2326, 0.4802), (0.1577, 0.4345), (0.2327, 0.4819), (0.1256, 0.6244), (0.107, 0.3991), (0.1343, 0.4414), (0.0586, 0.4013), (0.2383, 0.3801), (0.1006, 0.3498), (0.2164, 0.3185), (0.1485, 0.3097), (0.227, 0.4319), (0.1649, 0.3799), (0.1188, 0.4091), (0.194, 0.3588), (0.2495, 0.4727), (0.2378, 0.3212), (0.1592, 0.3418), (0.2069, 0.4285), (0.2084, 0.3917), (0.0877, 0.5769), (0.101, 0.4773), (0.0942, 0.4512), (0.055, 0.3096), (0.1071, 0.3089), (0.0728, 0.4573), (0.2771, 0.3214), (0.0528, 0.5437), (0.213, 0.4121), (0.1356, 0.2185), (0.1043, 0.3313), (0.113, 0.3302), (0.1477, 0.4677), (0.1317, 0.2406), (0.2187, 0.3007), (0.2127, 0.2471), (0.2547, 0.2894), (0.1591, 0.3682), (0.0898, 0.389), (0.2146, 0.512), (0.1871, 0.4449), (0.1528, 0.4035), (0.156, 0.2683), (0.2348, 0.2719), (0.1623, 0.3408), (0.1239, 0.4393), (0.2178, 0.3004), (0.1608, 0.3503), (0.0805, 0.4388), (0.1776, 0.2578), (0.1668, 0.2989), (0.1072, 0.4455), (0.1821, 0.3087), (0.188, 0.3678), (0.1167, 0.3667), (0.2617, 0.3189), (0.1994, 0.4187), (0.1706, 0.5059), (0.1554, 0.3195), (0.2282, 0.2381), (0.1778, 0.2802), (0.1863, 0.381), (0.1014, 0.1593)]
SSE = 0.5351299289171333
预测结果= [1 1 1 1 1 1 1 1 0 0 0 1 1 1 0 1 0 1 1 0 0 0 1 0 1 1 0 0 0 0 0 0 1 0 0 0 1
0 0 0 0 2 2 2 0 0 0 2 0 2 2 0 0 1 0 0 2 2 0 2 1 0 2 2 2 0 2 2 2 2 0 0 1 0
0 2 2 2 0 2 2 0 2 2 0 2 0 0 2 0 1 2 2 2 0 2]
生成三堆指定的图形和颜色散点图为:
3.K-means算法聚类中设置类簇质点
# 第一步 读取数据
import os
data = []
for line in open("basketballData.txt", "r").readlines():
line = line.rstrip() #删除换行
result = ' '.join(line.split()) #删除多余空格,保存一个空格连接
#获取每行的五个值,如'0 0.0888 201 36.02 28 0.5885',并将字符串转换为小数
s = [float(x) for x in result.strip().split(' ')]
data.append(s) #数据存储至data
#输出结果:['0', '0.0888', '201', '36.02', '28', '0.5885']
# print(s)
# print(data) # 输出完整数据集
# print(type(data)) # 变量类型
# 第二步 获取两列数据
L2 = [n[0] for n in data] # 第一列表示球员每分钟助攻数:assists_per_minute
L5 = [n[4] for n in data] # 第五列表示球员每分钟得分数:points_per_minute
T = dict(zip(L2,L5)) # 两列数据生成二维数据字典
# print('第一列数据', L2)
# print('第五列数据', L5)
# type(T)
# print('字典=', T)
# 将T从dict类型转换为list
X = list(map(lambda x,y: (x,y), T.keys(),T.values()))
# print(type(X))
# print('坐标列表=', X)
# 第三步 聚类分析
from sklearn.cluster import KMeans
clf = KMeans(n_clusters=3) # 将数据集聚集成类簇数为3后的模型赋值给clf
y_predict = clf.fit_predict(X)# 将X数据集进行聚类分析,聚类为3类,对应类标分别为0,1,2
print("SSE = {0}".format(clf.inertia_))# SSE是误差平方和,这个值越接近0说明效果越好
# print(clf)
# print('预测结果=', y_predict) # 输出预测结果
# 第四步 绘制图形
import numpy as np
import matplotlib.pyplot as plt
# 获取第一列和第二列数据,使用for循环获取,n[0]表示X第一列
x = [n[0] for n in X]
y = [n[1] for n in X]
# 坐标,初始化为空
x1, y1 = [], []
x2, y2 = [], []
x3, y3 = [], []
# 分布获取类标为0、1、2的数据并赋值给(x1,y1) (x2,y2) (x3,y3)
i = 0
while i < len(X):
# 若y_predict[i]==0时(x1,y1)为(X[i][0],X[i][1])
if y_predict[i]==0:
x1.append(X[i][0])
y1.append(X[i][1])
elif y_predict[i]==1:
x2.append(X[i][0])
y2.append(X[i][1])
elif y_predict[i]==2:
x3.append(X[i][0])
y3.append(X[i][1])
i = i + 1
# 三种颜色 红 绿 蓝,marker='x'表示类型,o表示圆点、*表示星型、x表示点
plot1, = plt.plot(x1, y1, 'or', marker="x")
plot2, = plt.plot(x2, y2, 'og', marker="o")
plot3, = plt.plot(x3, y3, 'ob', marker="*")
plt.title("Basketball Data") # 绘制标题
plt.xlabel("assists_per_minute") # 绘制x轴(助攻数)
plt.ylabel("points_per_minute") # 绘制y轴(得分数)
plt.legend((plot1, plot2, plot3), ('A', 'B', 'C'), fontsize=10) # 设置右上角图例
# plt.show()
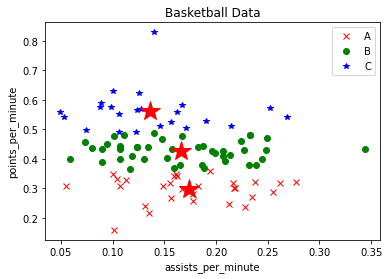
# 第五步 设置类簇中心
centers = clf.cluster_centers_
print('输出类簇质点=', centers)
plt.plot(centers[:,0],centers[:,1],'r*',markersize=20) #显示三个中心点
plt.show()
输出为:
SSE = 0.5351299289171333
输出类簇质点= [[0.1741069 0.29691724]
[0.16596136 0.42713636]
[0.13618696 0.56265652]]
散点图包含类簇质点为:三个红色的五角星为类簇质点
总结
K-means算法一种自下而上的聚类方法,是采用划分法来实现。
K-means算法的优缺点:
优点
- 简洁明了,计算复杂度低。
- 收敛速度较快。 通常经过几个轮次的迭代之后就可以获得还不错的效果。
缺点
- 结果不稳定。 由于初始值随机设定,以及数据的分布情况,每次学习的结果往往会有一些差异。
- 无法解决样本不均衡的问题。对于类别数据量差距较大的情况无法进行判断。
- 容易收敛到局部最优解。 在局部最优解的时候,迭代无法引起中心点的变化,迭代将结束。
- 受噪声影响较大。 如果存在一些噪声数据,会影响均值的计算,进而引起聚类的效果偏差。
- 必须提供聚类的数目,并且聚类结果与初始中心的选择有关,若不知道样本集要聚成多少个类别,则无法使用K-Means算法