提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档
前言
例如:随着人工智能的不断发展,机器学习这门技术也越来越重要,很多人都开启了学习机器学习,本文就介绍了机器学习的基础内容。提示:以下是本篇文章正文内容,下面案例可供参考
十一、聚类
在非监督学习中我们要做的是给这种没有标记的训练集合一个算法并且通过算法来为我们定义一些数据的结构。
对于这种结构的数据集,我们通过算法来发现他们就像被分成两个聚类的点集,因此对于一种算法能够找到数据的分类就称为聚类算法。
应用:
1.市场细分
2.社交网络分析
3.计算机群和数据管理
4.设计数据中心通信
11.1 K-means 算法
K-means算法是硬聚类算法,是典型的基于原型的目标函数聚类方法的代表,它是数据点到原型的某种距离作为优化的目标函数,利用函数求极值的方法得到迭代运算的调整规则。(一般欧式距离作为相似度测度)
具体步骤:
1.首先随机选择聚类中心
2.重复一下过程,知道聚类中心不再变化
簇分配 :
在K均值算法的每次循环中,第一步是要进行簇分配,这就是说,我要遍历所有的样本 ,然后依据每一个点靠近哪一个聚类中心,来将每个数据点分配到两个不同的聚类中心中。
移动聚类中心:
计算出不同聚类的所有点的位置的均值,然后将聚类中心移动到该位置。
公式如下:
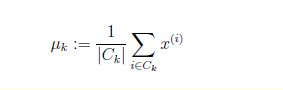
补充: 那么如果存在一个没有点分配给它的聚类中心 ,那怎么办? 通常在这种情况下
我们就直接移除那个聚类中心。如果这么做了,最终将会得到K-1个簇,而不是K个簇,如果就是要K个簇 ,不多不少
,但是有个没有点分配给它的聚类中心,你所要做的是重新随机找一个聚类中心。但是直接移除那个中心是更为常见的方法。
11.2 优化目标函数

K均值算法要做的事情就是,它将找到参数 c(i)c(i)和μiμi 也就是说 找到能够最小化 代价函数 J 的 c 和 μ。 这个代价函数 在K均值算法中有时候也叫做失真代价函数(distortion cost function)
11.3 随机选择聚类中心
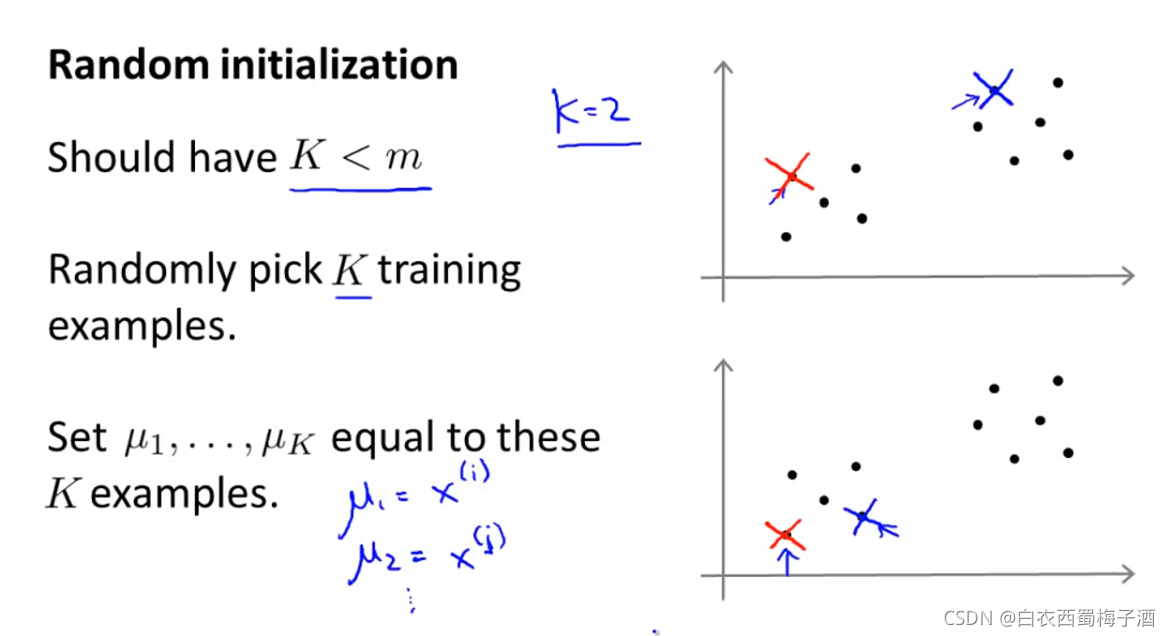 我们一般从样本中随机选择样本点作为聚类中心。
我们一般从样本中随机选择样本点作为聚类中心。
由于初始化聚类中心的不同,可能导致K-Means算法会产生局部最优解。
为了解决该问题,我们可以使用如下方案:
1.随机选择样本点
2.多次初始化聚类中心,然后计算K-Means的代价函数,根据失真代价函数的大小选择最优解。
11.4 选择聚类中心的个数
目前用来决定聚类数目的最常用的方法,仍然是通过看可视化的图或者看聚类算法的输出结果,或者其他一些东西来手动地决定聚类的数目。
一些其他方法:
1.肘部规则
通过失真代价函数关于K大小的函数曲线,代价函数会醉着K的增大逐渐减小,直至趋于稳定,由此我们可以判断,当拐角的时候是最适合的K大小
2.根据应用场景需求设置
举例如下:从T恤生意的角度去考虑 ,其中真正有意义的是需要 ,更多的T恤尺寸来更好地满足我的顾客 ,还是说我需要 更少的T恤尺寸 我制造的T恤尺码就更少 我就可以将它们更便宜地卖给顾客?因此T恤的销售业务的观点 ,可能会提供给你一个 决定采用3个类还是5个类的方法。
3.通过定义指标来判断:
给定一个合适的类簇指标,比如平均半径或直径,然后依据肘部规则来判断。