决策树模型是一种常用的有监督的学习模型,其主要用来解决分类问题,但是也可用来解决回归问题。
信息熵和信息增益
我们先来了解两个概念,信息熵与信息增益。
信息熵
信息熵用来表示事物的不确定性或不纯性,信息熵越大,则表示该事物的不确定性或不纯性越大。
信息熵的公式为:
举个例子:有两个集合,A集合[1,1,1,1,1,1,3],B集合[1,2,3,4,5,6,7],显然A集合的熵值要比B集合小得多,因为A集合只有两类,B集合有七类,相对来说A集合的不确定性要比B集合小,因此A集合的熵值更小。同样,我们在进行分类问题时,也希望通过节点分类后,数据的不确定性变小。
信息增益
简单来说,信息增益就是熵值变化的大小,即一个特征带来的熵值变化。
信息增益公式:
信息熵和信息增益计算方法:
举个例子:
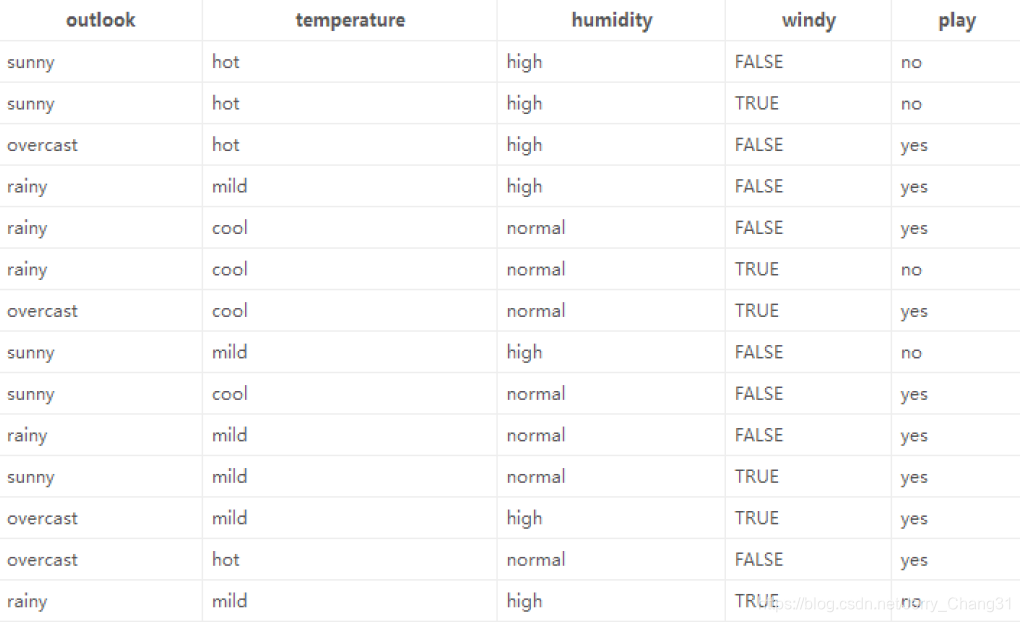
这是一份一个同学这14天打球的情况,其中“play”是标签,其他是特征。在分裂之前,14天中,有9天打球,5天不打球,所以,此时的熵值为:
如果按照“天气”特征进行分裂,分裂后结果为:
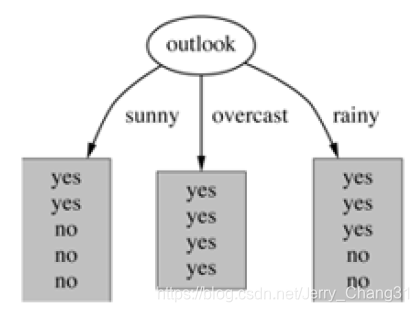
Outlook = sunny时,熵值为0.971
Outlook = overcast时,熵值为0
Outlook = rainy时,熵值为0.971
Outlook为sunny、overcast、rainy的概率分别为5/14,4/14,5/14
因此,总熵值为:
因此,信息增益为:
ID3算法
ID3算法就是以“信息熵”和“信息增益”为核心的贪心算法。ID3算法通过计算每个属性的信息增益,认为信息增益高的是好属性,每次划分选取信息增益最高的属性为划分标准,重复这个过程,直至生成一个能完美分类训练样例的决策树。
如上面的例子,ID3算法将依次计算按照4个特征分裂后的信息增益,选取最大的信息增益的特征作为分裂的根节点,然后再次求出不同叶子节点按照不同特征划分的信息增益,选取信息增益最大的特征进行分裂,不断重复,直至模型训练完成。简单来说:ID3算法是以“信息增益”作为分类标准的算法。
ID3算法的缺点:
1.不能处理连续值。 ID3算法中的特征只能是类别数据,如果是连续值,ID3算法将会把每个值作为一个类进行处理。
2.容易偏向取值较多的特征。 因为取值较多的特征的熵值更大,对其进行分类后熵值减小的数值容易较大,因此,ID3算法在进行特征选取时,容易偏向取值较多的特征。
3.容易发生过拟合,且只能进行分类不能进行回归。
4.使用了熵模型,涉及大量的对数运算,比较耗时。
C4.5算法
C4.5算法在ID3算法的基础上主要进行了如下改进:
1.将连续值离散化,用以处理连续特征。
2.使用信息增益率作为选取特征的标准,从而避免了ID3算法中容易偏向取值较多特征的缺点。
C4.5算法中连续值离散化过程:
1.加入特征A有m个点,先对特征A进行排序:a1,a2,a3······am;
2.取相邻两个点的均值作为划分点,共计m-1个划分点,其中第i个划分点使用
表示;
3.分别计算着m-1个点的信息增益,选择信息增益最大的点作为该连续特征的二元离散分类点。
信息增益率
信息增益率即信息增益与特征熵的比值:
C4.5算法的缺点:
1.和ID3算法一样,只能处理分类问题,不能处理回归问题。
2.同样使用了熵模型,比较耗时。
3.生成的是多叉树。
CART算法
CART算法既能处理分类问题,也能处理回归问题。
CART算法与C4.5算法类似,不同的是CART算法使用基尼系数作为特征选择的依据,并且在处理连续值时,生成的是二叉树而非多叉树。
基尼系数(Gini)
如果一个样本D,共有K个类别,第K个类别的数量为
,第K个类别的概率为
:
即:
对于样本D,根据特征A的某个值a,将D分为D1和D2,则在特征A下,D的基尼系数为:
CART回归:
CART回归树和CART分类树相似,不同之处在于:
1.连续值的处理方式不同:
CART回归树的度量目标是:对于任意特征A,对应任意划分点S两边划分成的数据集D1和D2,求出是D1和D2各自集合的均方差最小;同时,D1和D2的均方差之和最小所对应的特征和特征值划分点,表达式为:
其中,C1为D1的均值,C2为D2的均值。
2.决策树建立后的预测方式不同:
分类树的预测按照投票方式进行,而回归树采用最终叶子节点的均值或中位数作为最终预测结果。
