DEEP COMPRESSION: COMPRESSING DEEP NEURAL NETWORKS WITH PRUNING, TRAINED QUANTIZATION AND HUFFMAN CODING
原作者基于Alex的代码:https://github.com/songhan/Deep-Compression-AlexNet
用Caffe实现:https://github.com/may0324/DeepCompression-caffe
本篇论文是ICLR2016年的best paper
一是对网络剪枝,让连接数量减少;第二是通过共享权重和权重进行索引编码来减小权重数量和存储空间;第三是用霍夫曼编码的方式来编码第二阶段的权重和索引,这样可以进一步压缩空间

PRUNING
稀疏矩阵的存储
稀疏矩阵用compressed sparse row(CSR)和compressed sparse column(CSC)的格式进行压缩,总共需要2a+n+1个存储单元,num是非零元素个数,n是行数或者列数。
格式:
CSC (compressed sparse row)
CSR (compressed sparse column)
把所有的非零值存为数组AA,假设所有的非零值的元素的个数为num,
把每一行第一个非零元素对应在AA的位置存为JA,最后一个数是所有非零元素的个数+1(有的地方是非零元素的个数,就是AA的len+1或者len),所以JA中的元素个数就是行数n+1,
把AA中每一个元素在原始矩阵中的列存为IC。
所以我们把一个原始的n×n的稀疏矩阵存为2num+n+1个数字。

ref
https://blog.csdn.net/bigpiglet_zju/article/details/20791881
采用CSR或者CSC的方法对这个矩阵进行存储从而减少相应的存储量。N*N->2a+N+1
还可以通过差分存储压缩存储数量。
之前的参数存的是绝对的参数,我们现在存相对的参数,就是两个参数的差值。
一个4*4的矩阵可以用一维16数组表示,剪枝时候,只保留 权值大于指定阈值的数,
用相对上一个保留数的距离来表示:例如idx=4和idx=1之间的位置差为3,如果位置差大于设定的span,那么就在span位置插入0。例如15和4之间距离为11大于span(8),所以在4+8的位置插入0,idx=15相对idx=12为3。
这里span阈值在卷积层设置为8,全连接层为5。
例如我们想用三比特的值来存储相应的Index。
3bit可以容忍的间距为8
- 当间距小于8时:用3比特的值就可以恢复出相应的位置
- 当间距大于8时:在第8个位置插入0值,然后用3bit的与插入的0值的差分位置恢复出相应的位置
- 间距大于8的倍数时:每隔8个位置插入0值,与最后一个0值的3bit的差分位置恢复出位置
Matrix = { float val[num + k], diff[num + k], row_ind[m+1] };
num代表非零个数,k 代表当差距超过编码上限时,采用零填充进来, n代表行数
val[]记录非零数字和填充零,
diff[]存放索引的差(除了第一个数字以外),
row_ind[]代表每行第一个非零数字在val中的下标号,最后一个数字仍然是num+1,这样总的数字和为 2*(num+k) + n + 1。
这样压缩的好处是,可以将原存储列索引的数组缩小,达到减小存储大小的目的(如果数组很大的话,效果就会很明显)。
权重量化和共享
共享
权重聚类,只要k种大小的权重(类似于共享一个k大小的权重表),k大的数,只需要log2(k)bits去表示索引,每个权重b bits表示
则压缩率可以为
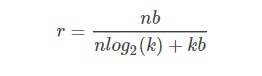
如下图
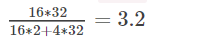

权重更新
是对聚类后的k种权重进行更新
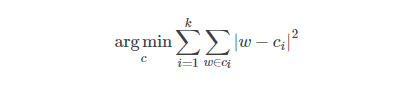
4.2 共享权重的初始化方法(三种)
权值共享的是聚类中心点的位置,初始的聚类中心点是如何确定的呢?
横轴是对应的权值的值,纵轴是权值的数量,类似于直方图一样。红色的线是权值的直方图统计PDF,蓝色的线是权值的累积统计CDF

Forgy: 就是随机初始化方法初始化聚类的中心,如下图,因为权重分布有两个峰值,初始化的值都在峰值附近
基于密度的初始化方法:如下图,先是根据累积分布函数(CDF)线性等分y轴,然后根据CDF找到对应的x轴的坐标,即为聚类的中心。(也是在峰值附近,和Forgy方法相比更分散一些)
线性:就是根据权重的最小值和最大值等分,分散性最大
神经网络中一般权重值越大,它的作用也就越大,所以对于前两种初始化方法都是在峰值附近,也就意味着值数量少的地方很小的概率会被初始化,因为网络中大的权值往往是更重要的,前两种方法容易让聚类的中心点往概率密度大的地方累积,而线性分类法权值更容易是大的。所以线性的初始化方法比较好,通过后面的实验,也发现通过线性的分类方法取得了更好的准确率。
哈弗曼编码
以A,B, C,D 4类为例,
需要用2bit表示聚类中心,00, 01, 10, 11。
假设A,B,C,D数目分别为1000,200,50,1的话,
需要总bits数目为(1000+200+50+1)*2 = 2502,
用Huffman编码的话,根据频率聚类中心表示方式为:A, 0; B 10, C 110, D 111。
那么总长度为1000 + 2002 + 503 + 3 = 1553bit. 达到了压缩的目的。
哈夫曼编码运用字符出现的概率来进行编码,只要不是均匀分布的,哈夫曼编码就能减少一定的冗余,比如在AlexNet中,相应的权值的直方图和权值参数的直方图是上面这两种,用哈夫曼编码可以减少20-30%的信息冗余。

就是按照聚类中心的出现的概率从大到小排序进行Huffman编码
根据上面的结果,权重大都分布在两个峰值附近,所以利于huffman编码
结论
LENet VGGnet
讨论
不同模型压缩比和精度的对比,验证了pruning和quantization一块做效果最好。

不同压缩bit对精度的影响,同时表明conv层比fc层更敏感, 因此需要更多的bit表示。

不同初始化方式对精度的影响,线性初始化效果最好。

卷积层采用8bit,全连接层采用5bit效果最好。

代码分析
https://blog.csdn.net/weixin_44546360/article/details/89877501?depth_1-utm_source=distribute.pc_relevant.none-task&utm_source=distribute.pc_relevant.none-task
