(作者:陈玓玏)
决策树算法在实际建模中应用非常广泛,也是很多热门机器学习算法的基础,那决策树的本质是什么?是将特征空间逐级划分,如下图过程所示:
图示就是每次都找不同的切分点,将样本空间逐渐进行细分,最后把属于同一类的空间进行合并,就形成了决策边界,树的层次越深,决策边界的切分就越细,区分越准确,同时也越有可能产生过拟合。
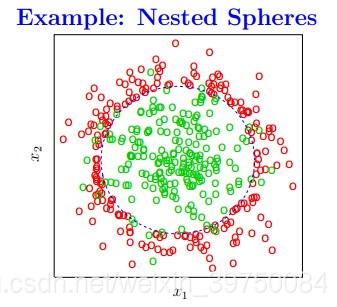
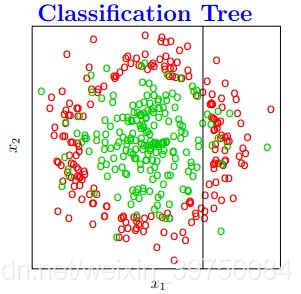
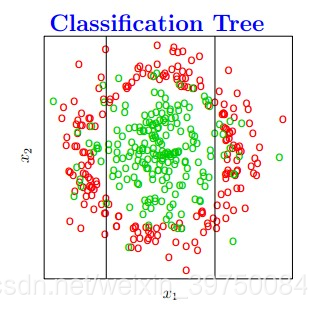
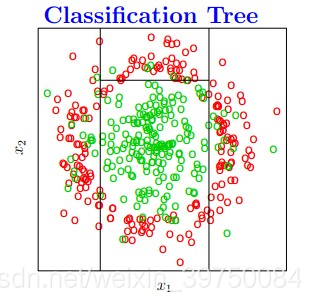
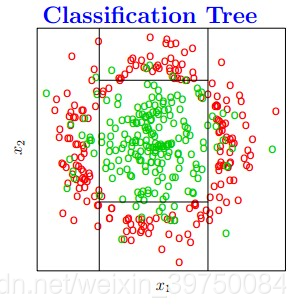
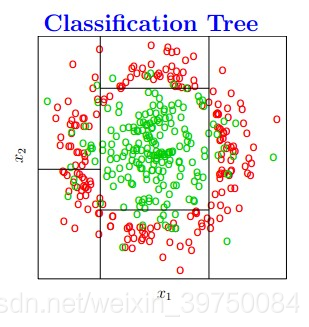
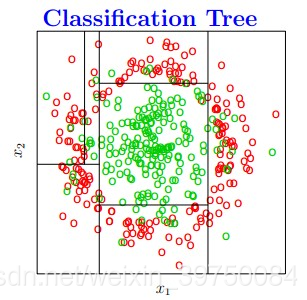
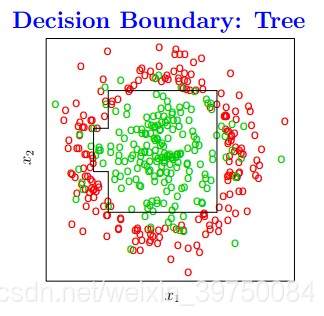
这也就是说,决策树最重要的一件事情就是:怎么找切分点?
基本的决策树算法有三类,按时间顺序分别是:ID3、C4.5、CART。前两个是分类树,最后一个是回归树,我们一个一个来看。
1. ID3
1.1 算法流程
ID3算法在1986年由Quinlan提出,假设输入数据集为
共
个样本,每个样本有
个特征,特征集合为
,由
表示第
个样本的第
个特征,并给定选取切分点的阈值为
其算法流程如下:
1)如果所有样本属于同一类,则生成单节点决策树即可;
2)如果所有样本的特征数为0,则生成单节点决策树,其分类选取出现频数最高的类为其分类即可;
3)如果以上两种情况都未出现,那么首要任务就是要选取切分点,逐个计算每个特征的信息增益,信息增益最大的则为特征
,其增益记为
(公式什么的马上端上来)。
4)如果
小于
,则生成单节点,并取当前样本空间中出现频数最高的类为其分类;
5)如果
大于等于
,则对于特征
的每个可取值
都有一个对应的样本子集
,表示当前样本空间中所有样本中特征
的值等于
的样本集合,如果特征有
个可取值,将会生成
个子节点,每个子节点的分类为
中频数最高的类别。
6)从上一个节点往下继续递归地生成子节点,进入下一个节点的样本空间的样本为
中的节点,参与计算的特征是之前没有用过的特征,也就是
(集合差集)。
从上面的算法过程我们可以看出,其本质就是在不停地选择当前未被选中的特征中,最为重要的特征作为划分样本空间的依据,当信息增益达不到阈值或没有可用的样本了,决策树的递归过程也就结束了。
1.2 信息增益计算
上面的算法流程中,我们可以看出,ID3算法中构建决策树时最重要的就是如何计算信息增益来选择特征。信息增益是基于熵的概念来计算的,熵在信息论中表示随机变量不确定性的度量,设X是一个取有限个值的离散随机变量(如果是连续变量,其熵的计算相对复杂,需要用到积分,所以如果是连续变量,要么就使用CART树来实现分类,要么就将特征做离散化处理),其概率分布为
,那么这个变量的熵为:
基于熵的计算公式,我们得到信息增益(本质上就是信息论中的互信息,表示给定特征A的情况下,信息的混乱程度减少多少)计算方法如下:
这里的概率分布是通过先验概率来表示的,也就是通过对已有样本的简单统计给出数据集的分布,其实际就是一种极大似然估计,比如经验熵中,第
类样本出现的概率用:
类样本的个数/整个数据集
中总样本个数来表示。

2. C4.5
ID3算法有两个明显的缺点:
1)使用信息增益进行特征选择,但信息增益是一个绝对的概念,与训练集本身的离散程度有很大的关系,当训练集本身离散程度很高时,其可改进的空间更大,能够获得的信息增益更大,反之更小,这会导致很难在开始训练前就确定一个较为合理的阈值
。
2)需要一直进行到没有特征可选为止,特征很多时树深度可能很深,无关紧要的特征也会被精确分析,从而导致过拟合。
因此,C4.5算法做出了两个改进。
2.1 使用信息增益比
使用信息增益比进行特征选择,其公式为:
通过这样的归一化之后,我们能够校正scale上的偏差,方便选择一个较为稳定的阈值,不需要受到数据集本身的影响。
2.2 剪枝
既然知道了过拟合产生的原因是为了精确拟合训练集而形成了过于复杂的模型,那么剪枝就是要控制模型的复杂度,通过以下正则化的损失函数公式来实现:
公式中的
项具体公式如下:
公式中
表示第
个叶子节点中第
类样本的个数,
表示第
个叶子节点中所有样本个数。具体的剪枝方法是先根据公式
计算出每个节点的经验熵,在剪枝过程中都可能用到的。接下来从下至上进行剪枝,计算剪枝前的损失函数
,计算剪枝后(将之前的两个叶子节点+它们的父节点统一替换成一个叶子节点)的损失函数
,如果剪枝后损失函数更小,则执行剪枝,并且递归地执行这个过程直到无须剪枝。
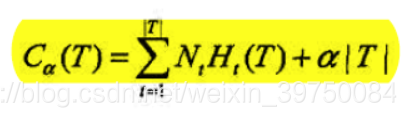
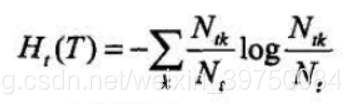
这里有一个很有意思的问题,为什么用这个损失函数可以判断是否需要剪枝?还是那句话,主要是要在控制树的复杂度和预测的精确度之间做一个权衡。仔细看损失函数,第一项其实是叶子节点经验熵的集合,如果将其系数做一下归一化,那么剪枝前后的损失函数第一项之差应当是接近信息增益的,也就是说,第一项用来保证我们的分裂效果不会被埋没。那么第二项的作用就是控制树的复杂度,你这么想,如果 取一个很大的值,比如 ,那么减去一条最小的枝,将会减少一个叶子节点,但第一项很难增加 那么多,那么基本上很多的枝都会被剪掉,但同时精确度也会骤然下降。
因此,选择一个合适的正则化参数是关键。
3. CART
不同于前两种算法预测结果为分类结果,CART的预测结果为概率值。并且改进了前两种算法中的一个缺点:使用信息增益或信息增益比时,可选值多的特征往往有更高的信息增益,这个可以自己做一下实验。所以在CART树中,不再采用信息增益或信息增益比,而是在做回归时采用平方误差最小化准则,在做分类时采用基尼指数最小化准则。
3.1 CART回归树
对于输入数据集
,假设最终形成的回归树有
个叶子节点,每一个的输出结果是
,则最终的最小平方误差代价函数应该为:
其中函数
表示当样本属于第
个叶子节点时,其CART树的输出值为
。为了达到这个目标,我们需要遍历每个样本的每个特征值,要让每一次的切分损失都是最小的,而在CART树中使用的是二叉树,因此,每次切分的目标如下:
表示用来切分的特征,
表示切分点的第
个特征的值,
表示所有第
个特征的值小于等于
的样本点的代表值,
表示所有第
个特征的值大于
的样本点的代表值。因为
和
的选择也要符合区间内的最小平方误差准则,因此
和
取区间所有特征的真实值的均值。即:
重复地执行这个找切分点的步骤,直到建立起整棵树。
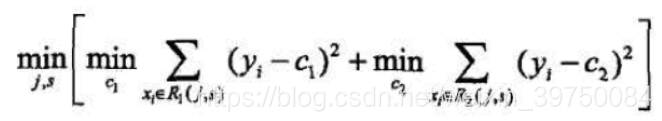

3.2 分类树
1)对于训练集
中的每个特征
,遍历特征每个可能的取值
,根据特征是否满足
将样本分为
和
两个区间,通过以下公式计算基尼指数:
基尼指数基本公式:
选择基尼指数最小的特征
及切分点
,根据它们将样本分为两个区间,分别放入两个子节点中,递归调用这个过程直到叶子节点中样本个数少于阈值或基尼指数小于阈值。

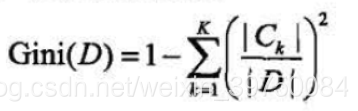
3.3 CART树剪枝
CART树的剪枝其实没有弄得很懂。

4. ID3、C4.5和CART的区别
总结有不足之处请指出,谢谢!
1)ID3和C4.5不是二叉树,但CART是;
2)ID3和C4.5不需要遍历所有的点,但CART需要;
3)ID3和C4.5及CART分类树适用于标称属性,CART回归树适用于数值型,因为ID3和C4.5计算信息增益时是以每个标称属性的枚举值作为分割点来求信息增益或信息增益比的,而CART分类树是以特征是否等于来划分区间的,只有CART回归树是通过大小比较来划分区间的;
4)ID3和C4.5父节点与子节点选择的特征是不同的,而CART可以是相同的;
5)ID3和C4.5只能用于分类,CART可以用于分类及回归;
6)ID3和C4.5及CART分类树的预测结果为类别,CART回归树分类结果为概率值;
7)C4.5的剪枝是自下而上进行的,但CART树的剪枝不是。