版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/sinat_30071459/article/details/53100791
说明:
(1)本文用到的darknet代码下载时间为2016-11-09
(2)由于之前博文做的数据集是参考VOC2007格式,并且YOLO可以将VOC2007和VOC2012数据集转换成YOLO所需要的格式,所以这里我们也是一样,将参考VOC2007做的数据集转换成YOLO所需的训练格式。做VOC2007数据集过程参考:http://blog.csdn.net/sinat_30071459/article/details/50723212
(3)本文主要参考YOLO官网:http://pjreddie.com/darknet/yolo/
1、配置Darknet
darknet v1代码下载地址:Darknet v1
主要参考darknet的官网,上面写得很详细,网址:Installing Darknet
在配置Darknet过程中,主要是在nvcc处出错,所以修改Makefile的NVCC为绝对路径,一般为:
NVCC=/usr/local/cuda-7.5/bin/nvcc其他需要注意的地方参考官网就行。
如果make没有出错,那么可以下载作者训练的模型测试一下:
(1)下载yolo.weights:
wget http://pjreddie.com/media/files/yolo.weights(2)执行:
./darknet yolo test cfg/yolo.cfg yolo.weights data/dog.jpg2.将VOC数据集转成YOLO格式
由于前面的文章有写到做VOC2007格式的数据集,所以,我们和作者一样,将VOC数据集转成YOLO训练所需格式,转换过程很简单,因为作者提供了转换的python代码:
darknet\scripts\voc_label.py
(1)将数据集拷贝到darknet\scripts下
(2)我们打开voc_label.py并修改该代码:
sets=[('2007', 'train'), ('2007', 'val'), ('2007', 'test')]
classes = ["head","top","bag","down","shoes"]
classes根据你的数据集类别改。还有需要注意的是,代码里写的文件夹是VOCdevkit,我们的可能是VOCdevkit2007,修改成VOCdevkit即可。
然后,终端进入darknet\scripts,执行:
python voc_label.py
darknet\scripts下多了2007_train.txt、2007_val.txt和2007_test.txt三个文件(如下),这三个文件是数据集中图片的路径。由于yolo训练只需要一个txt文件,文件中包含所有你想要训练的图片的路径,因此,我们可以用2007_train.txt、2007_val.txt和2007_test.txt包含的图片均用来训练,因此执行:
cat 2007_* > train.txt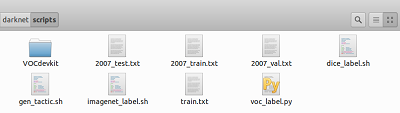
3.修改代码
(1)修改darknet\src\yolo.c
char *voc_names[] = {"head","top","bag","down","shoes"}
改成你的数据集类别;
char *train_images = "/home/luj/darknet/scripts/train.txt";
char *backup_directory = "/home//luj/darknet/backup/";
draw_detections(im, l.side*l.side*l.n, thresh, boxes, probs, voc_names, alphabet, 5);
else if(0==strcmp(argv[2], "demo")) demo(cfg, weights, thresh, cam_index, filename, voc_names, 5, frame_skip, prefix);
类别数改为你的数据集类别数(例如我的有5类)。
(2)修改darknet\src\yolo_kernels.cu
draw_detections(det, l.side*l.side*l.n, demo_thresh, boxes, probs, voc_names, voc_labels, 5);(3)修改darknet\cfg\tiny-yolo.cfg
本文以训练tiny模型为例,因此修改的是tiny-yolo.cfg文件,其他模型修改类似。
output= 735 // 该值为side*side*(num*5+类别数)
activation=linear
[detection]
classes= 5 //数据集类别
coords=4
rescore=1
side=7 /////
num=2
softmax=0
sqrt=1
jitter=.2
其他的一些参数可以按自己需求修改,比如学习率、max_batches等。
4.下载预训练模型:
(在该模型参数的基础上微调)
该文件放在darknet下即可。
PS:经过以上的修改,记得重新make一下darknet!!!
5.训练
在dartnet下执行:
./darknet yolo train cfg/tiny-yolo.cfg darknet.conv.weights一切正常的话,就开始训练了。
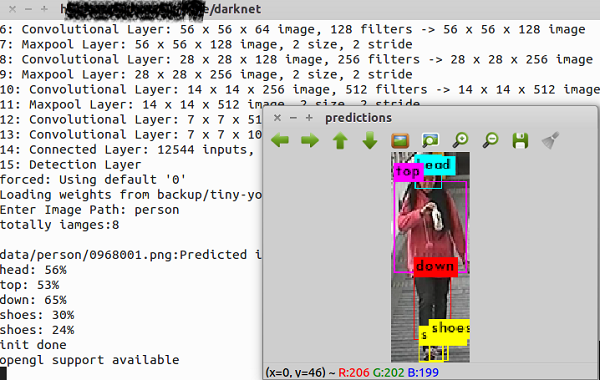
6.测试和结果
执行:
./darknet yolo test cfg/tiny-yolo.cfg backup/tiny-yolo_final.weights
结果: