决策树又称为判定树,是运用于分类的一种树结构。决策树(decision tree)是一个树结构(可以是二叉树或非二叉树)。其每个非叶节点表示一个特征属性上的测试,每个分支代表这个特征属性在某个值域上的输出,而每个叶节点存放一个类别。使用决策树进行决策的过程就是从根节点开始,测试待分类项中相应的特征属性,并按照其值选择输出分支,直到到达叶子节点,将叶子节点存放的类别作为决策结果。
决策树的决策过程需要从决策树的根节点开始,待测数据与决策树中的特征节点进行比较,并按照比较结果选择选择下一比较分支,直到叶子节点作为最终的决策结果。

决策树的学习过程
- 特征选择:从训练数据的特征中选择一个特征作为当前节点的分裂标准(特征选择的标准不同产生了不同的特征决策树算法)。
- 决策树生成:根据所选特征评估标准,从上至下递归地生成子节点,直到数据集不可分则停止决策树。
- 剪枝:决策树容易过拟合,需要剪枝来缩小树的结构和规模(包括预剪枝和后剪枝)。
实现决策树的算法包括ID3、C4.5算法等。
信息增益
划分数据集的大原则是:将无序数据变得更加有序,但是各种方法都有各自的优缺点,信息论是量化处理信息的分支科学,在划分数据集前后信息发生的变化称为信息增益,获得信息增益最高的特征就是最好的选择,所以必须先学习如何计算信息增益,集合信息的度量方式称为香农熵,或者简称熵。
假设我们希望通过所给的训练数据学习一个贷款申请的决策树,用以对未来的贷款申请进行分类,即当新的客户提出贷款申请时,根据申请人的特征利用决策树决定是否批准贷款申请。特征选择就是决定用哪个特征来划分特征空间。
问题是:究竟选择哪个特征更好些?这就要求确定选择特征的准则。直观上,如果一个特征具有更好的分类能力,或者说,按照这一特征将训练数据集分割成子集,使得各个子集在当前条件下有最好的分类,那么就更应该选择这个特征。信息增益就能够很好地表示这一直观的准则。
什么是信息增益呢?
在划分数据集之前之后信息发生的变化成为信息增益,知道如何计算信息增益,我们就可以计算每个特征值划分数据集获得的信息增益,获得信息增益最高的特征就是最好的选择。
熵定义为信息的期望值,如果待分类的事物可能划分在多个类之中,则符号的信息定义为:
其中,是选择该分类的概率。
为了计算熵,我们需要计算所有类别所有可能值所包含的信息期望值,通过下式得到:![]()
其中,n 为分类数目,熵越大,随机变量的不确定性就越大。
当熵中的概率由数据估计(特别是最大似然估计)得到时,所对应的熵称为经验熵(empirical entropy)。什么叫由数据估计?比如有10个数据,一共有两个类别,A类和B类。其中有7个数据属于A类,则该A类的概率即为十分之七。其中有3个数据属于B类,则该B类的概率即为十分之三。浅显的解释就是,这概率是我们根据数据数出来的。我们定义贷款申请样本数据表中的数据为训练数据集D,则训练数据集D的经验熵为H(D),|D|表示其样本容量,及样本个数。设有K个类Ck,k = 1,2,3,···,K,|Ck|为属于类Ck的样本个数,这经验熵公式可以写为:
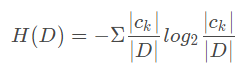
根据此公式计算经验熵H(D),分析贷款申请样本数据表中的数据。最终分类结果只有两类,即放贷和不放贷。根据表中的数据统计可知,在15个数据中,9个数据的结果为放贷,6个数据的结果为不放贷。所以数据集D的经验熵H(D)为:
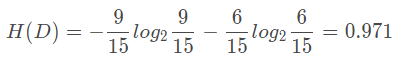
经过计算可知,数据集D的经验熵H(D)的值为0.971。
在理解信息增益之前,要明确——条件熵
信息增益表示得知特征X的信息而使得类Y的信息不确定性减少的程度。
条件熵H(Y∣X)表示在已知随机变量X的条件下随机变量Y的不确定性,随机变量X给定的条件下随机变量Y的条件熵(conditional entropy) H(Y|X),定义X给定条件下Y的条件概率分布的熵对X的数学期望:

其中,
当熵和条件熵中的概率由数据估计(特别是极大似然估计)得到时,所对应的分别为经验熵和经验条件熵,此时如果有0概率,令0log0=0 ;
信息增益:信息增益是相对于特征而言的。所以,特征A对训练数据集D的信息增益g(D,A),定义为集合D的经验熵H(D)与特征A给定条件下D的经验条件熵H(D|A)之差,即:
一般地,熵H(D)与条件熵H(D|A)之差成为互信息(mutual information)。决策树学习中的信息增益等价于训练数据集中类与特征的互信息。
信息增益值的大小相对于训练数据集而言的,并没有绝对意义,在分类问题困难时,也就是说在训练数据集经验熵大的时候,信息增益值会偏大,反之信息增益值会偏小,使用信息增益比可以对这个问题进行校正,这是特征选择的另一个标准。
信息增益比:特征A对训练数据集D的信息增益比定义为其信息增益g(D,A) 与训练数据集D 的经验熵之比:
ID3算法
ID3算法是由Ross Quinlan提出的决策树的一种算法实现,以信息论为基础,以信息熵和信息增益为衡量标准,从而实现对数据的归纳分类。ID3算法是建立在奥卡姆剃刀的基础上:越是小型的决策树越优于大的决策树(be simple简单理论)。
奥卡姆剃刀(Occam's Razor, Ockham's Razor),又称“奥坎的剃刀”,是由14世纪逻辑学家、圣方济各会修士奥卡姆的威廉(William of Occam,约1285年至1349年)提出,他在《箴言书注》2卷15题说“切勿浪费较多东西,去做‘用较少的东西,同样可以做好的事情’。简单点说,便是:be simple。
算法缺陷
ID3算法可用于划分标准称型数据,但存在一些问题:
- 没有剪枝过程,为了去除过渡数据匹配的问题,可通过裁剪合并相邻的无法产生大量信息增益的叶子节点;
- 信息增益的方法偏向选择具有大量值的属性,也就是说某个属性特征索取的不同值越多,那么越有可能作为分裂属性,这样是不合理的;
- 只可以处理离散分布的数据特征
属性选择
ID3算法的核心思想是以信息增益度量属性选择,选择分裂后信息增益最大的属性进行分裂。信息熵(entropy)是用来衡量一个随机变量出现的期望值。如果信息的不确定性越大,熵的值也就越大,出现的各种情况也就越多。
设D为用类别对训练元组进行的划分,则D的熵(entropy)表示为:
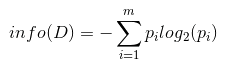
其中pi表示第i个类别在整个训练元组中出现的概率,可以用属于此类别元素的数量除以训练元组元素总数量作为估计。熵的实际意义表示是D中元组的类标号所需要的平均信息量。
现在我们假设将训练元组D按属性A进行划分,则A对D划分的期望信息为:
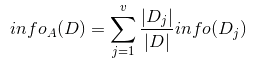
信息增益(information gain)是指信息划分前后的熵的变化,也就是说由于使用这个属性分割样例而导致的期望熵降低。也就是说,信息增益就是原有信息熵与属性划分后信息熵(需要对划分后的信息熵取期望值)的差值,具体计算法如下, 即为两者的差值:
![]()
ID3算法就是在每次需要分裂时,计算每个属性的增益率,然后选择增益率最大的属性进行分裂。下面我们继续用SNS社区中不真实账号检测的例子说明如何使用ID3算法构造决策树。为了简单起见,我们假设训练集合包含10个元素:

其中s、m和l分别表示小、中和大。设L、F、H和R表示日志密度、好友密度、是否使用真实头像和账号是否真实,下面计算各属性的信息增益。
式(1)
(这里要解释一下上式是怎么算的:
由 得,
计算的是第四列“账号是否真实”,这一列中,真实的账号有7个,不真实的账号有3个,所以用式(1)求得。
由得,
以“L日志密度”进行计算,第一列中,日志密度分为三类s、m和l。第一步先求“l”类,一共有3个(pi=0.3),“l”类对应的“账号是否真实”全为“yes”,则![]() ;第2步求“m”类,一共有4个(pi=0.4),“m”类对应的“账号是否真实”,3个为“yes”,一个为“no”,则
;第2步求“m”类,一共有4个(pi=0.4),“m”类对应的“账号是否真实”,3个为“yes”,一个为“no”,则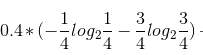 ;依次类推求“s”类。
;依次类推求“s”类。
)
因此日志密度的信息增益是0.276。
用同样方法得到H和F的信息增益分别为0.033和0.553。
因为F具有最大的信息增益,所以第一次分裂选择F为分裂属性,分裂后的结果如下图表示:

在上图的基础上,再递归使用这个方法计算子节点的分裂属性,最终就可以得到整个决策树。
上面为了简便,将特征属性离散化了,其实日志密度和好友密度都是连续的属性。对于特征属性为连续值,可以如此使用ID3算法:
先将D中元素按照特征属性排序,则每两个相邻元素的中间点可以看做潜在分裂点,从第一个潜在分裂点开始,分裂D并计算两个集合的期望信息,具有最小期望信息的点称为这个属性的最佳分裂点,其信息期望作为此属性的信息期望。
注意:该算法使用了贪婪搜索,从不回溯重新考虑之前的选择情况。
from:http://www.cnblogs.com/leoo2sk/archive/2010/09/19/decision-tree.html
from:https://blog.csdn.net/jiaoyangwm/article/details/79525237#32__389
决策树的构造
决策树学习的算法通常是一个递归地选择最优特征,并根据该特征对训练数据进行分割,使得各个子数据集有一个最好的分类的过程。这一过程对应着对特征空间的划分,也对应着决策树的构建。
1) 开始:构建根节点,将所有训练数据都放在根节点,选择一个最优特征,按着这一特征将训练数据集分割成子集,使得各个子集有一个在当前条件下最好的分类。
2) 如果这些子集已经能够被基本正确分类,那么构建叶节点,并将这些子集分到所对应的叶节点去。
3)如果还有子集不能够被正确的分类,那么就对这些子集选择新的最优特征,继续对其进行分割,构建相应的节点,如果递归进行,直至所有训练数据子集被基本正确的分类,或者没有合适的特征为止。
4)每个子集都被分到叶节点上,即都有了明确的类,这样就生成了一颗决策树。
原文:https://blog.csdn.net/jiaoyangwm/article/details/79525237
C4.5算法
ID3算法存在一个问题,就是偏向于多值属性,例如,如果存在唯一标识属性ID,则ID3会选择它作为分裂属性,这样虽然使得划分充分纯净,但这种划分对分类几乎毫无用处。ID3的后继算法C4.5使用增益率(gain ratio)的信息增益扩充,试图克服这个偏倚。
信息增益率
C4.5算法首先定义了“分裂信息”,其定义可以表示成:
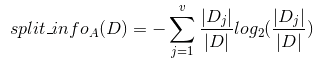
增益率为:
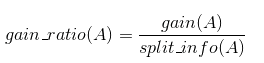
C4.5选择具有最大增益率的属性作为分裂属性,其具体应用与ID3类似,不再赘述。
离散化处理
将连续型的属性变量进行离散化处理形成决策树的训练集:
- 将需要处理的样本(对应根节点)或样本子集(对应子树)按照连续变量的大小从小到大进行排序
- 假设该属性对应不同的属性值共N个,那么总共有N-1个可能的候选分割值点,每个候选的分割阈值点的值为上述排序后的属性值中两两前后连续元素的中点
- 用信息增益选择最佳划分
from:https://www.cnblogs.com/coder2012/p/4508602.html
基尼指数( CART算法 ---分类树)
这篇博客写的很全面:https://blog.csdn.net/baimafujinji/article/details/53269040
定义:基尼指数(基尼不纯度):表示在样本集合中一个随机选中的样本被分错的概率。
注意:Gini指数越小表示集合中被选中的样本被分错的概率越小,也就是说集合的纯度越高,反之,集合越不纯。
即 基尼指数(基尼不纯度)= 样本被选中的概率 * 样本被分错的概率
书中公式:
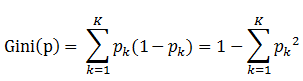
说明:
1. 表示选中的样本属于k类别的概率,则这个样本被分错的概率是(1-
)
2. 样本集合中有K个类别,一个随机选中的样本可以属于这k个类别中的任意一个,因而对类别就加和
3. 当为二分类是,Gini(P) = 2p(1-p)
样本集合D的Gini指数 : 假设集合中有K个类别,则:
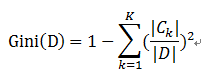
基于特征A划分样本集合D之后的基尼指数:
需要说明的是CART是个二叉树,也就是当使用某个特征划分样本集合只有两个集合:
1. 等于给定的特征值 的样本集合D1 ,
2 不等于给定的特征值 的样本集合D2
实际上是对拥有多个取值的特征的二值处理。
举个例子:

首先对数据集非类标号属性{是否有房,婚姻状况,年收入}分别计算它们的Gini系数增益,取Gini系数增益值最大的属性作为决策树的根节点属性。根节点的Gini系数 :

当根据是否有房来进行划分时,Gini系数增益计算过程为

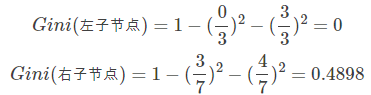
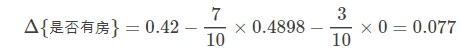
若按婚姻状况属性来划分,属性婚姻状况有三个可能的取值{married,single,divorced},分别计算划分后的
{married} | {single,divorced} 、 {single} | {married,divorced} 、 {divorced} | {single,married} 的Gini系数增益。
当分组为{married} | {single,divorced}时,表示婚姻状况取值为married的分组,
表示婚姻状况取值为single或者divorced的分组
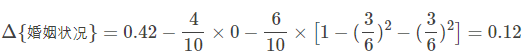
当分组为{single} | {married,divorced}时,
![]()
当分组为{divorced} | {single,married}时
![]()
对比计算结果,根据婚姻状况属性来划分根节点时取Gini系数增益最大的分组作为划分结果,也就是
{married} | {single,divorced}。
最后考虑年收入属性,我们发现它是一个连续的数值类型。对于年收入属性为数值型属性,首先需要对数据按升序排序,然后从小到大依次用相邻值的中间值作为分隔将样本划分为两组。例如当面对年收入为60和70这两个值时,我们算得其中间值为65。倘若以中间值65作为分割点。作为年收入小于65的样本,
表示年收入大于等于65的样本,于是则得Gini系数增益为
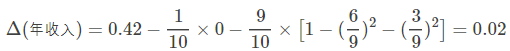
其他值的计算同理可得,我们不再逐一给出计算过程,仅列出结果如下(最终我们取其中使得增益最大化的那个二分准则来作为构建二叉树的准则):

注意,最大化增益等价于最小化子女结点的不纯性度量(Gini系数)的加权平均值,之前的表里我们列出的是Gini系数的加权平均值,现在的表里给出的是Gini系数增益。现在我们希望最大化Gini系数的增益。根据计算知道,三个属性划分根节点的增益最大的有两个:年收入属性和婚姻状况,他们的增益都为0.12。此时,选取首先出现的属性作为第一次划分。
接下来,采用同样的方法,分别计算剩下属性,其中根节点的Gini系数为(此时是否拖欠贷款的各有3个records)
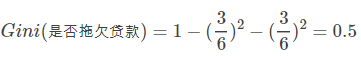
与前面的计算过程类似,对于是否有房属性,可得
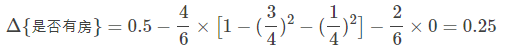
对于年收入属性则有:
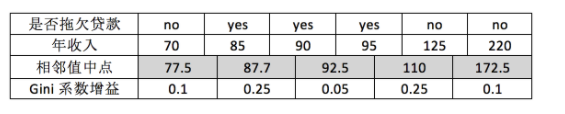
最后我们构建的CART如下图所示:

from:https://blog.csdn.net/baimafujinji/article/details/53269040
from:https://www.cnblogs.com/muzixi/p/6566803.html
总结:
决策树(有监督算法,概率算法)
a. 只接受离散特征,属于分类决策树。
b. 条件熵的计算 H(Label |某个特征) 这个条件熵反映了在知道该特征时,标签的混乱程度,可以帮助我们选择特征,选择下一步的决策树的节点。
c. Gini和entropy(熵)的效果没有大的差别,在scikit learn中默认用Gini是因为Gini指数不需要求对数,计算量少。
d. 把熵用到了集合上,把集合看成随机变量。
e. 决策树:贪心算法,无法从全局的观点来观察决策树,从而难以调优。
f. 叶子节点上的最小样本数,太少,缺乏统计意义。从叶子节点的情况,可以看出决策树的质量,发现有问题也束手无策。
优点:可解释性强,可视化。缺点:容易过拟合(通过剪枝避免过拟合),很难调优,准确率不高
g. 二分类,正负样本数目相差是否悬殊,投票机制
h. 决策树算法可以看成是把多个逻辑回归算法集成起来。
关于剪枝
在实际构造决策树时,通常要进行剪枝,这时为了处理由于数据中的噪声和离群点导致的过分拟合问题。剪枝有两种:
先剪枝——在构造过程中,当某个节点满足剪枝条件,则直接停止此分支的构造。
后剪枝——先构造完成完整的决策树,再通过某些条件遍历树进行剪枝。