文章目录
概念理解
熵:
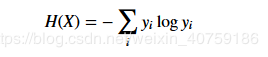
条件熵:
: A 是特征,y是目标或者分类,“条件”可以理解为 A对y的限制,假如:feature A有m个featureValue, 就是在取feature A有m个featureValue的值下,y的不确定和。 理解为y被A限制后的不确定性,A对y分类的影响
信息增益,互信息:
可以看成条件熵的相反,这个可以看成A对y分类的影响,简单理解就是y在引入A之后的不确定度。
假如以 作为y分类的标准,那么y就选择 的feature A, 那么这种策略就倾向于选择featureValue个数m越多的feature A,直观一点就是分类越多,y的确定性就会增加。
信息增益比
假如一直选择featureValue个数m越多的feature ,决策树就会成为一个又胖又矮的树,不管在哪里矮胖肯定不受欢迎,我们喜欢高瘦的,但是又不能太高,我们需要一个具有美感的
叉树。
在此引入了对m的惩罚,信息增益比:
为y关于A的熵,类似于交叉熵,和m有关。

基尼指数
可以看出基尼指数是和熵定义类似的,基尼指数越小,y的不确定度越小。


ID3算法描述
使用信息增益为划分依据

C4.5算法描述
以信息增益比为划分依据,修改第4步

CART (Classification and Regression Tree)算法描述:
以基尼指数为划分依据

三种算法优势及劣势:
ID3:
优点:
ID3中选择熵减少程度最大的特征来划分数据,也就是“最大信息熵增益”原则,是一种贪心策略,策略简单,
一般情况下都是有效果的。
缺点:
从划分的策略信息增益定义,这种策略总是选择特征值个数m多的特征来划分,导致决策树又矮又胖。
处理离散型的数据会出现上述问题,处理连续性不会出现上述问题,
处理混合型数据会倾向于选择离散型特征划分问题
改进:C4.5
C4.5:
优点:针对ID3总是选择特征值个数m多的特征,引入信息增益比来惩罚m,
缺点:信息增益比=互信息/y对feature的熵,C4.5会选择使“y对feature的熵”最小的策略,就是选择m小的划分,
假如二分的话,,就会分成很不均匀的两份,然后这个二叉树会非常深,又瘦又高,这种树中看不中用,泛化
能力非常差,就是我们常说的过拟合。
改进:划分feature选择策略,选出互信息比平均互信息高的feature(基本上m就不会少),
然后在这些features里选择信息增益比最高的feature,这是一种启发式策略,很直接但是又快又有效。
CART:
优点:
CART是一棵二叉树,采用二元切分法,每次把数据切成两份,分别进入左子树、右子树。
相比ID3和C4.5,CART应用要多一些,既可以用于分类也可以用于回归。
缺点:等我发现了再补充。