目录
Abstract
- 最近的研究表明,通过在移动设备和云之间分配计算工作量,可以显著提高深度神经网络在移动应用中的效率。这种模式被称为协作智能,包括移动设备和云计算之间的特征数据通信。这种方法的效率可以进一步提高,通过有损压缩特征数据,这里迄今为止没有研究。在这项工作中,我们专注于协同目标检测,并研究了特征数据的近无损和有损压缩对其准确性的影响。我们还提出了一种在有损特征压缩下提高精度的策略。实验表明,使用该策略可以在不牺牲精度的前提下减少70%的通信开销。
1. Introduction
- 移动和物联网(IoT)[1]设备越来越依赖人工智能(AI)引擎来实现个人数字助理[2]、自动驾驶汽车、自动驾驶无人机、智能城市等复杂应用。人工智能引擎本身通常建立在深度学习模型上。部署这种模型最常见的方式是将它们放置在云端,并将传感器数据(图像、语音等)从移动设备上传到云端进行处理。这被称为 cloud-only 的方法。最近,随着更小的图形处理单元(gpu)进入移动/物联网设备,一些深度模型可能能够在移动设备上运行,这种方法被称为 mobile-only。
- 最近的一项研究[3]调查了介于云和移动两个极端之间的一系列可能性。具体来说,他们考虑将一个深度网络分为两部分:运行在移动设备上的前端(包括一个输入层和许多后续层)和运行在云上的后端(包括其余层)。在这种被称为协作智能的方法中,前端计算特征到网络中的某一层,然后这些特征被上传到云端,以完成剩余的计算。作者研究了在典型的深度模型中,对于不同的分裂点,以这种方式执行计算的能量消耗和延迟。他们的研究结果表明,如果适当地分割网络,可以在能源和延迟方面实现显著的节省。他们还提出了一种名为“神经外科医生”(Neurosurgeon)的算法,根据能量或延迟是否被最小化来找到最佳分割点。
- 协同智能之所以比纯云和纯移动方式更高效,是因为深度卷积神经网络(CNNs)中的特征数据量通常会随着我们从输入到输出而减少。在移动设备上执行初始层会消耗一些能量和时间,但如果网络被适当地分割,我们最终将会得到更少的数据上传到云端,这将节省上行链路的传输延迟和用于无线传输的能量。因此,总的来说,在能量和/或延迟方面可能会有净收益。基于[3],根据可用的资源(移动端的GPU或CPU,无线传输的速度和能量等),cnn的最佳分割点往往在网络深处。
- 最近发布的一项研究[4]扩展了[3]的方法,包括模型训练和额外的网络架构。虽然网络再次在移动端和云端之间分割,但在[4]中提出的框架中,数据可以在移动端和云端之间以两种方式移动,以优化训练和推理的效率。
- 虽然[3,4]已经确定了协作智能的潜在好处,但特征数据在移动设备和云之间的有效传输问题在很大程度上尚未得到探索。具体来说,[3]完全不考虑特征压缩,而[4]使用8位量化特征数据,然后进行无损压缩,但没有检查这种处理对应用程序的影响。特征压缩可以通过减少特征数据传输的延迟和能量来进一步提高协同智能的效率。压缩输入的影响已经在CNN的几个应用中进行了研究[5,6,7],其效果因情况而异。然而,据我们所知,特征压缩的影响还没有被研究。
- 在这项工作中,我们专注于一个深入的目标检测模型,并研究了特征压缩对其准确性的影响。第2节提出了初步设想,而第3节描述了拟议的方法。第4节和第5节分别给出了实验结果和结论。
2. Preliminaries
-
近年来,随着能够同时检测、定位和分类图像中的对象的深度模型的出现,目标检测已经发生了转变。此类探测器的例子包括R-CNN[8]、SSD[9]和YOLO[10]。这项工作的重点是YOLO。这些检测器的主要创新之一是,它们使用由边界框误差和目标类误差项组成的代价函数进行训练。YOLO损失函数为[10]:
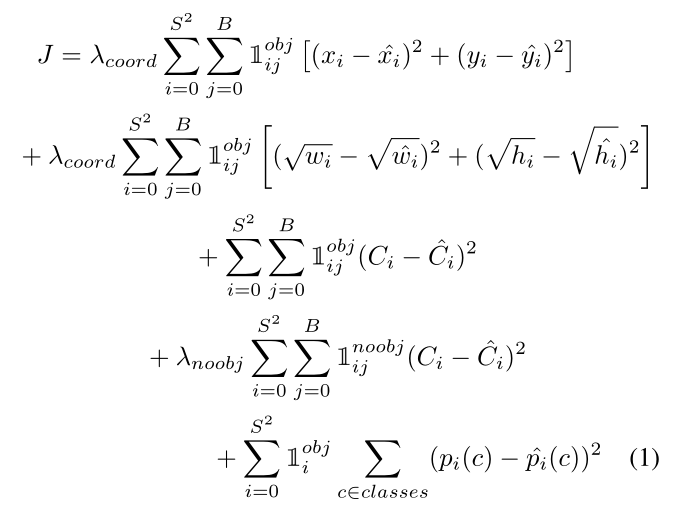
-
其中 ( x i , y i ) (x_i, y_i) (xi,yi) 为真值边界框的中心, w i w_i wi 和 h i h_i hi 为其宽度和高度, ( x ^ i , y ^ i ) (\hat x_i,\hat y_i) (x^i,y^i) 为预测边界框的中心,其宽度和高度分别为 w ^ i \hat w_i w^i 和 h ^ i \hat h_i h^i。 C i C_i Ci 和 C ^ i \hat Ci C^i 是对应于单元格 i i i 的基础真值和预测置信分数, p i ( c ) p_i(c) pi(c) 和 p ^ i ( c ) \hat p_i(c) p^i(c) 是单元格 i i i 中对象类 c c c 的基础真值和预测条件概率,如果单元格 i i i 中的第 j j j 个边界框负责预测, I i j o b j \mathbb{I}_{ij}^{obj} Iijobj 等于1。(在单元格 i i i 的所有框中,框 j j j 的IOU是最大的), I i j n o o b j = 1 − I i j o b j \mathbb{I}_{ij}^{noobj}=1-\mathbb{I}_{ij}^{obj} Iijnoobj=1−Iijobj。使用的缩放因子为 λ c o o r d = 5 λ_{coord} = 5 λcoord=5 和 λ n o o b j = 0.5 λ_{noobj} = 0.5 λnoobj=0.5。
-
我们在这项工作中的实验是基于YOLO9000[11]的最新版本的YOLO。图1显示了该模型每层输出的特征数据量(特征样本数量),以及从输入层到输出层的累计计算成本(归一化执行时间)。计算成本是在使用Titan X GPU和Intel i7-6800K CPU的台式计算机上测量的,计算成本来自第4节描述的数据集的图像。如图所示,从max-pooling层max 7开始,特性数据量相当小。因此,这一层或其他下游层似乎是拆分网络的好点。注意,最大池化层(和其他池化层)减少了数据量,因此从数据大小的角度来看,在最大池化层的输出端而不是输入端分割网络总是有利的。
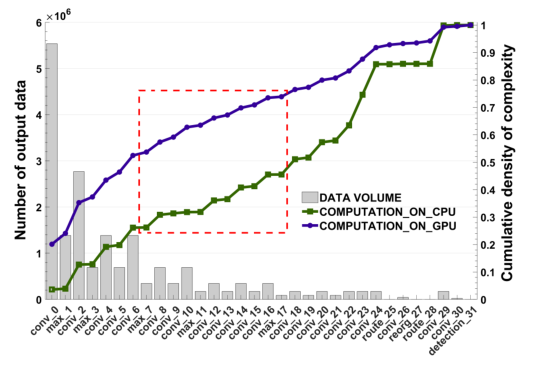
(图1. 累积计算复杂度和逐层输出数据量) -
如果我们在某一层的输出处分割网络,并无损地将其特征数据(32位浮点数)传输到下一层(在云中),那么精度显然会与没有 s p l i t split split 时保持一致。 这就是[3]中所采用的方法,如图2(a)所示。但这是低效的,因为数据可能包含一些冗余。
-
更有效的方法是在将数据上传到云之前对其进行压缩。为了实现这一点,我们可以对数据进行量化,比如每个样本8位,然后对量化后的数据进行无损编码。 这是[4]中采用无损PNG编码器的方法。如图2(b)所示,其中量化层称为q层。这种方法几乎是无损的,因为涉及到一些量化,而且由于这种量化,推断的准确性可能会受到影响。一种更有效的数据传输方法是在q层之后使用有损压缩(图2c),但这将对准确性产生更大的影响。 这些问题将在第4节中讨论。
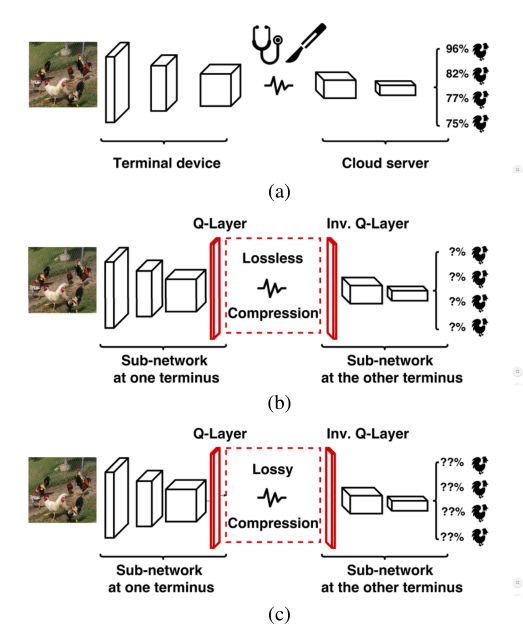
(图2。移动云协同智能的三种方式:(a)无损传输,(b)量化后再无损压缩,©有损压缩。)
Tips:
现有的方法有3中。第1种直接将网络进行分割,传输。这种方法低效,包含冗余。第2种是将网络进行分割,传输过程中对数据进行量化与无损编码。第三种将网络进行分割,传输过程中进行量化和有损压缩。
3. Proposed Methods
3.1 Quantization
Tips:
量化的好处:1.计算效率提升。2.内存和存储占用更少。3.减少耗能。
量化的挑战:如何在压缩率和准确率损失间trade-off。
- 为了利用现有的编解码器,特征数据首先在Q层中被量化到8位、10位或12位精度,并插入到分割点。设 V ∈ R N × M × C V\in\mathbb{R}^{N\times M\times C} V∈RN×M×C 为包含split点特征数据的张量,N行,M列,C个通道。设 min(V) 和 max(V) 分别为 V 中的最小值和最大值。以 n b i t n_{bit} nbit 精度进行量化,并在反Q层进行相应的反量化。
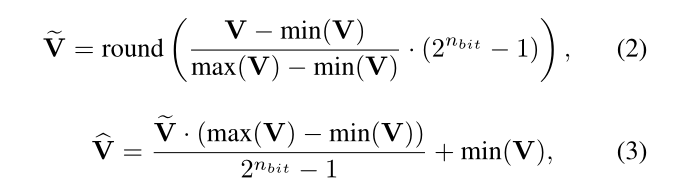
- 式中, V ~ \tilde V V~为量化特征张量, V ^ \hat V V^为反量化特征张量,round(·)表示舍入到最接近整数。min(V) 和 max(V) 需要存储为32bit浮点数(共8字节),并传输到云端进行反量化。在实验中计算总比特数时考虑到了这一点。注意,在某些情况下,例如前一个激活层是 sigmoid 或 ReLU (在[4]中假设),我们可以考虑 min(V) = 0 并避免传输它,但对于更一般的激活层,如Leaky ReLU(在YOLO9000中使用),这个参数是必需的。
Tips:将特征数据被量化到8,10,12位,并放置在切分点。量化是在本地进行,反量化在云端进行。
3.2. Compression
-
量化特征张量 V ~ \tilde V V~可以被许多现有的编解码器编码。如果我们将 N × M × C N × M × C N×M×C张量解释为大小为 N × M N × M N×M的 C C C帧,我们可以使用视频编解码器对其进行压缩。我们可以将一组特征通道组合成更大的帧,最终得到分辨率更大但却少于 C C C帧的结果。最后,所有通道都可以合并成一张图像。即使在这种情况下,也存在许多可能性,例如平铺(图3(a)),即整个通道作为一个平铺放置在图像中,然后是另一个平铺,等等,以及绗缝(图3(b)),即相邻的样本来自不同的通道。我们测试了许多这样的方法,发现通过通道索引简单平铺可以提供最好的结果,所以我们从这里开始使用这种方法。因此,平铺的特征通道被压缩为静止图像。

(图3. 通过(a)平铺和(b)绗缝将特征通道组合成图像。)扫描二维码关注公众号,回复: 14779608 查看本文章
-
在压缩方面,我们采用高效视频编码(HEVC)[12]标准,特别是HEVC范围扩展(RExt)[13],支持各种位深的4:0:0样本格式。实验中的HM16.12[14]以及所有的编码工具和配置都遵循常用测试条件[15]。关闭RDOQ工具,并将编码树单元(CTU)大小设置为16×16,因为在网络深处,特征通道分辨率相对较小。
Tips:
将一组 N × M × C N\times M\times C N×M×C 的张量,解释为大小为 N × M N\times M N×M 的 C C C 帧。那么可以用视频编解码器进行压缩。
3.2 Compression-augmented training
- 我们将在第4节中看到,q层量化后进行无损压缩对精度的影响很小。然而,有损压缩可能会影响精度,特别是当量化参数(QP)较高时。这种准确性的损失可以通过压缩增强训练得到一定程度的补偿。我们不使用随模型提供的网络参数(权值),而是考虑在分裂点的有损压缩来重新训练模型。在训练过程中,每次向前通过网络时,分割点的特征数据将被平铺并使用随机选择的QP值进行压缩。在我们的实验中,我们在[loss, 22, 27, 32,37]范围内使用QP。压缩后,解压缩后的数据在网络中进一步传递。
- 这种压缩增强可以理解为一种正则化形式,将量化噪声插入到网络深处的中间层。它鼓励网络学习下游权值(从分裂点),在处理解压缩特征时提供良好的精度,也学习上游权值,生成对压缩具有鲁棒性的特征。
Experiments
- [11]之后,共有来自VOC2007和VOC2012数据集[16,17]的16,551张图像用于训练,另有来自VOC2007的4,952张图像用于测试。数据集中有20个不同的对象类。
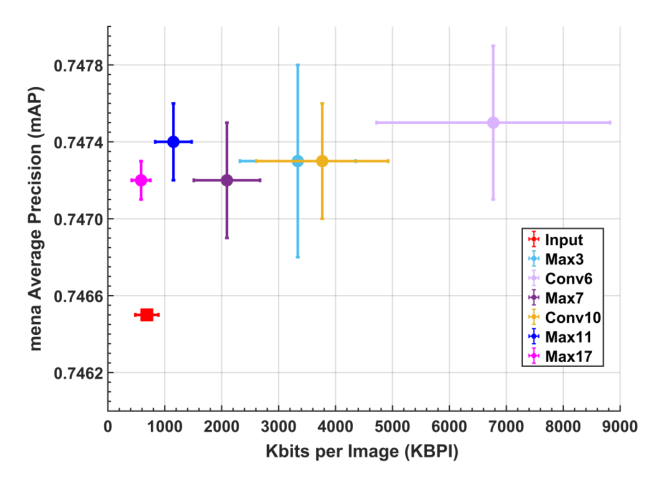
- 我们首先测试无损压缩(在q层之后)对精度的影响。使用平均精度(mean Average Precision, mAP)作为精度的衡量标准,并在q层中观察其在8位、10位和12位量化后的变化。特征数据的压缩采用每幅图像的平均Kbits (KBPI)来量化。图4展示了网络中不同分裂点的mAP和KBPI。竖线表示给定平均KBPI的mAP的标准差,而横线表示相应平均mAP的KBPI的标准差。红色方框表示仅云方法实现的工作点,不需要进行网络分割,也不需要将输入的JPEG图像上传到云端。
- 如图所示,当分裂点接近输入时(如max 3, conv 6或conv 10层),数据量太大,即使对特征数据进行无损压缩,直接将输入图像上传到云端效率更高。但当我们在网络上移动时,上传特征数据变得更有优势。同时,mAP变化不大,所有案例的得分都在0.7465-0.7475之间。因此,深度特征的无损压缩(8位、10位或12位量化之后)对精度的影响很小,但也为向云传输数据节省了有限的(如果有的话)位。
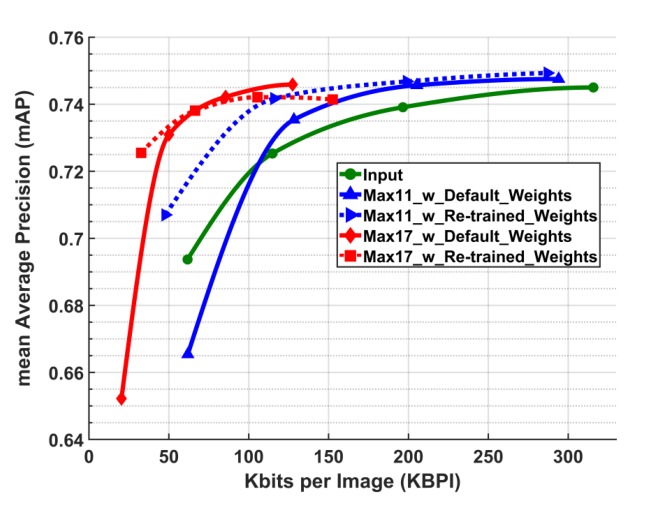
- 有损压缩提供了显著的比特节省,但必须注意尽量减少精度的损失。 为了评估有损压缩的影响,我们在图5中展示了mAP与KBPI的对比曲线。绿色曲线对应于压缩输入图像,这是默认的纯云方法。蓝色曲线对应max 11层输出处的网络分裂,红色曲线对应max 17层后的网络分裂。在每种情况下,实线对应于使用默认的YOLO9000权重,而虚线对应于使用压缩增强训练获得的权重,从预训练权重“Darknet19 448x448”开始,用于ImageNet分类[19],并遵循[20]中的训练过程。如图所示,与纯云方法相比,有损压缩可以节省大量比特,而压缩增强训练则进一步扩展了给定mAP的有用压缩级别范围。
- 为了量化不同情况之间的差异,我们采用Bjontegaard Delta (BD)方法[21]。具体来说,我们使用BD计算来计算BD-KBPI-mAP,它表示同一mAP上KBPI的平均差值。结果如表1所示,其中进行比较的默认情况是只使用云的方法。如表所示,在输出为max 11 (max 17)的情况下压缩特征,同时使用默认权重,与只使用云的方法相比,在相同的mAP下平均节省6%(60%)。同时,通过压缩增强训练获得的权重可额外节省39%(10%)的钻头,总共可节省45%(70%)的bit。
(图4. 用于无损深度特征压缩的mAP与KBPI)
(图5. mAP和KBPI用于有损深度特征压缩)
Conclusions
我们研究了深度特征压缩用于移动和云之间的协同目标检测。我们研究了压缩对检测精度的影响,结果表明8位(或更高)量化数据的无损压缩对检测精度没有太大影响。有损压缩提供了更高的比特节省,但也影响了精度。为了弥补这一点,我们提出了压缩增强训练,这能够扩大有用的压缩水平的范围,以达到所需的精度。

总结
这篇文章内容 1.对网络进行分割,将本地数据量化编码传到云端,在云端反量化进行目标检测。
2. 通道展平进行数据增强。