前言
好久没讲算法了,今天分享一个异常点检测算法Isolation Forest。之前也是没听说过这个算法,中文名叫孤立森林,听客户讲了就顺便查了下这个算法的论文,感觉还是非常有用滴。
论文地址:http://cs.nju.edu.cn/zhouzh/zhouzh.files/publication/icdm08b.pdf
异常检测的概念
首先聊下什么是异常检测,异常检测就是发现一堆数据中的异常点。可以应用到很多领域,比如:
-
噪声数据的排查
-
新的天体的发现
-
异常的网络攻击的发现
-
异常的信用卡购物记录的发现
异常点在数据分析领域非常有用途,目前常用的异常点检测有以下几种:
基于距离的异常检测:遍历所有的数据点之间的距离,与大部分数据的距离都比较远的点,就是异常点。这么算的结果比较准,但是基于距离的计算复杂度高,计算开销大。
基于密度的异常点检测:基于密度也比较好理解,就是normal数据一定是处于密度集中的区域,anormal数据一定是在相对稀疏的领域。同样有计算开销的问题,密度本质上也是一种距离计算。
Isolation Forest算法,本质上是一种平面切分的理念,计算成本比较小,下面我们详细介绍下。

Isolation Forest
理解它概念可能需要一些空间几何的背景,我们可以想象所有的数据点都是在一个n维空间分布的,n取决于数据的字段个数,理论上可以通过平面切分的方式将任意一个点与其它点隔离开。
Isolation Forest的思路就是,如果是normal数据,你需要更多地切割平面才能区分这条数据。如果是anormal数据,就可以用较少的平面切割。如下图所示:
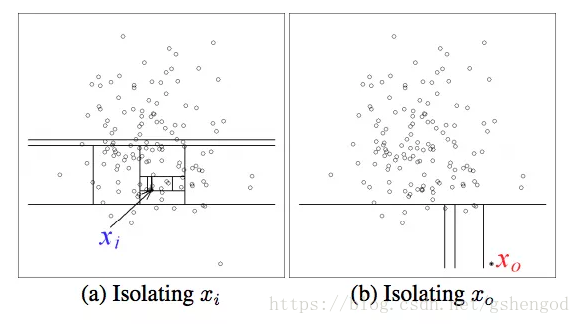
如果要区分
- (a)图中的点,这个点显然是个normal数据,需要非常多的切割平面,
- (b)中的anormal数据需要的切割面就比较少。
于是基于这样的理论,需要一种数学模型来表示切割平面个数以及数据的关系,二叉树就是一种合适的方式。
可以用树的深度表示切割平面数,每条数据对应二叉树中的一个节点。数据的切割面越多,数据在二叉树中的纵深越深。
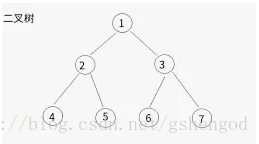
这样建模有一个很大的好处,如果目的是找出异常点,那么不需要每一个二叉树都完整创建,也就是不需要每次都遍历所有数据,因为要找的异常点是每棵树比较靠近父节点的节点,非常的节约计算资源。
ok~关于Isolation Forest就介绍这么多,希望对大家有帮助,提前预祝大家十一玩的愉快。