标注数据
将自己的数据用labelme(至于如何安装和使用请自查)打开,然后选择线段或者点进行标注,标注完成之后会生成json格式的标注信息。

处理数据
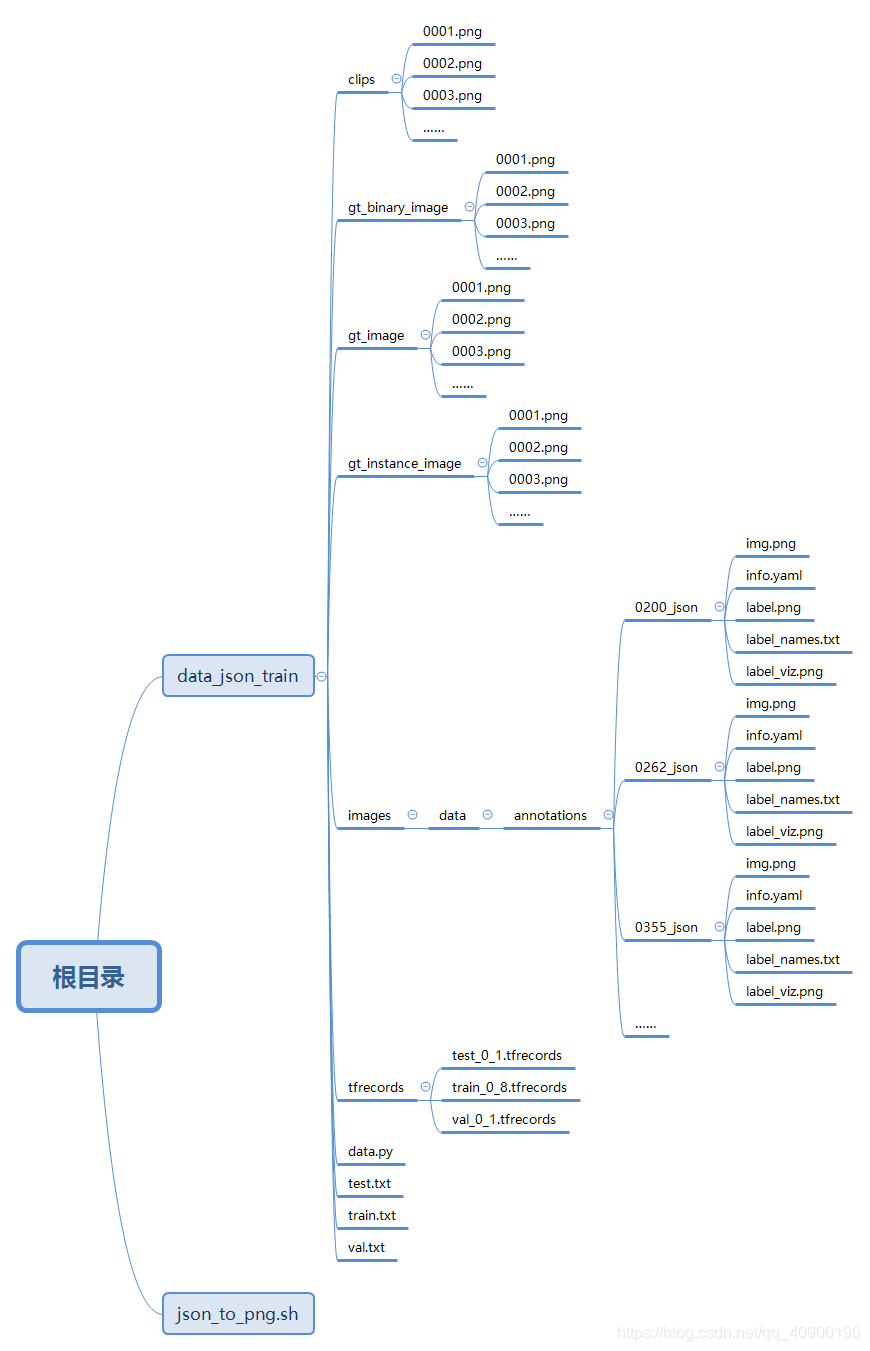
处理得到的json文件,会生成这五个文件

我这里使用的是批量转换.sh命令,代码如下(如你的数据是单个的你可用自带的命令来生成):
单个数据转换
labelme_json_to_dataset <文件名>.json批量数据转换(我的名字为json_to_png.sh)
#!/bin/bash
let i=1
path=./ # json文件路径,将sh文件放到json同目录下为 ./
cd ${path}
for file in *.json # 依次查找json文件
do
labelme_json_to_dataset ${file} #在当前目录下将json文件转换为图片,
let i=i+1
done
sh ./json_to_png.sh会根据json的 名字生成对应的文件夹以及转换之后的文件


之后进行图片二值化的转变,分别生成对应的文件(根据github代码来看,首先你得先创建对应的文件夹)

创建完成之后,运行转变代码,使用vim 或者 vi 创建一个py文件,文件名自己定义后缀为.py (我这里定义为data.py)
#data.py
import cv2
from skimage import measure, color
from skimage.measure import regionprops
import numpy as np
import os
import copy
def skimageFilter(gray):
binary_warped = copy.copy(gray)
binary_warped[binary_warped > 0.1] = 255
gray = (np.dstack((gray, gray, gray))*255).astype('uint8')
labels = measure.label(gray[:, :, 0], connectivity=1)
dst = color.label2rgb(labels,bg_label=0, bg_color=(0,0,0))
gray = cv2.cvtColor(np.uint8(dst*255), cv2.COLOR_RGB2GRAY)
return binary_warped, gray
def moveImageTodir(path,targetPath,name):
if os.path.isdir(path):
image_name = "gt_image/"+str(name)+".png"
binary_name = "gt_binary_image/"+str(name)+".png"
instance_name = "gt_instance_image/"+str(name)+".png"
train_rows = image_name + " " + binary_name + " " + instance_name + "\n"
origin_img = cv2.imread(path+"/img.png")
origin_img = cv2.resize(origin_img, (1280,720))
cv2.imwrite(targetPath+"/"+image_name, origin_img)
img = cv2.imread(path+'/label.png')
img = cv2.resize(img, (1280,720))
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
binary_warped, instance = skimageFilter(gray)
cv2.imwrite(targetPath+"/"+binary_name, binary_warped)
cv2.imwrite(targetPath+"/"+instance_name, instance)
print("success create data name is : ", train_rows)
return train_rows
return None
if __name__ == "__main__":
print('11')
count = 1
with open("./train.txt", 'w+') as file:
for images_dir in os.listdir("./images"):
dir_name = os.path.join("./images", images_dir + "/annotations")
for annotations_dir in os.listdir(dir_name):
json_dir = os.path.join(dir_name, annotations_dir)
if os.path.isdir(json_dir):
train_rows = moveImageTodir(json_dir, "./", str(count).zfill(4))
file.write(train_rows)
count += 1
如果就这样运行这个py文件的话,你会发现运行到循环的时候就会结束,什么都不会生成。步骤
1.创建一个文件夹名字自取(我创建的为images)注意 因为之前转二值化的代码中明确定义了文件夹的名字为images,因此你可以修改代码里面的名字,也可以直接将文件夹取名为images
![]()
2.在你创建的这个文件夹下再创建一个文件夹名字随便(我这里取名为data)
![]()
3.在你创建的文件夹下,再创建一个文件夹(我创建的为annotations),和第一个操作一样,代码中指定了文件夹的名字为annotations,你可根据第一个操作来修改
![]()
4.都创建好之后,将.sh执行完生成的文件夹放入annotations文件夹下

之后开始运行转换代码(data.py)运行结束后就可以看到gt_binary_image、gt_image、gt_instance_image这三个文件夹里面已经有图片了,并且会生成一个train.txt!!!!!



接下来根据github上的提示进行数据标注转换,转换成TFRecord
python data_provider/lanenet_data_feed_pipline.py
--dataset_dir ./data/training_data_example/training/
--tfrecords_dir ./data/training_data_example/tfrecords这里的--dataset_dir的路径就是你的gt_binary_image、gt_image、gt_instance_image这三个文件夹所在的目录。执行完这个操作之后会生成tfrecords、test.txt、val.txt这几个文件,并查看文件是否有数据(val无数据原因可能为你的总数据太少而无法划分,可将数据增加到10个以上)


之后就可以运行GitHub作者的训练代码了。
代码结构