python爬虫爬取豆瓣电影TOP250
准备工作:
需要安装:requests(发送请求库包),BeautifulSoup(解析库包),re(解析库包),xlwt(写入Excel表的库包)等爬取库包
我这里用到可视化,所以需要matplotlib或pyecharts库包等可视化库包。
题目要求:
本任务以豆瓣电影TOP250为目标(https://movie.douban.com/top250),爬取目标中的中文电影名、年份、评分、评论人数和最热评论的信息,并将爬取得到的信息写入Excel表,最后将排名前10的电影信息(评论人数、评分)可视化显示。
首先我们需要查看网站,查询我们需要爬取的内容:
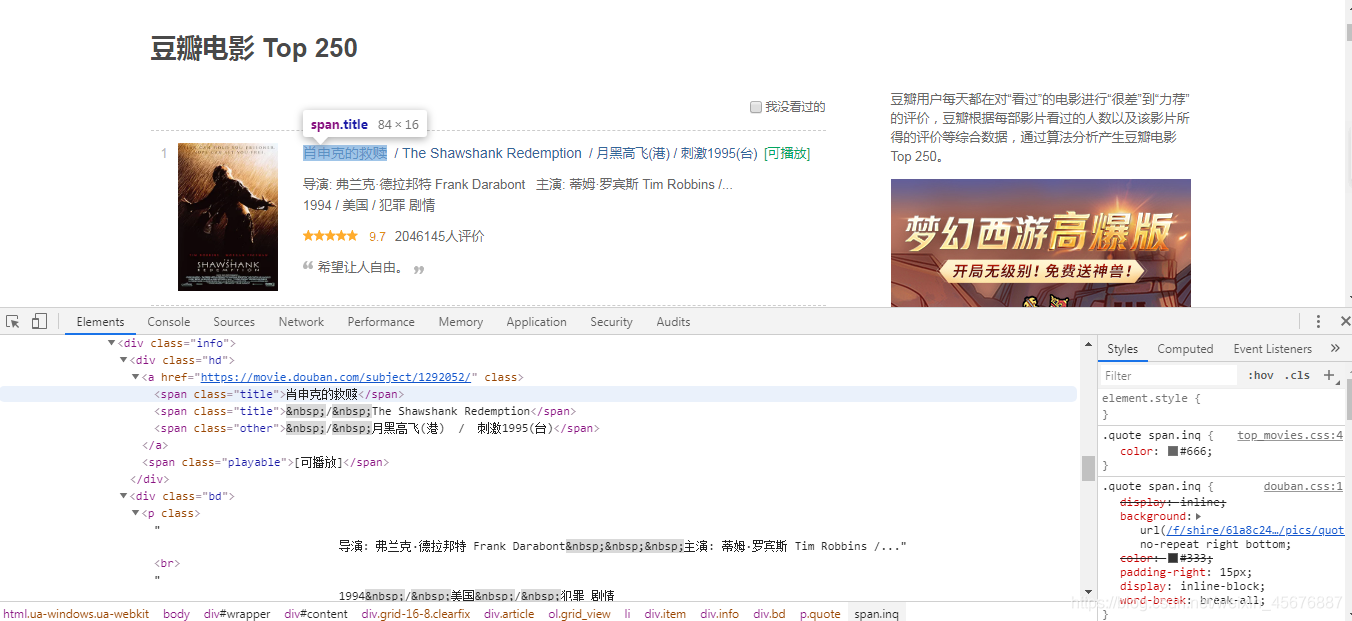
从上图可以知道我们需要的电影名称是在div class="info"下面的div class="hd"下面的a标签下面的span标签下,然后依次找到我们需要爬取的内容,方便后面我们解析数据用。
爬虫的代码如下:
import requests
from bs4 import BeautifulSoup
import re
import xlwt
#找地址
url="https://movie.douban.com/top250"
#模拟浏览器
headers={
'User-Agent':'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/45.0.2454.101 Safari/537.36 QIHU 360SE'
}
#解析url
r=requests.get(url,headers=headers)
#提取数据
ret=r.content
soup=BeautifulSoup(r.text,'lxml')
items=[]
result=soup.select('div[class="info"]')
for i in result:
item={}
name=i.select('div a span')[0].get_text()
string=i.select('div div p')[0].get_text()
year=re.findall('(\w*[0-9]+)\w*', string)[0] #用re模块处理数据,提取数值
grade=i.select('div')[1].select('div div span')[1].get_text()
b=i.select('div')[1].select('div div span')[3].get_text()
number=re.findall('(\w*[0-9]+)\w*', b)[0] #用re模块处理数据,提取数值
commentator=i.select('div')[1].select('div p span')[0].get_text()
item[0]=name
item[1]=year
item[2]=grade
item[3]=number
item[4]=commentator
items.append(item)
title = ["电影名","年份","评分","评价人数","最热评论"]
book = xlwt.Workbook() # 创建一个excel对象
sheet = book.add_sheet('Sheet1',cell_overwrite_ok=True) # 添加一个sheet页
#添加标题和数据
for m in range(len(title)):
sheet.write(0,m,title[m])
for i in range(len(items)): # 循环列
for j in range(len(items[i])):
sheet.write(i+1,j,items[i][j]) # 将title数组中的字段写入到0行i列中
#保存数据
book.save('D:/python爬虫.xlsx')#保存excel
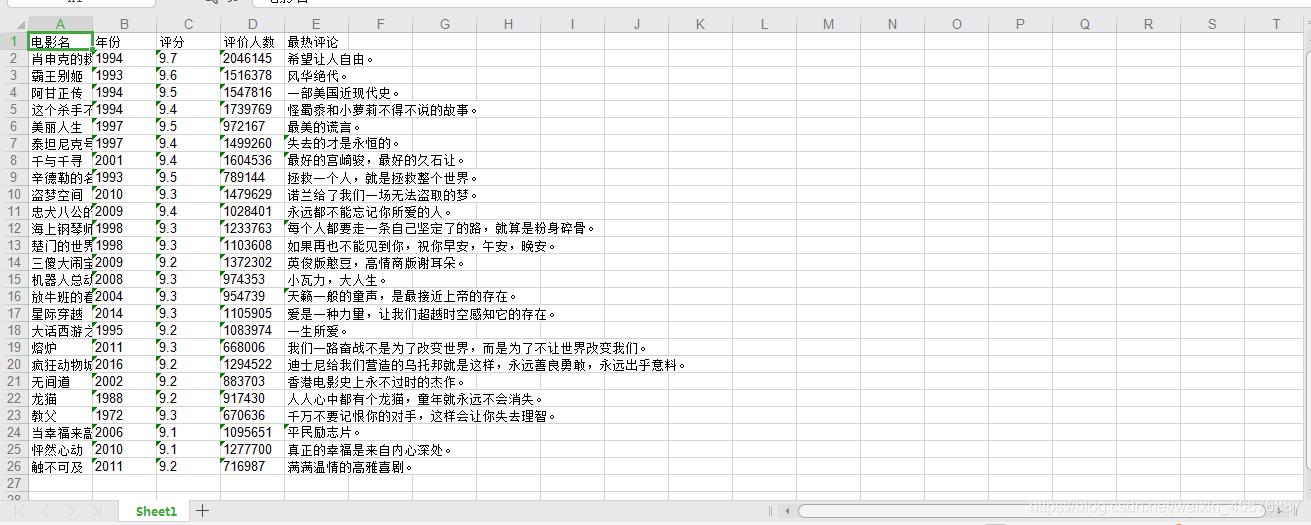
将爬取的数据保存在Excel中,我们可以看到的Excel数据为:
后面然后上面的数据取出前10名的,进行数据可视化:
(注意:这里我用的是matplotlib库,如果用pyecharts库可以依照pyecharts库的中文官网做此题,pyecharts中文官网:http://pyecharts.org/#/zh-cn/intro,下面的代码中的items是上面的items,如果你报错就麻烦点,将上面的代码和这个代码放在一起后再运行。)
#将前10名进行数据可视化
import matplotlib.pyplot as plt
#解决中文乱码的问题
plt.rcParams['font.sans-serif'] = ['KaiTi'] # 指定默认字体
plt.rcParams['axes.unicode_minus'] = False # 解决保存图像是负号'-'显示为方块的问题
x=[]
y=[]
y1=[]
#处理数据,下面的item是上面代码的
for i in range(10):
x.append(items[i][0])
y.append(items[i][2])
y1.append(items[i][3])
#进行简单的数据可视化,创建窗口,绘制图像,显示图像
plt.figure( figsize=(12,9))
plt.bar(x, y)
plt.show()
plt.figure( figsize=(12,9))
plt.bar(x, y1)
plt.show()
运行结果是:(此题的y轴是默认的值,此只是效果图展示,需要更改的要自己再查下百度。)
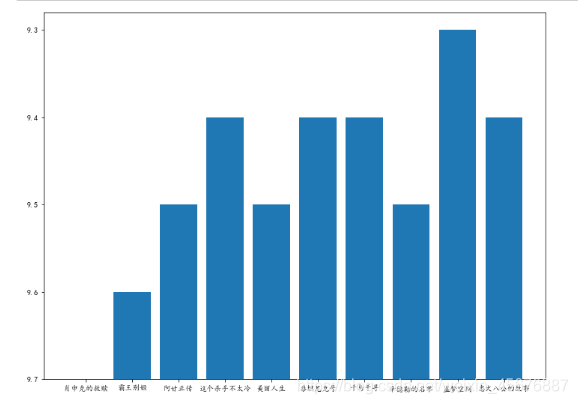
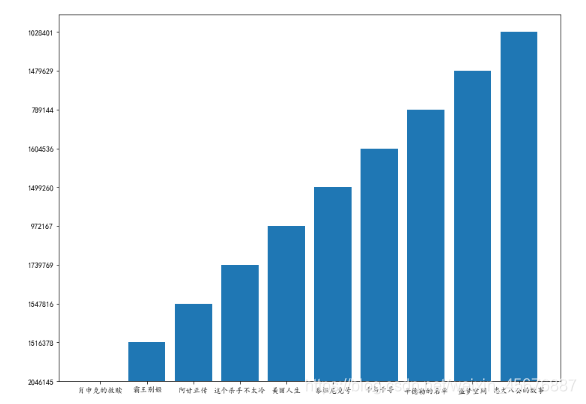
此题就做完了。