首先贴上原github项目地址,这里感谢大神们的奉献:https://github.com/balancap/SSD-Tensorflow
数据集制作
因为老板接的丰田的一个项目,工厂那边要求能识别出雨天打伞的行人、交通锥形桶、躺在地上的人等,PASCAL VOC的数据集类别里没这些,是满足不了他们要求了,所以要去制作数据集训练网络。我们去现场拍了些视频,然后用我之前写的一个脚本解析,得到原始图片,拿给实验室的学弟学妹们标注。标注工具也是github上一个开源项目,作者搞了个GUI,生成带标签的.xml文件,这里也想感谢他。https://github.com/tzutalin/labelImg
标注完了之后得到大量的.xml文件,然后我们需要将这些数据做成VOC的一样格式。先来看看VOC的训练集是什么样的:

因为只是做检测,生成Annotations、ImageSets、JPEGImages这三个文件夹就可以了。后面的两个segmentation还有一个test,这三个夹子不用管。Annotations是用来放.xml文件的,JPEGImages放原始的jpg图片,像这样:
ImageSets这个夹子打开长这样:

我们只要生成Main文件夹就可以了,这个文件夹是用来存放数据对应的.txt文件的。打开Main:
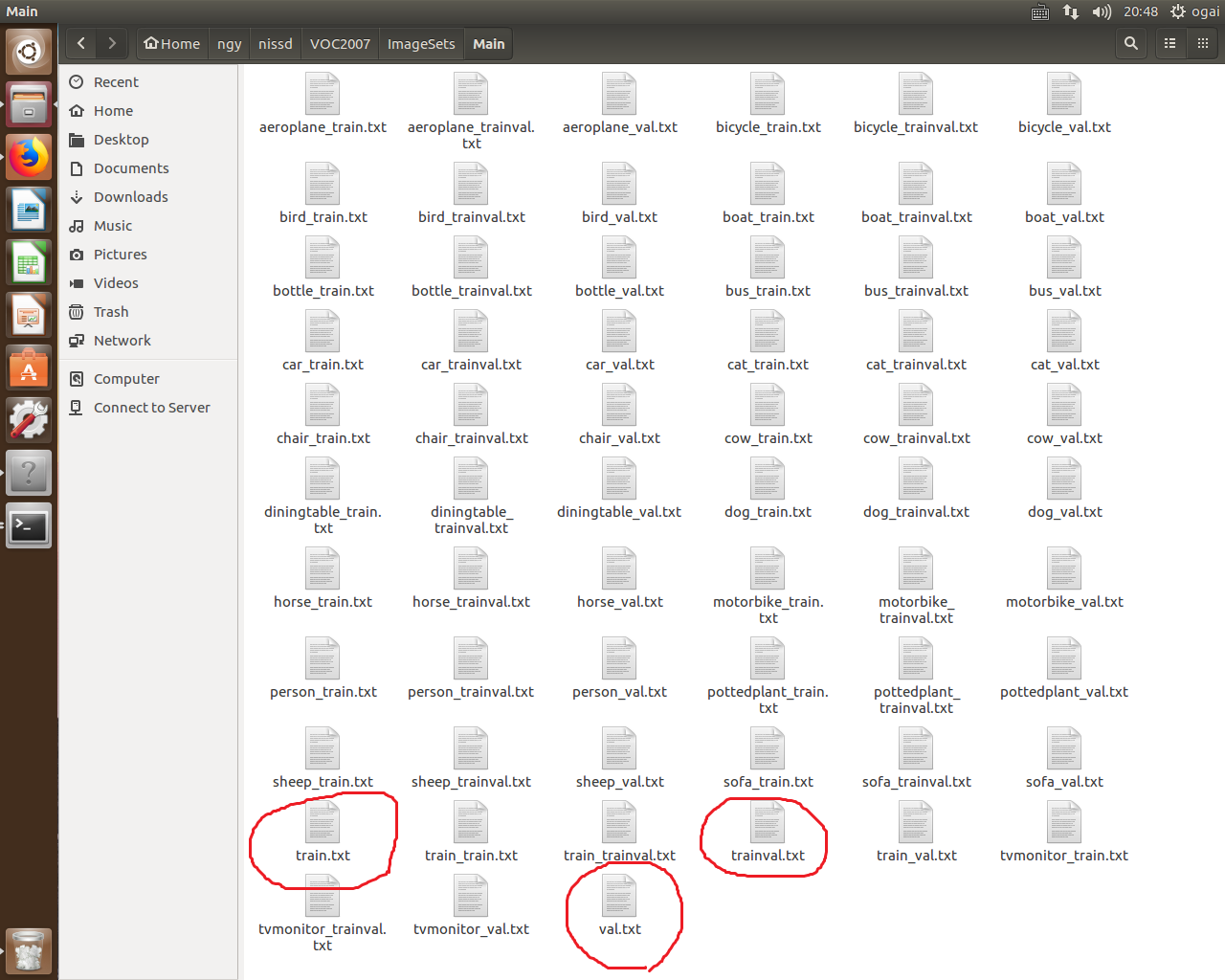
其他的都不重要,生成这三个画圈的文件加一个test.txt就行了。利用程序生成test.txt, train.txt, trainval.txt, val.txt, 代码如下:
import os
import random
xmlfilepath=r'/home/ogai/ngy/nissd/mydataset/Annotations'
saveBasePath=r"/home/ogai/ngy/nissd/"
trainval_percent=0.8
train_percent=0.7
total_xml = os.listdir(xmlfilepath)
num=len(total_xml)
list=range(num)
tv=int(num*trainval_percent)
tr=int(tv*train_percent)
trainval= random.sample(list,tv)
train=random.sample(trainval,tr)
print("train and val size",tv)
print("traub suze",tr)
ftrainval = open(os.path.join(saveBasePath,'mydataset/ImageSets/Main/trainval.txt'), 'w')
ftest = open(os.path.join(saveBasePath,'mydataset/ImageSets/Main/test.txt'), 'w')
ftrain = open(os.path.join(saveBasePath,'mydataset/ImageSets/Main/train.txt'), 'w')
fval = open(os.path.join(saveBasePath,'mydataset/ImageSets/Main/val.txt'), 'w')
for i in list:
name=total_xml[i][:-4]+'\n'
if i in trainval:
ftrainval.write(name)
if i in train:
ftrain.write(name)
else:
fval.write(name)
else:
ftest.write(name)
ftrainval.close()
ftrain.close()
fval.close()
ftest .close() 到此为止数据集制作完毕。
生成tfrecords
我们需要先修改一下/datasets/pascalvoc_common.py中的类别标签定义,我的做法:
"""
VOC_LABELS = {
'none': (0, 'Background'),
'aeroplane': (1, 'Vehicle'),
'bicycle': (2, 'Vehicle'),
'bird': (3, 'Animal'),
'boat': (4, 'Vehicle'),
'bottle': (5, 'Indoor'),
'bus': (6, 'Vehicle'),
'car': (7, 'Vehicle'),
'cat': (8, 'Animal'),
'chair': (9, 'Indoor'),
'cow': (10, 'Animal'),
'diningtable': (11, 'Indoor'),
'dog': (12, 'Animal'),
'horse': (13, 'Animal'),
'motorbike': (14, 'Vehicle'),
'Person': (15, 'Person'),
'pottedplant': (16, 'Indoor'),
'sheep': (17, 'Animal'),
'sofa': (18, 'Indoor'),
'train': (19, 'Vehicle'),
'tvmonitor': (20, 'Indoor'),
}
"""
VOC_LABELS = {
'none': (0, 'Background'),
'cone': (1, 'Cone'),
'umbrellaman': (2, 'Umbrella Man'), # 类别我就不一一列举了
}
总之你的数据有多少类就换成多少类。
写个shell脚本,利用tf_convert_data.py来生成tfrecords:#!/bin/bash
DATASET_DIR=./mydataset/
OUTPUT_DIR=./tfrecords
python tf_convert_data.py \
--dataset_name=pascalvoc \
--dataset_dir=${DATASET_DIR} \
--output_name=voc_2007_train \
--output_dir=${OUTPUT_DIR}但是呢,我这里报错了:UnicodeDecodeError: 'utf-8' codec can't decode byte 0xff in position 0: invalid start byte
解决方法,修改pascalvoc_to_tfrecords.py的第83行,将'r'改成'rb'
image_data = tf.gfile.FastGFile(filename, 'rb').read()Fine-tuning训练
在预训练好的ssd模型(vgg300)上训练自己的数据,然后写个shell脚本,利用train_ssd_network.py来训练,注意路径:
#!/bin/bash
DATASET_DIR=./tfrecords
TRAIN_DIR=./logs/
CHECKPOINT_PATH=./checkpoints/ssd_300_vgg.ckpt
python train_ssd_network.py \
--train_dir=${TRAIN_DIR} \
--dataset_dir=${DATASET_DIR} \
--dataset_name=pascalvoc_2007 \
--dataset_split_name=train \
--model_name=ssd_300_vgg \
--checkpoint_path=${CHECKPOINT_PATH} \
--save_summaries_secs=60 \
--save_interval_secs=600 \
--weight_decay=0.0005 \
--optimizer=adam \
--learning_rate=0.001 \
--batch_size=16TRAIN_DIR是自己训练产生的模型的checkpoints目录,待会demo要从这里载入checkpoints。
我训练了一天多一点,机器是1070ti(6g),然而loss总是在1~5之间振荡,无法收敛,我也不知道为什么。后来我直接关闭了训练,用最新的checkpoints载入测试,奇怪的是竟然发现结果还行......
Demo
用jupyter notebook打开/notebooks/ssd_notebook.ipynb,然后需要修改一下checkpoints载入路径,替换成自己训练的结果。
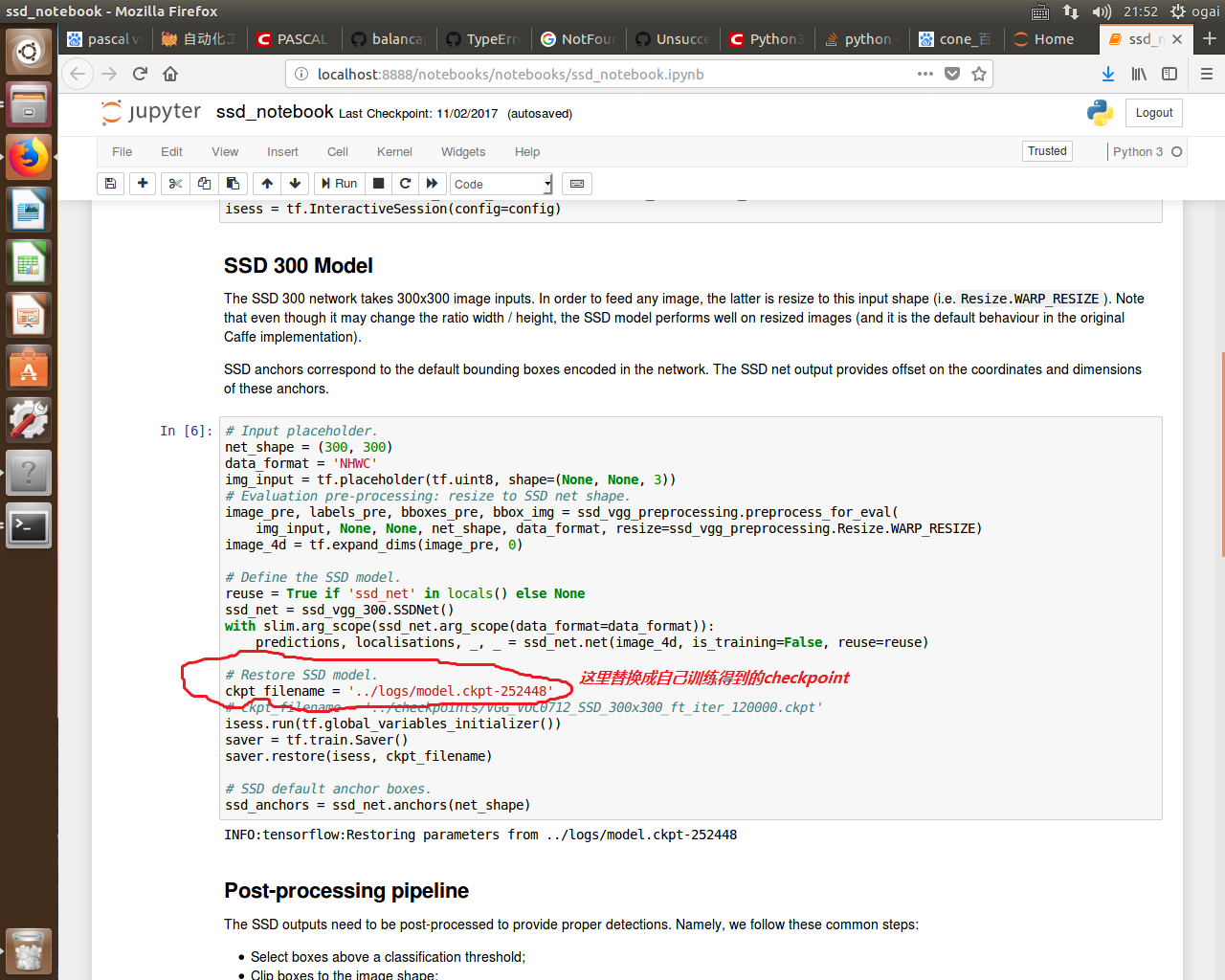
改下类别标签:
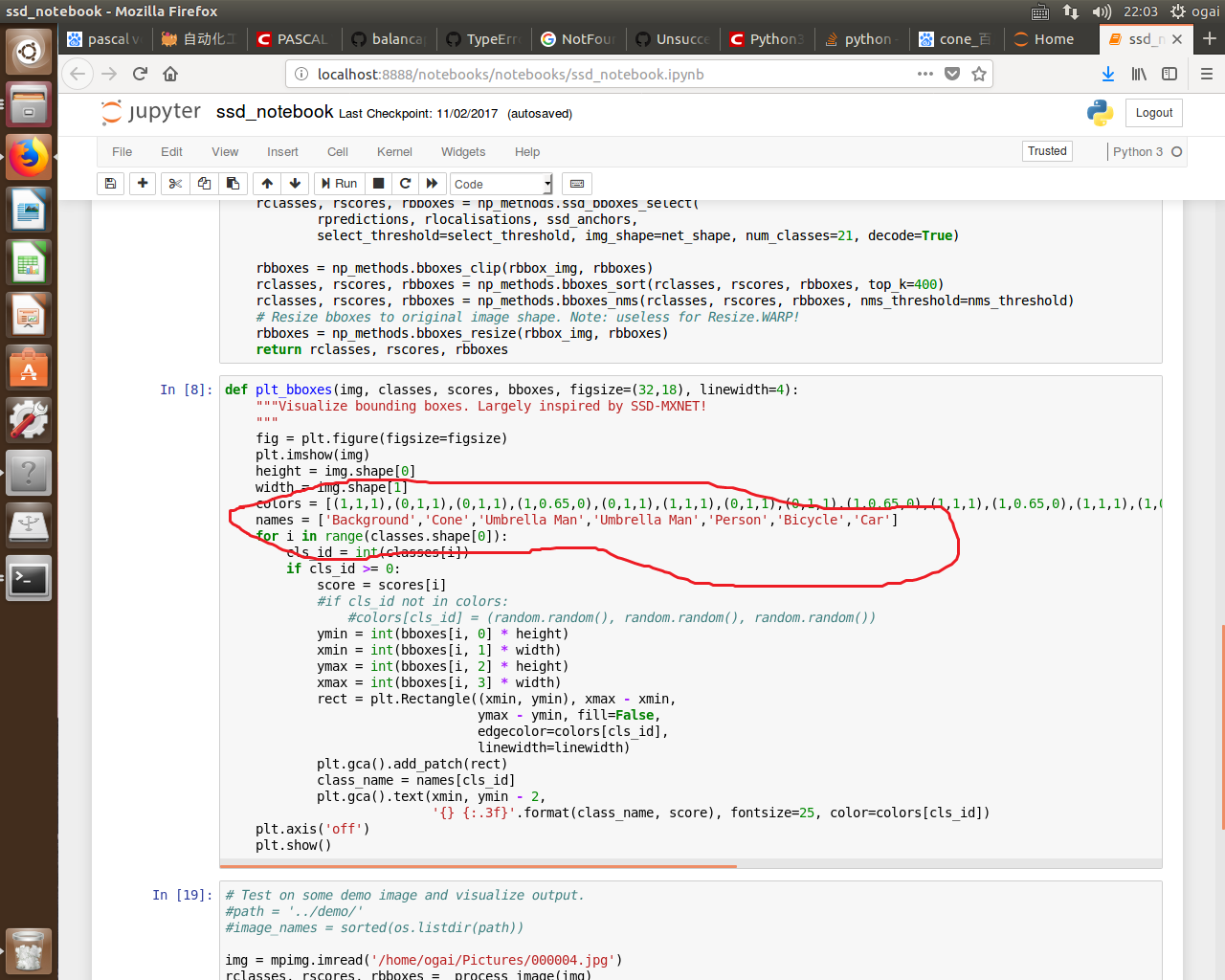
网上找了点图片,测测结果:



Evaluation
写个shell脚本,利用eval_ssd_network.py来evaluate:
#!/bin/bash
EVAL_DIR=./logs/
DATASET_DIR=./tfrecords/
CHECKPOINT_PATH=./logs/model.ckpt-252448
python eval_ssd_network.py \
--eval_dir=${EVAL_DIR} \
--dataset_dir=${DATASET_DIR} \
--dataset_name=pascalvoc_2007 \
--dataset_split_name=train \
--model_name=ssd_300_vgg \
--checkpoint_path=${CHECKPOINT_PATH} \
--batch_size=1EVAL_DIR是eval结果保存的路径,DATASET_DIR是用来eval的数据集的路径。
但是报错了:TypeError: Can not convert a tuple into a Tensor or Operation
解决方法,在eval_ssd_network.py里定义一个flatten函数:
def flatten(x):
result = []
for el in x:
if isinstance(el, tuple):
result.extend(flatten(el))
else:
result.append(el)
return result然后将原本第318和338行的
eval_op = list(names_to_updates.values()),改为
eval_op = flatten(list(names_to_updates.values())),