决策树学习笔记(一)
前言
决策树本身没有太多高深的数学方法,它依托于信息论的一些知识以及在数据结构中所学的树形结构。书中阐述的相当清楚明白,可是当我看完这些章节时,却始终无法得知决策树构建的思路,即决策树方法本身的诞生历程是什么?发明算法的作者是如何一步步构建,联想,解决数据分类问题的呢?因此,本文重点还是尝试去理解作者是如何一步步构建决策树,希望能够通过对关键问题进行抽象建模从而找到决策树分类的历史形成。我始终坚信理解why && why not 比起单纯的解释公式更加令人印象深刻。
决策树
定义
决策树是一种基本的分类与回归方法。本文主要讨论用于分类的决策树。决策树模型呈树形结构,在分类问题中,表示基于特征对实例进行分类的过程。它可以认为是if-then规则的集合,也可以认为是定义在特征空间与类空间上的条件概率分布。其主要优点是模型具有可读性,分类速度快。学习时,利用训练数据,根据损失函数最小化的原则建立决策树模型。预测时,对新的数据,利用决策树模型进行分类。决策树学习通常包括3个步骤:特征选择,决策树的生成和决策树的修剪。这些决策树学习的思想主要来源于由Quinlan在1986年提出的ID3算法和1993年提出的C4.5算法,以及由Breiman等人在1984年提出的CART算法。
问题背景
在对一个算法进行阐述时,我们需要了解该算法具体是用来解决什么样的问题,我们先来看书中给出的一个实际例子。
下表是一个由15个样本组成的贷款申请训练数据。数据包括贷款申请人的4个特征:第1个特征是年龄,有三个可能值:青年,中年,老年;第2个特征是有工作,有2个可能值:是,否;第3个特征是有自己的房子,有两个可能值:是,否;第四个特征是信贷情况,有3个可能值:非常好,好,一般。表的最后一列是类别,是否同意贷款,取二个值:是,否。
希望通过所给的训练数据学习一个贷款申请的模型,用以对未来的贷款申请进行分类,即当新的客户提出贷款申请时,根据申请人的特征利用该模型决定是否批准贷款申请。
在前一章节中,我们学习了朴素贝叶斯方法对数据进行分类,那么在该问题中,同样的我们可以尝试用朴素贝叶斯来解决该问题。代码如下
from math import log, exp
dataSet_neg = [[u'青年', u'否', u'否', u'一般'],
[u'青年', u'否', u'否', u'好'],
[u'青年', u'否', u'否', u'一般'],
[u'中年', u'否', u'否', u'一般'],
[u'中年', u'否', u'否', u'好'],
[u'老年', u'否', u'否', u'一般'],
]
dataSet_pos = [[u'青年', u'是', u'否', u'好'],
[u'青年', u'是', u'是', u'一般'],
[u'中年', u'是', u'是', u'好'],
[u'中年', u'否', u'是', u'非常好'],
[u'中年', u'否', u'是', u'非常好'],
[u'老年', u'否', u'是', u'非常好'],
[u'老年', u'否', u'是', u'好'],
[u'老年', u'是', u'否', u'好'],
[u'老年', u'是', u'否', u'非常好'],
]
class LaplaceEstimate(object):
"""
拉普拉斯平滑处理的贝叶斯估计
"""
def __init__(self):
self.d = {} # [词-词频]的map
self.total = 0.0
self.none = 1
def exists(self, key):
return key in self.d
def getsum(self):
return self.total
def get(self, key):
if not self.exists(key):
return False, self.none
return True, self.d[key]
# 计算P(x | y)
def getprob(self, key):
return float(self.get(key)[1]) / self.total
def samples(self):
"""
获取全部样本
:return:
"""
return self.d.keys()
def add(self, key, value):
self.total += value
# map {key:value} ={'好':2}
if not self.exists(key):
self.d[key] = 1
self.total += 1
self.d[key] += value
class Bayes(object):
def __init__(self):
self.d = {}
self.total = 0
# 参数计算
def train(self, data):
for d in data:
c = d[1]
# 对每个分类进行统计 建立map d[pos] 和 d[neg]
if c not in self.d:
self.d[c] = LaplaceEstimate() # 生成拉普拉斯平滑
# 对特征向量中每个随机变量进行统计
for word in d[0]:
self.d[c].add(word, 1)
self.total = sum(map(lambda x: self.d[x].getsum(), self.d.keys()))
def classify(self, x):
tmp = {}
# 循环每一个分类标签
for c in self.d:
tmp[c] = log(self.d[c].getsum()) - log(self.total)
for word in x:
tmp[c] += log(self.d[c].getprob(word))
ret, prob = 0, 0
for c in self.d:
now = 0
try:
for otherc in self.d:
now += exp(tmp[otherc] - tmp[c])
now = 1 / now
except OverflowError:
now = 0
if now > prob:
ret, prob = c, now
return (ret, prob)
class Sentiment(object):
def __init__(self):
self.classifier = Bayes()
def train(self, neg_docs, pos_docs):
data = []
# 合并特征向量和分类标签
for sent in neg_docs:
data.append([sent, u'neg'])
for sent in pos_docs:
data.append([sent, u'pos'])
self.classifier.train(data)
def classify(self, sent):
return self.classifier.classify(sent)
s = Sentiment()
# 测试贷款申请样本数据表
s.train(dataSet_neg, dataSet_pos)
# 测试分类数据的准确率
print("----------neg data------------")
for sent in dataSet_neg:
print("是否贷款 否",sent,s.classify(sent))
print("----------pos data------------")
for sent in dataSet_pos:
print("是否贷款:是",sent,s.classify(sent))输出结果:
----------neg data------------
是否贷款 否 ['青年', '否', '否', '一般'] ('neg', 0.9652418693866692)
是否贷款 否 ['青年', '否', '否', '好'] ('neg', 0.8695344602978868)
是否贷款 否 ['青年', '否', '否', '一般'] ('neg', 0.9652418693866692)
是否贷款 否 ['中年', '否', '否', '一般'] ('neg', 0.9398342936170037)
是否贷款 否 ['中年', '否', '否', '好'] ('neg', 0.7894286145455698)
是否贷款 否 ['老年', '否', '否', '一般'] ('neg', 0.8928312012034658)
----------pos data------------
是否贷款:是 ['青年', '是', '否', '好'] ('pos', 0.7452744081969142)
是否贷款:是 ['青年', '是', '是', '一般'] ('pos', 0.9319390468398445)
是否贷款:是 ['中年', '是', '是', '好'] ('pos', 0.9902369967212153)
是否贷款:是 ['中年', '否', '是', '非常好'] ('pos', 0.9397743845347943)
是否贷款:是 ['中年', '否', '是', '非常好'] ('pos', 0.9397743845347943)
是否贷款:是 ['老年', '否', '是', '非常好'] ('pos', 0.9669508149127215)
是否贷款:是 ['老年', '否', '是', '好'] ('pos', 0.9069996183883087)
是否贷款:是 ['老年', '是', '否', '好'] ('pos', 0.9069996183883087)
是否贷款:是 ['老年', '是', '否', '非常好'] ('pos', 0.9669508149127213)可见,运用朴素贝叶斯算法,同样能够对数据进行准确的判别。即对表中的数据拟合的非常完美,达到了100%。但是否这就意味着对测试数据的拟合结果好呢?在实现了决策树算法后,我们对两者算法进行一些数据模拟,看看哪种算法对测试数据的准确性更高。这里,先来看看决策树是如何一步步实现的?
尝试模拟决策树的构建历程
接下来,我们考虑如下问题:
假设我们忽略问题中给出的所有数据的特征向量,诸如年龄信息,工作信息,有无房子信息,信贷情况。即现在给定的数据中只有类别信息,即银行决定是否贷款。可以贷款的数据样本表示”是”,而不能贷款的数据样本表示“否”,并且假设我们知道能否贷款背后隐藏了一系列特征向量,但目前我们并不清楚是什么具体影响了银行的决策。银行统计的数据集样本量为 。
OK,如果我们没有任何分类准则,也就是说,没有任何特征向量去尝试区分数据样本,即没有定义用以决策银行是否贷款的规则是毫无意义的。为什么这么说,因为数据样本的标签只是在宏观上有一种统计效果,即占比m%属于可以贷款,占比(100-m)%属于不可以贷款,银行不能针对任何信息来进行决策。
由于对银行来说,数据样本没有任何特征属性,所以把n个数据样本中的任意m个数据作为可以贷款的样本,本质上是没有差别的。只要符合统计占比即可,如在上表中,n为15,m为9。由此,我们可以根据组合公式算出
,记为N个数据中为m个是可以贷款样本的所有可能情况。(即排列组合
) 因此得
为了进一步阐述,我们可以假设N个数据样本可以分为两类,分别为 ,且 ,所以上述公式又可以表示为
也就是说,没有特征向量来区分任何数据样本时,对银行来说,任意样本既可以当作能贷款样本,也可以当作不能贷款样本。由此,可以求出,样本总量为N的情况下,可能的情况数为 。这里 即表示了所谓的样本不确定性。假设 为变量,那么 是关于 的函数,由此 的变化反映了 的变化。当N很大时, 将变得非常大,为了方便度量和剔除总数N的影响,我们定义函数
来表示上述组合的不确定性,因为 越大,数据样本的排列组合情况越多。
不知道你从上式能看出什么来,是否已经像极了《统计学习方法》中信息熵的定义呢。没错,它其实就是信息熵的定义,也是最贴切地由实际例子推导出来的公式。无非我们需要用到一些数学公式把它转化到信息熵真正的定义式。参考知乎大神关于熵的解释:能否尽量通俗地解释什么叫做熵?
使用数学上有名的Stirling公式,当N很大时有近似:
于是
在信息论中,熵是表示随机变量不确定性的度量。设X是一个取有限个值的离散随机变量,其概率分布为
一个离散概率密度的熵是:
有没有发现和上面的推导结果惊人一致,只需要令 。
因此我们可以得出,某种状态的熵不过是具有这种状态的组合数的对数归一化表示: 。组合数多了就更不知道到底是其中的哪一个,系统的无序性、复杂性也大了,从上面的推导得出熵也大了。
当然,熵并非只是用来衡量系统的不确定性,它还有很多深刻的哲理,甚至能用来解释宇宙的诞生与消亡,各种熵增现象等等。这里推荐一部纪录片:《宇宙的奇迹:时间之箭》BBC.
好了,也就是说实际的标签分类问题转化为对数据样本不确定性的研究。其实我们都知道,银行统计的数据中是不可能不带有任何特征属性的,否则统计的意义何在?因此,我们给数据样本加上一维特征,如是否有工作,因此现在的数据样本表示为(“有工作”,“类别”)。同样的,我们将得到如下表所示:
| 有工作(总量 = 5) | 无工作(总量 = 10) | |
|---|---|---|
| 能否贷款 | 是,是,是,是,是 | 否,否,否,否,否,否 |
| 是,是,是,是 |
现在给定了一维的特征向量,也就是决策树中所提到的分类准则,即按照有无工作,我们可以把数据样本精确的划分为两类。每一类中,数据样本有了新的占比。在有工作一类中,由于所有的数据均表示能够贷款,因此,根据现有数据我们可以判断,在有工作的人群中,银行都是可以贷款的。那是否意味着该准则就行之有效呢?咱们再来看看无工作的情况,什么情况,根据现有规则,还是无法区分能否贷款。因为在10个样本中,出现了6个不可以贷款的情况和4个可以贷款的情况,显然还有隐藏的未知特征决定着分类准则。
我们知道了,根据一维特征是无法区分类别的,因此银行重新对数据进行了统计,并且同时考虑了年龄因素和有工作因素。这时候,我们再来看看能否有效的区分数据呢?数据样本格式为(“年龄”,”有工作”,”类别”)。因此,我们又可以对数据进行归类,得到如下表:
| 有工作(总量 = 5) | 无工作(总量 = 10) | |
|---|---|---|
| 青年(总量 = 5) | 是,是 | 否,否,否 |
| 中年(总量 = 5) | 是 | 否,否,是,是 |
| 老年(总量 = 5) | 是,是 | 是,是,否 |
从表格能看出,青年,有无工作均能区分,而中年无工作和老年无工作是无法区分的,因此,银行又得重新统计一遍数据,加入第三维特征向量,这里就不在一一例举了。最终银行加入的维度有四维,数据样本格式为(“年龄”,”有工作”,”有自己的房子”,”信贷情况”,”类别”)。
既然有了多维的各种特征,那是否意味着选择哪一个特征来进行最初的分类,能够影响决策树的分类效率呢?答案其实很明显,特征的选取顺序是能够影响决策树的构建,进而影响分类效率。否则我们也就没有必要定义
了。显示地,我们来考虑有工作的情况,在上表中我们得到了有工作后的数据样本分类结果,即在有工作的情况下,数据完全能够得到区分,即对于银行来说,这一部分的可能情况只有1种。而在表格的右边,即无工作情况下的10个样本中,银行还是无法区分这些样本。在10个样本中,有4个样本可以贷款,6个样本无法贷款。同理,这些数据在无工作情况下,对银行是没有任何区别的,所以可能情况为
种。等价的,根据信息熵的定义,我们还可以写成
极端情况下,如果算出的 均为0,那么根据现有特征,该分类就已经确定了。所以说,直观上 取最小,能够尽可能的减少决策树的高度,避免冗余的特征选择。既然我们有了在某个条件下的不确定度的比较公式,那么同样的,我们算一算以年龄为分类准则时的不确定度。列出如下表格:
| 青年(总量 = 5) | 中年(总量 = 5) | 老年(总量 = 5) | |
|---|---|---|---|
| 能否贷款 | 否,否,是,是,否 | 否,否,是,是,是 | 是,是,是,是,否 |
得到各分类情况下信息熵为:
上述三个式子分别表示了,青年,中年,老年的不确定度。可应该如何表示在给定随机变量X的条件下,随机变量Y的不确定性呢?即我们不能简单的把各不确定度加起来,因为信息熵的定义剔除了样本总量的影响,即我们所谓的归一化,在不确定度 的前面乘以 ,而正是这个因子能够让我们把物理上描述的 ,即不确定次数映射到了概率统计问题。由此,从信息熵的推导过程可以看出,信息熵单纯的不确定度累加,并不是真实的物理不确定次数的累加。
那么我们应该怎么描述含有一维特征属性的数据样本的不确定度呢?其实很简单,我们回归最单纯的不确定次数定义就好了,也就是在归一化前的不确定次数,还记得数据样本标签的不确定次数是如何求解的嘛?这里我们直接给出针对该问题的数学公式
这里 分别表示在N个数据样本中青年,老年,中年的样本数。即 .而 分别表示在某个给定的一维标签下,如青年样本中可以贷款的个数和不能贷款的个数。这是没有归一化过的不确定次数了,由于银行划分了三类,因此总的不确定次数可以直接相加,得到
再由 Stirling公式近似得到
代入实际数据运算得
到了这一步,我们才能进行归一化处理,即把它映射到概率统计问题上去。所以等式两边同乘以归一化因子 ,N为统计样本的总量。
代入实际数据得
这其实就是我们银行最终在给定一维特征属性情况下的不确定度,但我们会发现这样的公式非常不方便,即我们无法独立的描述在这个特征属性下每种分类的不确定度,无法用先前定义的信息熵来表述这式子。但数学的好处在于你没法直接表述,我可以通过一些数学变换来间接求得表述形式。我们有了,
在每个式子 前乘以 ,我们便得到
其中满足 ,经过该数学变换,我们能够发现,其实大括号里的每项都是我们先前计算的只针对某个特征属性上的分类标签的信息熵, ,因此,在给定数据样本总量N的情况下,整体的信息熵就变成了
其中 ,对比下书中条件熵的定义,不就是它嘛。书中更加严格的定义为:条件熵 表示在已知随机变量X的条件下随机变量Y的不确定性。随机变量X给定的条件下随机变量Y的条件熵 ,定义为X给定条件下Y的条件概率分布的熵对X的数学期望
这里, .
直观上来说,特征向量影响了数据样本的分布(不确定性),一种内在的联系导致数据分布情况的改变,但在给定的数据中,我们是无法确定或者说求解出这种内在联系是什么,只能根据统计结果来判断数据样本的不确定性。决策树的本质在于,我们需要将分类标签和特征属性联系在一起,在没有特征时,数据样本的不确定性最大,而随着不断加入的特征属性时,统计上我们能够逐渐降低不确定度,当不确定度降为0时,我们便能够根据现有特征属性来做决策。从决策树的构建构成中,为了降低决策的成本,每次我们都选择一个能够尽可能大得降低不确定性的特征作为我们首要决策依据,从而做到快速分类。
回归上述问题,现在我们已经知道了特征选择的策略是选取那些能够使得数据样本不确定度最小的特征属于,贷款申请样本数据表中含有四个特征属性,经过计算,我们发现有自己的房子的不确定度相比任何其他三个特征属性是最小的,因此我们优先选择有无房子作为我们决策树的根结点。
| 有房(总量 = 6) | 无房(总量 = 9) | |
|---|---|---|
| 能否贷款 | 是,是,是,是,是,是 | 否,否,是,否,否,否 |
| 是,是,否 |
数据样本经过划分,我们得到了如上表的分类数据,银行的决策规则更新如下,如果有房,那么所有测试样本都能够贷款,因为在统计的数据样本中,没有不能贷款的反例出现,这里的不确定情况为1,不确定度为0。如果无房,由于统计数据样本中有是有否,因此还需根据目前的数据样本,重新进行不确定度计算,这是递归的一个过程。
走到这一步,决策树的构建过程基本已经全部阐述完毕了,但这里与书中有所区别的一步在于书中在对特征进行选取时,用到了信息增益的概念,主要定义如下:特征A对训练数据集D的信息增益
,定义为集合D的经验熵
与特征A给定条件下D的经验条件熵
之差,即
ID3算法特征选取时,是选择信息增益最大的特征,从我们刚才推导的过程中,并没有信息增益这个概念,我们直接选择最小的 ,理论上这两种计算方法在选择特征时效果是一样的,但为何需要多次一举呢?暂时不解。为了与书中ID3算法中描述的一致性,我们还是选择书中信息增益这个概念来选择特征,毕竟理论上没有区别,就按照书本来吧。
ID3算法
ID3算法的核心是在决策树各个结点上应用信息增益准则选择特征,递归地构建决策树。具体方法是:从根结点开始,对结点计算所有可能的特征的信息增益,选择信息增益最大的特征作为结点的特征,由该特征的不同取值建立子结点;再对子结点递归地调用以上方法,构建决策树;直到所有特征的信息增益均很小或没有特征可以选择为止。最后得到一个决策树,ID3相当于用极大似然法进行概率模型的选择。(从具体算法层面理解?)
算法(ID3算法)
输入:训练数据集D,特征集A,阈值
输出:决策树T
(1) 若D中所有实例属于同一类 ,则T为单结点树,并将类 作为该结点的类标记,返回T;
(2) 若 ,则T为单结点树,并将D中实例数最大的类 作为该结点的类标记,返回T;
(3) 否则,计算A中各特征对D的信息增益,选择信息增益最大的特征 ;
(4) 如果 的信息增益小于阈值 ,则置T为单结点树,并将D中实例数最大的类 作为该结点的类标记,返回T;
(5) 否则,对 的每一个可能值 ,依 将D分割为若干非空子集 ,将 中实例数最大的类作为标记,构建子结点,由结点及其子结点构成树T,返回T;
(6) 对第i个子子结点,以 为训练集,以 为特征集,递归地调用步(1)~(5),得到子树 ,返回 ;
Code Time
ID3算法python实现过程
有了ID3算法的伪代码,我们来看看实际中是如何一步步实现的。回顾下银行贷款问题,我们根据贷表申请样本数据表创建数据集,代码参考机器学习实战。
def createDataSet():
"""
创建数据集
"""
dataSet = [[u'青年', u'否', u'否', u'一般', u'拒绝'],
[u'青年', u'否', u'否', u'好', u'拒绝'],
[u'青年', u'是', u'否', u'好', u'同意'],
[u'青年', u'是', u'是', u'一般', u'同意'],
[u'青年', u'否', u'否', u'一般', u'拒绝'],
[u'中年', u'否', u'否', u'一般', u'拒绝'],
[u'中年', u'否', u'否', u'好', u'拒绝'],
[u'中年', u'是', u'是', u'好', u'同意'],
[u'中年', u'否', u'是', u'非常好', u'同意'],
[u'中年', u'否', u'是', u'非常好', u'同意'],
[u'老年', u'否', u'是', u'非常好', u'同意'],
[u'老年', u'否', u'是', u'好', u'同意'],
[u'老年', u'是', u'否', u'好', u'同意'],
[u'老年', u'是', u'否', u'非常好', u'同意'],
[u'老年', u'否', u'否', u'一般', u'拒绝'],
]
labels = [u'年龄', u'有工作', u'有房子', u'信贷情况']
# 返回数据集和每个维度的名称
return dataSet, labels可以根据特征分割数据集:
def splitDataSet(dataSet,axis,value):
"""
按照给定特征划分数据集
:param axis:划分数据集的特征的维度
:param value:特征的值
:return: 符合该特征的所有实例(并且自动移除掉这维特征)
"""
# 循环遍历dataSet中的每一行数据
retDataSet = []
for featVec in dataSet:
if featVec[axis] == value:
reduceFeatVec = featVec[:axis] # 删除这一维特征
reduceFeatVec.extend(featVec[axis+1:])
retDataSet.append(reduceFeatVec)
return retDataSet
该函数注意数组featVec[:axis]和featVec[axis+1:]的用法。
计算信息熵:
# 计算的始终是类别标签的不确定度
def calcShannonEnt(dataSet):
"""
计算训练数据集中的Y随机变量的香农熵
:param dataSet:
:return:
"""
numEntries = len(dataSet) # 实例的个数
labelCounts = {}
for featVec in dataSet: # 遍历每个实例,统计标签的频次
currentLabel = featVec[-1] # 表示最后一列
# 当前标签不在labelCounts map中,就让labelCounts加入该标签
if currentLabel not in labelCounts.keys(): labelCounts[currentLabel] =0
labelCounts[currentLabel] +=1
shannonEnt = 0.0
for key in labelCounts:
prob = float(labelCounts[key]) / numEntries
shannonEnt -= prob * log(prob,2) # log base 2
return shannonEnt计算条件熵:
def calcConditionalEntropy(dataSet,i,featList,uniqueVals):
"""
计算x_i给定的条件下,Y的条件熵
:param dataSet: 数据集
:param i: 维度i
:param featList: 数据集特征列表
:param unqiueVals: 数据集特征集合
:return: 条件熵
"""
ce = 0.0
for value in uniqueVals:
subDataSet = splitDataSet(dataSet,i,value)
prob = len(subDataSet) / float(len(dataSet)) # 极大似然估计概率
ce += prob * calcShannonEnt(subDataSet) #∑pH(Y|X=xi) 条件熵的计算
return ce计算信息增益:
def calcInformationGain(dataSet,baseEntropy,i):
"""
计算信息增益
:param dataSet: 数据集
:param baseEntropy: 数据集中Y的信息熵
:param i: 特征维度i
:return: 特征i对数据集的信息增益g(dataSet | X_i)
"""
featList = [example[i] for example in dataSet] # 第i维特征列表
uniqueVals = set(featList) # 换成集合 - 集合中的每个元素不重复
newEntropy = calcConditionalEntropy(dataSet,i,featList,uniqueVals)
infoGain = baseEntropy - newEntropy # 信息增益
return infoGain算法骨架:
def chooseBestFeatureToSplitByID3(dataSet):
"""
选择最好的数据集划分
:param dataSet:
:return:
"""
numFeatures = len(dataSet[0]) -1 # 最后一列是分类
baseEntropy = calcShannonEnt(dataSet)
bestInfoGain = 0.0
bestFeature = -1
for i in range(numFeatures): # 遍历所有维度特征
infoGain = calcInformationGain(dataSet,baseEntropy,i)
if(infoGain > bestInfoGain):
bestInfoGain = infoGain
bestFeature = i
return bestFeature # 返回最佳特征对应的维度
def createTree(dataSet,labels,chooseBestFeatureToSplitFunc = chooseBestFeatureToSplitByID3):
"""
创建决策树
:param dataSet: 数据集
:param labels: 数据集每一维的名称
:return: 决策树
"""
classList = [example[-1] for example in dataSet] # 类别列表
if classList.count(classList[0]) == len(classList): # 统计属于列别classList[0]的个数
return classList[0] # 当类别完全相同则停止继续划分
if len(dataSet[0]) ==1: # 当只有一个特征的时候,遍历所有实例返回出现次数最多的类别
return majorityCnt(classList) # 返回类别标签
bestFeat = chooseBestFeatureToSplitFunc(dataSet)
bestFeatLabel = labels[bestFeat]
myTree ={bestFeatLabel:{}} # map 结构,且key为featureLabel
del (labels[bestFeat])
# 找到需要分类的特征子集
featValues = [example[bestFeat] for example in dataSet]
uniqueVals = set(featValues)
for value in uniqueVals:
subLabels = labels[:] # 复制操作
myTree[bestFeatLabel][value] = createTree(splitDataSet(dataSet,bestFeat,value),subLabels)
return myTree
# 测试决策树的构建
dataSet,labels = createDataSet()
myTree = createTree(dataSet,labels)输出结果:
{'有房子': {'是': '同意', '否': {'有工作': {'是': '同意', '否': '拒绝'}}}}为了让决策树展现得生动形象,我们进行可视化操作,参考《机器学习实战》中的代码:
import matplotlib.pyplot as plt
# 定义文本框和箭头格式
decisionNode = dict(boxstyle="round4", color='#3366FF') #定义判断结点形态
leafNode = dict(boxstyle="circle", color='#FF6633') #定义叶结点形态
arrow_args = dict(arrowstyle="<-", color='g') #定义箭头
#绘制带箭头的注释
def plotNode(nodeTxt, centerPt, parentPt, nodeType):
createPlot.ax1.annotate(nodeTxt, xy=parentPt, xycoords='axes fraction',
xytext=centerPt, textcoords='axes fraction',
va="center", ha="center", bbox=nodeType, arrowprops=arrow_args)
#计算叶结点数
def getNumLeafs(myTree):
numLeafs = 0
firstStr = myTree.keys()[0]
secondDict = myTree[firstStr]
for key in secondDict.keys():
if type(secondDict[key]).__name__ == 'dict':
numLeafs += getNumLeafs(secondDict[key])
else:
numLeafs += 1
return numLeafs
#计算树的层数
def getTreeDepth(myTree):
maxDepth = 0
firstStr = myTree.keys()[0]
secondDict = myTree[firstStr]
for key in secondDict.keys():
if type(secondDict[key]).__name__ == 'dict':
thisDepth = 1 + getTreeDepth(secondDict[key])
else:
thisDepth = 1
if thisDepth > maxDepth:
maxDepth = thisDepth
return maxDepth
#在父子结点间填充文本信息
def plotMidText(cntrPt, parentPt, txtString):
xMid = (parentPt[0] - cntrPt[0]) / 2.0 + cntrPt[0]
yMid = (parentPt[1] - cntrPt[1]) / 2.0 + cntrPt[1]
createPlot.ax1.text(xMid, yMid, txtString, va="center", ha="center", rotation=30)
def plotTree(myTree, parentPt, nodeTxt):
numLeafs = getNumLeafs(myTree)
depth = getTreeDepth(myTree)
firstStr = myTree.keys()[0]
cntrPt = (plotTree.xOff + (1.0 + float(numLeafs)) / 2.0 / plotTree.totalW, plotTree.yOff)
plotMidText(cntrPt, parentPt, nodeTxt) #在父子结点间填充文本信息
plotNode(firstStr, cntrPt, parentPt, decisionNode) #绘制带箭头的注释
secondDict = myTree[firstStr]
plotTree.yOff = plotTree.yOff - 1.0 / plotTree.totalD
for key in secondDict.keys():
if type(secondDict[key]).__name__ == 'dict':
plotTree(secondDict[key], cntrPt, str(key))
else:
plotTree.xOff = plotTree.xOff + 1.0 / plotTree.totalW
plotNode(secondDict[key], (plotTree.xOff, plotTree.yOff), cntrPt, leafNode)
plotMidText((plotTree.xOff, plotTree.yOff), cntrPt, str(key))
plotTree.yOff = plotTree.yOff + 1.0 / plotTree.totalD
def createPlot(inTree):
fig = plt.figure(1, facecolor='white')
fig.clf()
axprops = dict(xticks=[], yticks=[])
createPlot.ax1 = plt.subplot(111, frameon=False, **axprops)
plotTree.totalW = float(getNumLeafs(inTree))
plotTree.totalD = float(getTreeDepth(inTree))
plotTree.xOff = -0.5 / plotTree.totalW;
plotTree.yOff = 1.0;
plotTree(inTree, (0.5, 1.0), '')
plt.show()完整调用:
from pylab import *
mpl.rcParams['font.sans-serif'] = ['SimHei'] # 指定默认字体
mpl.rcParams['axes.unicode_minus'] = False # 解决保存图像时负号'-'显示为方块的问题
##################################
# 测试决策树的构建
myDat, labels = createDataSet()
myTree = createTree(myDat, labels)
# 绘制决策树
import treePlotter
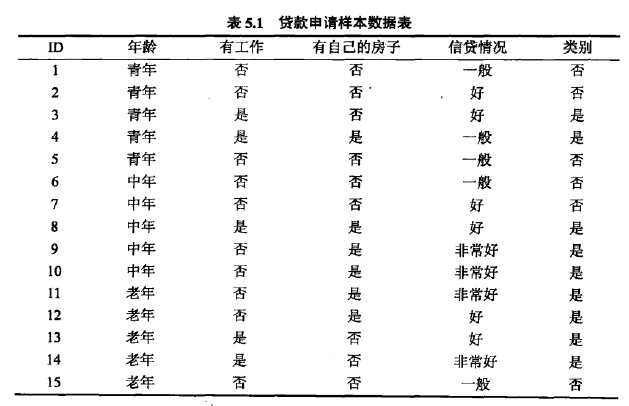
treePlotter.createPlot(myTree)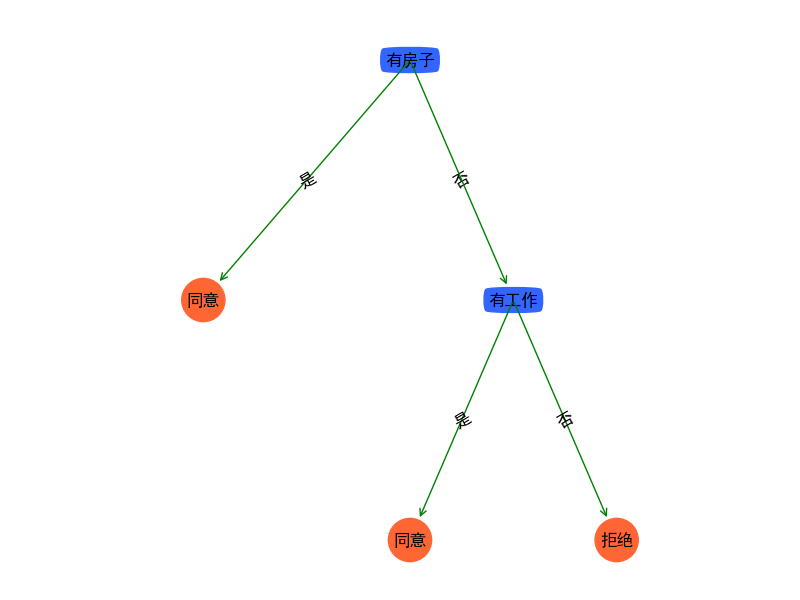
由图可以看出,银行在信贷决策上,只要判断有无房子和有无工作就能使得数据样本不确定度降至最低,而其他的冗余特征就可以不去考虑了。
在上述代码中我们使用了信息增益的计算方法,在前文中也叙述到单纯的用条件熵也是可以得到同样的结果,为了验证该想法,我们重新编写一个createTree中的函数指针chooseBestFeatureToSplitFunc。
def noInformationGainToSplitByID3(dataSet):
"""
不使用信息增益概念,而是直接判断条件熵的大小
"""
numFeatures = len(dataSet[0]) -1
bestConditionEntropy = 1.0
bestFeature =-1
for i in range(numFeatures):
featList = [example[i] for example in dataSet]
uniqueVals = set(featList)
conditionEntropy = calcConditionalEntropy(dataSet,i,featList,uniqueVals)
if (conditionEntropy < bestConditionEntropy):
bestConditionEntropy = conditionEntropy
bestFeature =i
return bestFeature
# 决策树的生成改为
dataSet,labels = createDataSet()
myTree = createTree(dataSet,labels,noInformationGainToSplitByID3)根据可视化的结果,我们发现两者算出的决策树是等价的。
决策树
C4.5算法
重新回到银行贷款问题,我们现在在数据中考虑一种极端的情况,即把ID考虑进去,由此在python中数据变成了如下形式:
def createDataSet():
"""
创建数据集
"""
dataSet = [[u'1',u'青年', u'否', u'否', u'一般', u'拒绝'],
[u'2',u'青年', u'否', u'否', u'好', u'拒绝'],
[u'3',u'青年', u'是', u'否', u'好', u'同意'],
[u'4',u'青年', u'是', u'是', u'一般', u'同意'],
[u'5',u'青年', u'否', u'否', u'一般', u'拒绝'],
[u'6',u'中年', u'否', u'否', u'一般', u'拒绝'],
[u'7',u'中年', u'否', u'否', u'好', u'拒绝'],
[u'8',u'中年', u'是', u'是', u'好', u'同意'],
[u'9',u'中年', u'否', u'是', u'非常好', u'同意'],
[u'10',u'中年', u'否', u'是', u'非常好', u'同意'],
[u'11',u'老年', u'否', u'是', u'非常好', u'同意'],
[u'12',u'老年', u'否', u'是', u'好', u'同意'],
[u'13',u'老年', u'是', u'否', u'好', u'同意'],
[u'14',u'老年', u'是', u'否', u'非常好', u'同意'],
[u'15',u'老年', u'否', u'否', u'一般', u'拒绝'],
]
labels = [u'ID',u'年龄', u'有工作', u'有房子', u'信贷情况']
# 返回数据集和每个维度的名称
return dataSet, labels在数据集中增加了特征属性ID,且该属性的类别针对每一条数据都是唯一的,那么这样的数据集,我们能生成什么样的决策树呢?程序经过运行后,得到如下图所示:
决策树的根节点直接就为ID属性,决策树根据ID来判断是否可以借贷。乍一看数据完完全全拟合了所有情况,且树的层级最低,分类速度很快。但它却不符合真正的模型。是什么样的内在逻辑影响了这种决策树的构建是非现实的?
决策树的本质是什么?在没有ID属性之前,我们已经构造了一颗符合现实模型的决策树,但有没有思考过,决策结点到子结点的连接边所代表什么样的含义?一个概率?还是一个标签?可视化时,我们标注的是特征属性的标签,如有没有房子的结点上衍生出去的两条边分别表示是和否,什么意思呢?有房 = 同意贷款,无房 = 未能准确分类,判断的标准是我们的条件概率,即条件概率决定了等式的右边是什么!所以决策树的本质在于统计,如有房的情况下100%的数据样本都是可以贷款的,那么我们就可以认为有房即表示为同意贷款。统计的核心概念是什么?需要大量的数据样本才能表达一种准确性吧,举个生活中常见的例子,你投掷一枚硬币,结果正面朝上,你就跟我说,你看正面朝上的概率是100%,呵呵,有生活常识的人都知道,反正我是不信的,为什么?一次投掷得出的答案能代表统计的结果?显然不能。
了解了决策树的本质在于统计,那么我们在回过头来看看上述问题,我们便能想明白了。假如我们这里不以ID作为我们特征向量中的一维,因为这实在太不符合现实了,我们在特征向量中加入工资属性,为了数据能够表达C4.5的思想,我们人为对数据进行模拟。在数据集中添加工资收入情况,python中数据集如下
def createDataSet():
"""
创建数据集
"""
dataSet = [[u'1000',u'青年', u'否', u'否', u'一般', u'拒绝'],
[u'2000',u'青年', u'否', u'否', u'好', u'拒绝'],
[u'7000',u'青年', u'是', u'否', u'好', u'同意'],
[u'7100',u'青年', u'是', u'是', u'一般', u'同意'],
[u'3000',u'青年', u'否', u'否', u'一般', u'拒绝'],
[u'3500',u'中年', u'否', u'否', u'一般', u'拒绝'],
[u'3600',u'中年', u'否', u'否', u'好', u'拒绝'],
[u'8000',u'中年', u'是', u'是', u'好', u'同意'],
[u'9000',u'中年', u'否', u'是', u'非常好', u'同意'],
[u'9200',u'中年', u'否', u'是', u'非常好', u'同意'],
[u'8600',u'老年', u'否', u'是', u'非常好', u'同意'],
[u'7800',u'老年', u'否', u'是', u'好', u'同意'],
[u'10000',u'老年', u'是', u'否', u'好', u'同意'],
[u'6500',u'老年', u'是', u'否', u'非常好', u'同意'],
[u'3000',u'老年', u'否', u'否', u'一般', u'拒绝'],
]
labels = [u'工资',u'年龄', u'有工作', u'有房子', u'信贷情况']
# 返回数据集和每个维度的名称
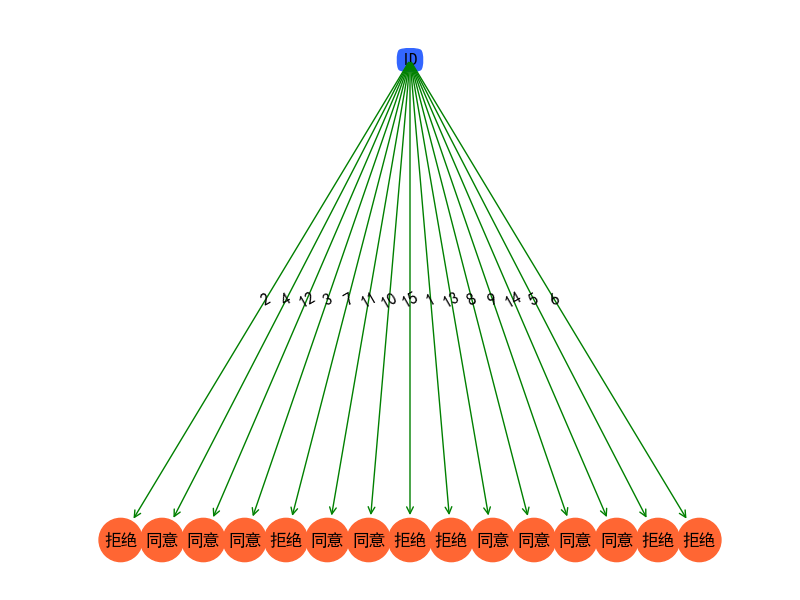
return dataSet, labels加入工资属性后,决策树构建如下:

这里我们故意让数据分散,为的就是阐述特征属性标签并非越多越好。且为了解释决策树的另外一个本质在于特征属性聚类(基于统计衍生出来的本质之二)。随着数据量的增大,我们可以假定工资属性是连续的。标签变得连续所带来的一个结果就是,一个萝卜一个坑。也就是类别标签拒绝和同意都能找到与之对应的薪资从而绑定在了一起,俗称一一绑定。刚才我们说了什么,对于每一种薪资我们只有一条数据与之绑定,那岂不是每种薪资上的条件概率为100%了,一条数据显然不能表述统计意义上的准确性。虽然不确定度降为最低,但我们却抹杀了决策树最本源的意义,基于大量数据的统计。
当然连续型的特征标签还带了另外一个问题,在对测试样本数据进行预测时,如果输入的特征属性中,没有该标签,如输入薪资水平20000元,那么决策树该怎么预测呢?所以从另外一方面,也告诉我们,特征标签是需要做聚类的。聚类有两个好处,第一把连续型变量映射到有限个数的集合当中去,预测时,方便找寻到自己所归属的那个集合元素。第二,聚类所带来的最大好处就是,在某一个类群下,数据集得到大量积累,从而使得统计的准确性增加,增加决策树的可信度。
因此对于加入了薪资属性的数据集,我们可以求得统计样本中的平均薪资,并且聚类成两个标签,即加入特征属性是否大于平均薪资,特征标签为是和否。对数据进行预处理后,我们再使用ID3,相信就不会出现这种极端的情况了。什么,我们不是要介绍C4.5算法嘛,怎么跑去优化数据集去了。好了,假设我们对数据集不做任何处理,或者本身数据集的特征标签就应该这么多,那应该怎么办呢?
这就需要借助数学公式的定义了,在介绍ID3算法时,我们定义了条件熵,并且只要找到最小的条件熵 即可。我们先来看看条件熵最小可以有哪几种情况。我们简单归为两种情况:第一,特征标签个数少的情况下,每个标签下的类别是唯一的,那么不确定即为0;第二,特征标签个数巨多情况下,导致每个标签下只有唯一的一个类别(极端情况下),不确定度也为0。C4.5算法的本质就在于区分这两种情况。显然,我们需要能够找到映射 来区分这两者。映射 可以随着标签个数增加或减少,whatever,只要你最终的数学公式能够区分 运算后的结果即可。书中直接给出映射关系函数为 ,n是特征A取值的个数。别问我他是怎么知道的!因为这实在令人难以琢磨,或许刚好由此导出了信息熵,所以沿用信息熵的概念,找到这样的映射吧。
是递增还是递减?这个非常关键,因为这决定了最终的数学形式。可仔细看看这函数,还是令人难过的,它并非简单的在某一维度上的点集合构成的函数,它是一组函数族,在它们自己的维度中,有着各自的表现形式。决定它的取值有两个因素,在标签数给定的情况下,各标签占总样本的个数以及标签个数。在这个函数中,我们假定各标签是均匀分布的,即概率本身并不影响 的取值,由此随着标签个数的增加 ,N为标签的取值情况。简化后的函数容易看出是单调递增的函数。也就是说,你的特征标签越多样化,该函数值就越大。
接下来,我们就要开始构建我们的数学公式了,由前文我们已经知道,条件熵极小的情况下,可能有两种情况,一种是真正的表达了聚类和类别标签的实际联系,而另一种则是我们需要揪出来的非实际表达。我们可以构造 表达式,即前者均出现极小的情况下,由于 递增,所以标签多样的特征一定大于特征非多样的情况。即我们做到了很好的区分了,可这个式子有什么问题嘛?
如果不确定度为0的情况该怎么办?因为0乘以任何数还是0,即饶了一圈,针对一些极端情况,我们又无法区分了!这时候我便想起了信息增益的定义了,即
求条件熵的极小问题转化为求信息增益的极大,这就绕开了0这种拥有特殊性质的数字了。因为最特殊的情况下, ,此项为非零项,可以很好的规避0的特殊性。由于函数转为寻找极大条件下的特征,因此我们不能再乘以 ,相反的我们是要除以 。
好了,现在我们可以回归书中的定义了,为什么定义了信息增益比,以及它的形成过程是什么,主要归结于决策树的统计和聚类两性质,而数学公式只是为了能够形式化的去区分由此产生的不同。尽可能的把两者的区别用数学公式表达出来后,我们就能够通过求解数学问题来解决特征选取问题了。
信息增益比
以信息增益作为划分训练数据集的特征,存在偏向于选择取值较多特征的问题。使用信息增益比可以对这一问题进行校正。这是特征选择的另一准则。
特征A对训练数据集D的信息增益比
定义为其信息增益
与训练数据集D关于特征A的值的熵
之比,即
其中, ,n是特征A的取值的个数。
算法(C4.5)的生成算法
输入:训练数据集D,特征集A,阈值
输出:决策树T
(1) 若D中所有实例属于同一类 ,则T为单结点树,并将类 作为该结点的类标记,返回T;
(2) 若 ,则T为单结点树,并将D中实例数最大的类 作为该结点的类标记,返回T;
(3) 否则,计算A中各特征对D的信息增益比,选择信息增益比最大的特征 ;
(4) 如果 的信息增益小于阈值 ,则置T为单结点树,并将D中实例数最大的类 作为该结点的类标记,返回T;
(5) 否则,对 的每一个可能值 ,依 将D分割为若干非空子集 ,将 中实例数最大的类作为标记,构建子结点,由结点及其子结点构成树T,返回T;
(6) 对第i个子子结点,以 为训练集,以 为特征集,递归地调用步(1)~(5),得到子树 ,返回 ;
Code Time Again
C4.5生成算法
我们沿用拥有薪资属性的数据集,即python中数据集为:
def createDataSet():
"""
创建数据集
"""
dataSet = [[u'1000',u'青年', u'否', u'否', u'一般', u'拒绝'],
[u'2000',u'青年', u'否', u'否', u'好', u'拒绝'],
[u'7000',u'青年', u'是', u'否', u'好', u'同意'],
[u'7100',u'青年', u'是', u'是', u'一般', u'同意'],
[u'3000',u'青年', u'否', u'否', u'一般', u'拒绝'],
[u'3500',u'中年', u'否', u'否', u'一般', u'拒绝'],
[u'3600',u'中年', u'否', u'否', u'好', u'拒绝'],
[u'8000',u'中年', u'是', u'是', u'好', u'同意'],
[u'9000',u'中年', u'否', u'是', u'非常好', u'同意'],
[u'9200',u'中年', u'否', u'是', u'非常好', u'同意'],
[u'8600',u'老年', u'否', u'是', u'非常好', u'同意'],
[u'7800',u'老年', u'否', u'是', u'好', u'同意'],
[u'10000',u'老年', u'是', u'否', u'好', u'同意'],
[u'6500',u'老年', u'是', u'否', u'非常好', u'同意'],
[u'3000',u'老年', u'否', u'否', u'一般', u'拒绝'],
]
labels = [u'工资',u'年龄', u'有工作', u'有房子', u'信贷情况']
# 返回数据集和每个维度的名称
return dataSet, labels
ID3算法已经实现了决策树的基本骨架,因此只需要重新编写一个createTree中的函数指针chooseBestFeatureToSplitFunc即可。因此在原有代码的基础上添加如下:
def calcInformationGainRate(dataSet,baseEntropy,i):
"""
计算信息增益比
:param dataSet: 数据集
:param baseEntropy: 数据集中Y的信息熵
:param i: 特征维度i
:return: 特征i对数据集的信息增益g(dataSet|X_i)
"""
numEntries = len(dataSet)
labelCounts = {}
for featVec in dataSet:
currentLabel = featVec[i]
if currentLabel not in labelCounts.keys(): labelCounts[currentLabel] =0
labelCounts[currentLabel] +=1
shannonEnt = 0.0
for key in labelCounts:
prob = float(labelCounts[key]) / numEntries
shannonEnt -= prob * log(prob,2)
return calcInformationGain(dataSet,baseEntropy,i) / shannonEnt
def chooseBestFeatureToSplitByC45(dataSet):
"""
选择最好的数据集划分方式
:param dataSet:
:return:
"""
numFeatures = len(dataSet[0]) -1 # 最后一列是分类
baseEntropy = calcShannonEnt(dataSet)
bestInfoGainRate =0.0
bestFeature = -1
for i in range(numFeatures):
infoGainRate = calcInformationGainRate(dataSet,baseEntropy,i)
if (infoGainRate > bestInfoGainRate):
bestInfoGainRate = infoGainRate
bestFeature = i
return bestFeature
# 测试决策树的构建
dataSet,labels = createDataSet()
myTree = createTree(dataSet,labels,chooseBestFeatureToSplitByC45)可视化决策树:
由上图可以看出,并非薪资属性作为首选特征,而是又回到了有房子这个特征属性上了,但在子结点中我们又发现了同样的问题,可见C4.5虽然能够解决一些极端的情况,但由于数据没有进行很好的预处理,所以在子结点中还是导致了相同的问题。这在理论上也是能解释的,只能说,虽然加了校正,但其他属性的不确定度还是不及薪资这种特殊情况,导致在决策树构建过程中,它占优。
PS:更新于2016.12.6
出现上图的原因,在于之前写决策树生成递归算法时,递归构造出现了一个小bug。即在递归构造时,并没有指定具体使用ID3orC4.5方法。把createTree中的代码,如下
myTree[bestFeatLabel][value] = createTree(splitDataSet(dataSet,bestFeat,value),subLabels)改成
myTree[bestFeatLabel][value] = createTree(splitDataSet(dataSet,bestFeat,value),subLabels,chooseBestFeatureToSplitFunc)重新运行实验发现,薪资特征被剔除了,验证了C4.5的效果。
未完待续
总的来说,决策树使用了ID3算法和C4.5算法,本文详细阐述了这些算法的原理以及如何一步步构建决策树的过程,在学习过程中,不断深入挖掘关键点,从而能够尽量抓住问题的本质。当然,也有很多点未能阐述明白,如有不当之处,请不惜指正。
还遗留了决策树的一部分问题,即决策树学习与朴素贝叶斯学习比较,决策树的剪枝问题和经典的CART算法,将在后续更新。
参考文献
- 能否尽量通俗地解释什么叫做熵?
- Stirling公式
- 宇宙的奇迹:时间之箭 BBC
- 李航. 统计学习方法[M]. 北京:清华大学出版社,2012
- Peter Harrington. Machine Learning in Action[M]. 北京:人民邮电出版社,2013