1. 概述
上一篇日志中,我们介绍了最简单的分类回归算法 – K 近邻算法。
k 近邻算法
本篇日志我们来介绍构建专家系统和数据挖掘最常用的算法 – 决策树。
2. 决策树
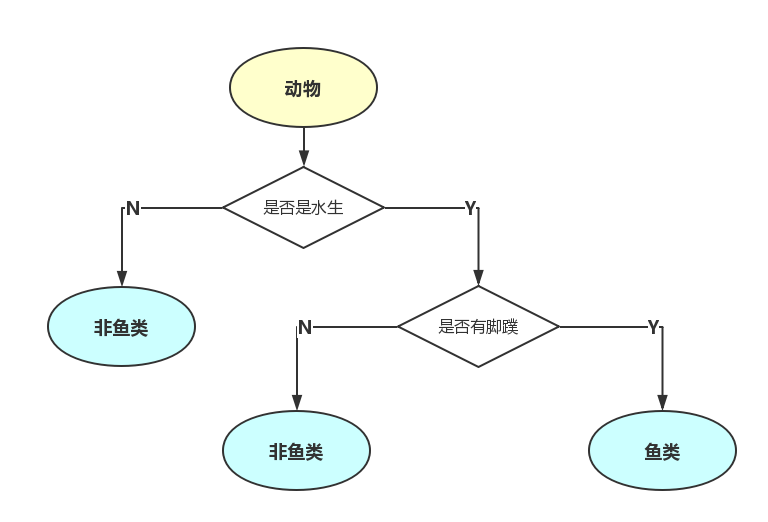
在系统流程图中,我们常常会构建决策树,例如上面的例子是一个简单的用于动物分类的专家系统,是一个典型的树状结构。
决策树通常用来处理数值型或标称型数据,它用来预测对象属性与对象值之间的关系。
2.1. 决策树的构成
决策树由结点(node)和有向边(directed edge)组成。
节点分为:
- 内部节点(internal node) – 存储用于决策的特征或属性
- 叶子节点(leaf node) – 存储判断结果类
3. 决策树算法的优缺点
3.1. 优点
- 计算复杂度不高
- 输出结果易于理解
- 中间值缺失不敏感
- 可以处理不相关特征的数据
3.2. 缺点
决策树算法最大的缺点是可能存在过度匹配的问题。
4. 如何构造决策树 – ID3 算法
ID3 算法是构建决策树最常用的算法之一。
ID3 算法即“Iterative Dichotomiser III”。
他是基于“奥卡姆剃刀原理”指导思想的算法,也就是用尽量少的信息做更多的事。
他认为越是小型的决策树越优于大的决策树,所以,ID3 算法是以启发式的方式构建尽量小的决策树。
那么,如何定义决策树的大小呢?
5. 信息熵
“熵”最早起源于物理学,用来度量一个热力学系统的无序程度,1948年,香农引入了信息熵,将其定义为离散随机事件出现的概率。
一个系统越是有序,信息熵就越低,反之一个系统越是混乱,它的信息熵就越高。
假如一个随机变量 X 的取值为 X={x1, x2, x3 … xn},他们出现的概率分别是 {p1, p2, p3 … pn},那么 X 的熵定义为:
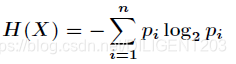
也就是说,一个变量的变化情况可能越多,那么它携带的信息量就越大,系统也就越混乱。
5.1. 信息熵的计算
下面是一个实际的例子,根据天气情况决定是否打高尔夫:
是否要打高尔夫?
| Day | Temperatrue | Outlook | Humidity | Windy | PlayGolf? |
|---|---|---|---|---|---|
| 07-05 | hot | sunny | high | false | no |
| 07-06 | hot | sunny | high | true | no |
| 07-07 | hot | overcast | high | false | yes |
| 07-09 | cool | rain | normal | false | yes |
| 07-10 | cool | overcast | normal | true | yes |
| 07-12 | mild | sunny | high | false | no |
| 07-14 | cool | sunny | normal | false | yes |
| 07-15 | mild | rain | normal | false | yes |
| 07-20 | mild | sunny | normal | true | yes |
| 07-21 | mild | overcast | high | true | yes |
| 07-22 | hot | overcast | normal | false | yes |
| 07-23 | mild | sunny | high | true | no |
| 07-26 | cool | sunny | normal | true | no |
| 07-30 | mild | sunny | high | false | yes |
一共 14 个样本,包括 9 个 yes 和 5 个 no。
- 系统的熵
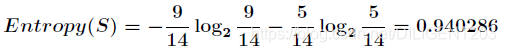
- 选定指标后计算熵
如果我们用 outlook 指标来分类,那么可以分成如图所示的三部分:

各个分支的信息熵:
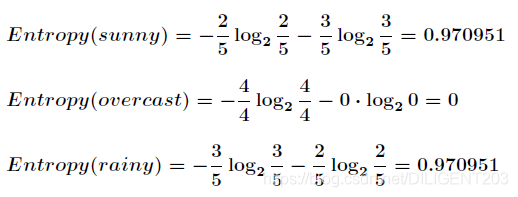
- 选定指标后系统的条件熵
选定指标以后,各个分支的熵的加权和就是整个系统的条件熵:
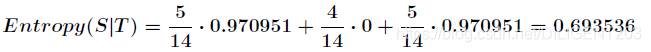
6. 信息增益
信息增益指的是从分支划分前到分支划分后,系统熵的差异:
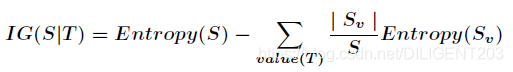
- S – 全部样本集合
- value(T) – 属性 T 所有取值的集合
- v – T 其中的一个属性
- Sv – S 中属性 T 值为 v 的样例集合
- |Sv| – Sv 中的样本数
因此,上面例子中选定指标后信息增益为:
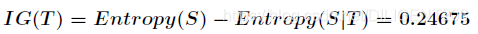
7. ID3 算法的实现
基于上面的计算,我们有了用来衡量系统复杂度的指标 – 信息熵,以及用指标划分系统后的熵差 – 信息增益。
根据 ID3 算法的核心思想,只要在每次决策树非叶子节点划分之前,计算出每一个属性所带来的信息增益,选择最大信息增益的属性来划分,就可以让本次划分更优,因此整个 ID3 实际上是一个贪心算法。
7.1. 代码实现
下面是 ID3 的 python 代码实现:
# -*- coding: UTF-8 -*-
from math import log
def calcShannonEnt(dataSet):
"""
计算给定数据集的信息熵(香农熵)
"""
numEntires = len(dataSet)
""" 保存每个标签出现的次数 """
labelCounts = {}
""" 每个所有特征向量 """
for featVec in dataSet:
currentLabel = featVec[-1] # 提取标签信息
if currentLabel not in labelCounts.keys():
labelCounts[currentLabel] = 0
labelCounts[currentLabel] += 1
# 信息熵
shannonEnt = 0.0
for key in labelCounts:
# 选择该标签的概率
prob = float(labelCounts[key]) / numEntires
# 计算熵
shannonEnt -= prob * log(prob, 2)
return shannonEnt
def createDataSet():
"""
创建测试数据集
"""
dataSet = [[0, 0, 0, 0, 'no'], # 数据集
[0, 0, 0, 1, 'no'],
[0, 1, 0, 1, 'yes'],
[0, 1, 1, 0, 'yes'],
[0, 0, 0, 0, 'no'],
[1, 0, 0, 0, 'no'],
[1, 0, 0, 1, 'no'],
[1, 1, 1, 1, 'yes'],
[1, 0, 1, 2, 'yes'],
[1, 0, 1, 2, 'yes'],
[2, 0, 1, 2, 'yes'],
[2, 0, 1, 1, 'yes'],
[2, 1, 0, 1, 'yes'],
[2, 1, 0, 2, 'yes'],
[2, 0, 0, 0, 'no']]
labels = ['overlook', 'temperature', 'humidity', 'windy'] # 分类属性
return dataSet, labels
def splitDataSet(dataSet, axis, value):
"""
从 dataSet 中取出 axis 特征
"""
retDataSet = []
for featVec in dataSet:
if featVec[axis] == value:
""" 去掉axis特征 """
reducedFeatVec = featVec[:axis]
reducedFeatVec.extend(featVec[axis + 1:])
retDataSet.append(reducedFeatVec)
return retDataSet
def chooseBestFeatureToSplit(dataSet):
"""
选择最优特征
"""
numFeatures = len(dataSet[0]) - 1
""" 计算数据集的信息熵 """
baseEntropy = calcShannonEnt(dataSet)
# 信息增益
bestInfoGain = 0.0
# 最优特征的索引值
bestFeature = -1
for i in range(numFeatures):
# 获取dataSet的第i个所有特征
featList = [example[i] for example in dataSet]
uniqueVals = set(featList) # 去重
# 条件熵
newEntropy = 0.0
for value in uniqueVals:
""" 计算信息增益 """
# subDataSet划分后的子集
subDataSet = splitDataSet(dataSet, i, value)
# 计算子集的概率
prob = len(subDataSet) / float(len(dataSet))
""" 计算经验条件熵 """
newEntropy += prob * calcShannonEnt(subDataSet)
""" 计算信息增益 """
infoGain = baseEntropy - newEntropy
print("第%d个特征的增益为%.3f" % (i, infoGain))
""" 获取最大信息增益 """
if (infoGain > bestInfoGain):
bestInfoGain = infoGain
bestFeature = i
return bestFeature
if __name__ == '__main__':
dataSet, features = createDataSet()
print("最优划分特征为: " + features[chooseBestFeatureToSplit(dataSet)])
7.2. 运行结果

8. C4.5 算法
C4.5 算法是 ID3 算法的扩展,C4.5生成的决策树可以用于分类,因此,C4.5通常被称为统计分类器。
C4.5 对 ID3 算法最大的改进就是在获取最优分类特征的时候,将 ID3 所使用的信息增益换成了信息增益比。
我们在上面的例子中,没有使用表中的 Day 属性作为特征参与计算,如果我们把这个特征引入进来参与计算会怎么样呢?
显然,H(D|Day)=0,g(D,Day)=0.9403,Day 属性是最好的分类属性,可事实上,这是没有任何意义的,因为每个结果都有一个唯一的 Day 属性,如果用 Day 属性为 root 构造决策树,决策树将形成一颗叶子数为 14,深度只有两层的树。
9. 信息增益比
造成这样的问题原因是什么呢?因为 Day 属性的可选值过多,而信息增益偏向于选择取值较多的特征。
解决办法也很简单,就是对树分支过多的情况进行惩罚。
- 信息增益比 = 惩罚参数 * 信息增益
根据熵的公式可知,特征越多,熵越大,所以,惩罚参数取熵的倒数,也就是用信息增益除以特征 A 的熵,从而抵消了特征变量的复杂程度,避免了过拟合:
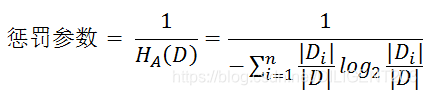
10. C4.5 的其他改进
- 处理连续和离散属性 – 为了处理连续属性,C4.5创建一个阈值,然后将列表拆分为属性值高于阈值的列表以及小于或等于阈值的列表
- 处理缺少属性值的训练数据 – C4.5允许将属性值标记为?为了失踪。丢失的属性值根本不用于增益和熵计算。
- 处理具有不同成本的属性
- 创建后修剪树 – C4.5一旦创建就会返回树中,并尝试通过用叶节点替换它们来删除无效的分支。
欢迎关注微信公众号

参考资料
Peter Harrington 《机器学习实战》。
李航 《统计学习方法》。
https://en.wikipedia.org/wiki/ID3_algorithm。
https://en.wikipedia.org/wiki/C4.5_algorithm。
https://blog.csdn.net/c406495762/article/details/75663451?utm_source=blogxgwz0。
https://blog.csdn.net/fly_time2012/article/details/70210725。
http://www.cnblogs.com/ooon/p/5643494.html。
https://blog.csdn.net/olenet/article/details/46433297。
https://www.jianshu.com/p/268c4095dbdc。
https://www.cnblogs.com/muzixi/p/6566803.html。