目的:对于无label数据,寻找异常数据
孤立森林算法思想:
1)用一个随机超平面来切割(split)数据空间(data space), 切一次可以生成两个子空间(想象拿刀切蛋糕一分为二)
2)再继续用一个随机超平面来切割每个子空间,循环下去,直到每子空间里面只有一个数据点为止,直观上来讲,我们可以发现那些密度很高的簇是可以被切很多次才会停止切割,但是那些密度很低的点很容易很早的就停到一个子空间了
算法实现步骤:
iForest 由t个iTree(Isolation Tree)孤立树 组成,每个iTree是一个二叉树结构
1)从训练数据中随机选择Ψ个点样本点作为subsample,放入树的根节点
2)随机指定一个维度(attribute),在当前节点数据中随机产生一个切割点p——切割点产生于当前节点数据中指定维度的最大值和最小值之间
3)以此切割点生成了一个超平面,然后将当前节点数据空间划分为2个子空间:把指定维度里小于p的数据放在当前节点的左孩子,把大于等于p的数据放在当前节点的右孩子
4)在孩子节点中递归步骤2和3,不断构造新的孩子节点,直到 孩子节点中只有一个数据(无法再继续切割)或 孩子节点已到达限定高度
评估测试数据:
对于一个训练数据x,我们令其遍历每一棵iTree,然后计算x最终落在每个树第几层(x在树的高度)。然后我们可以得出x在每棵树的高度平均值,设置一个阈值(边界值),低于此阈值的测试数据即为异常,
异常在这些树中只有很短的平均高度
例子遍历一棵树:
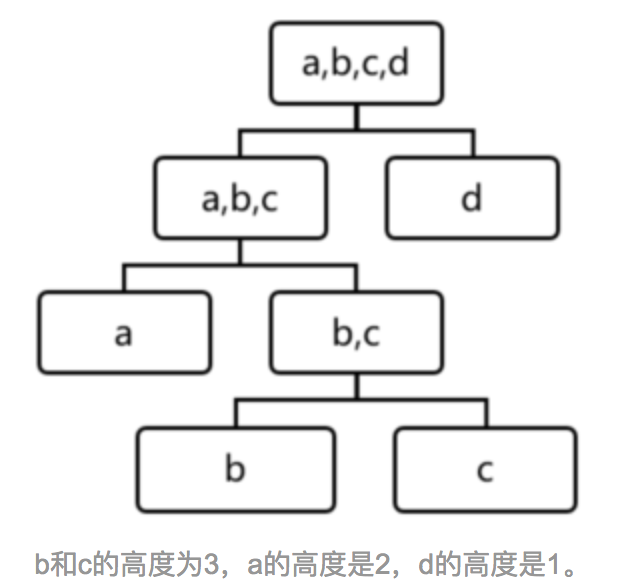
可以看到d最有可能是异常,因为其最早就被孤立(isolated)了
iForest算法默认参数设置如下:
subsample size: 256
Tree height: 8
Number of trees: 100
通俗解释就是——建100棵iTree,每棵iTree最高8层,且每棵iTree都是独立随机选择256个数据样本建成
算法优缺点:
1)通常树的数量越多,算法越稳定
2)iForest不适用于特别高维的数据,由于每次切数据空间都是随机选取一个维度,建完树后仍然有大量的维度信息没有被使用,导致算法可靠性降低
论文下载:
http://cs.nju.edu.cn/zhouzh/zhouzh.files/publication/icdm08b.pdf
http://cs.nju.edu.cn/zhouzh/zhouzh.files/publication/tkdd11.pdf
调包:
http://scikit-learn.org/stable/modules/generated/sklearn.ensemble.IsolationForest.html
转载本博笔记须在文章明显处注明原文的链接和作者信息
参考资料:
https://www.jianshu.com/p/5af3c66e0410?utm_campaign=maleskine