Deep Forest:gcForest算法理解
原文地址:https://blog.csdn.net/zzc15806/article/details/80674992
作者:zzc15806
一、相关理论
本篇博文主要介绍南京大学周志华教授在2017年提出的一种深度森林结构——gcForest(多粒度级联森林)。近年来,深度神经网络在图像和声音处理领域取得了很大的进展。关于深度神经网络,我们可以把它简单的理解为多层非线性函数的堆叠,当我们人工很难或者不想去寻找两个目标之间的非线性映射关系,我们就多堆叠几层,让机器自己去学习它们之间的关系,这就是深度学习最初的想法。既然神经网络可以堆叠为深度神经网络,那我们可以考虑,是不是可以将其他的学习模型堆叠起来,以获取更好的表示性能,gcForest就是基于这种想法提出来的一种深度结构。gcForest通过级联的方式堆叠多层随机森林,以获得更好的特征表示和学习性能。
深度神经网络虽然取得很好的性能,但是也存在一些问题。第一、要求大量的训练数据。深度神经网络的模型容量很大,为了获得比较好的泛化性能,需要大量的训练数据,尤其是带标签的数据。获取大规模数据需要耗费很大的人工成本;第二、深度神经网络的计算复杂度很高,需要大量的参数,尤其是有很多超参数(hyper-parameters)需要优化。比如网络层数、层节点数等。所以神经网络的训练需要很多trick;第三、深度神经网络目前最大的问题就是缺少理论解释。就像“炼丹”一样,反正“丹药”出来了,怎么出来的我也不知道。
gcForest使用级联的森林结构来进行表征学习,需要很少的训练数据,就能获得很好的性能,而且基本不怎么需要调节超参数的设置。gcForest不是要推翻深度神经网络,也不是以高性能为目的的研究,只是在深度结构研究方面给我们提供了一些思路,而且确实在一些应用领域获得了很好的结果,是一项很有意义的研究工作。
二、算法介绍
2.1 级联森林结构

图一 级联森林结构图
图一表示gcForest的级联结构。
每一层都由多个随机森林组成。通过随机森林学习输入特征向量的特征信息,经过处理后输入到下一层。为了增强模型的泛化能力,每一层选取多种不同类型的随机森林,上图给了两种随机森林结构,分别为completely-random tree forests(蓝色)和random forests(黑色),每种两个。其中,每个completely-random tree forests包含500棵树,每个节点通过随机选取一个特征作为判别条件,并根据这个判别条件生成子节点,直到每个叶子节点只包含同一类的实例而停止;每个random forests同样包含500棵树,节点特征的选择通过随机选择√d个特征(d为输入特征的数量),然后选择基尼系数最大特征作为该节点划分的条件。
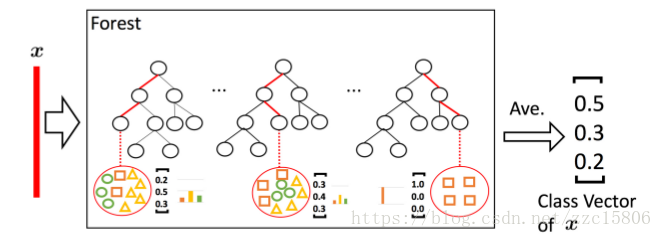
图二 类分布向量生成流程
图二表示每个森林的类分布向量生成流程。
随机森林中每棵决策树对于输入特征向量都会产生一个关于每类的预测概率,对于三分类,则为一个三维向量,然后对所有树的产生的概率分布向量进行平均来产生随机森林输出的类分布向量。然后对当前层的每个随机森林输出的类分布向量与原始的特征向量进行拼接,作为下一层的输入。对于三分类,假设每层有4棵树,则下一层的输入特征向量维度为(3×4 + length of x)。
2.2 多粒度扫描

图三 特征预处理流程
图三表示对输入特征使用多粒度扫描的方式产生级联森林的输入特征向量。
对于400维的序列数据,采用100维的滑动窗对输入特征进行处理,得到301(400 - 100 + 1)个100维的特征向量。对于20×20的图像数据,采用10×10的滑动窗对输入特征进行处理,得到121((20-10+1)*(20-10+1))个10×10的二维特征图。然后将得到的特征向量(或特征图)分别输入到一个completely-random tree forest和一个random forest中(不唯一,也可使用多个森林),以三分类为例,会得到301(或121)个3维类分布向量,将这些向量进行拼接,得到1806(或726)维的特征向量。
2.3 总体流程
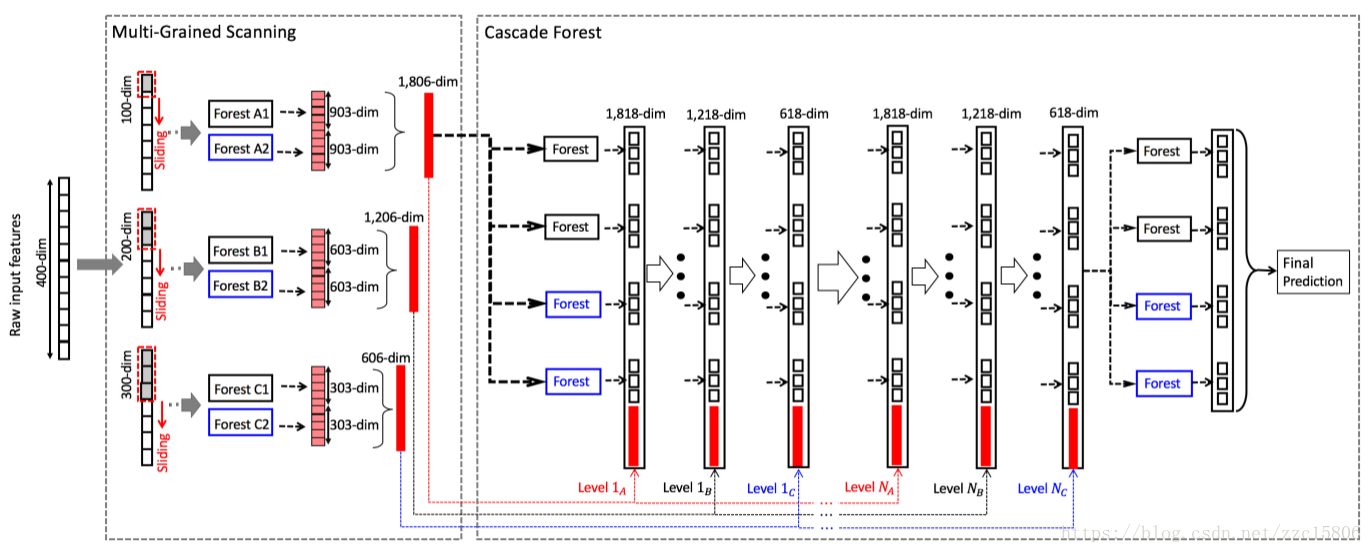
图四 gcForest总流程图
图四为gcForest的总体流程图。
第一步:使用多粒度扫描对输入特征进行预处理。以使用三个尺寸的滑动窗为例,分别为100-dim,200-dim和300-dim。输入数据为400-dim的序列特征,使用100-dim滑动窗会得到301个100-dim向量,然后输入到一个completely-random tree forest和一个random forest中,两个森林会分别得到的301个3-dim向量(3分类),将两个森林得到的特征向量进行拼接,会得到1806-dim的特征向量。同理,使用200-dim和300-dim滑动窗会分别得到1206-dim和606-dim特征向量。
第二步:将得到的特征向量输入到级联森林中进行训练。首先使用100-dim滑动窗得到的1806-dim特征向量输入到第一层级联森林中进行训练,得到12-dim的类分布向量(3分类,4棵树)。然后将得到的类分布向量与100-dim滑动窗得到的特征向量进行拼接,得到1818-dim特征向量,作为第二层的级联森林的输入数据;第二层级联森林训练得到的12-dim类分布向量再与200-dim滑动窗得到的特征向量进行拼接。作为第三层级联森林的输入数据;第三层级联森林训练得到的12-dim类分布向量再与300-dim滑动窗得到的特征向量进行拼接,做为下一层的输入。一直重复上述过程,直到验证收敛。
表一 超参数和默认设置总结。黑体字表示影响较大的超参数,"?"表示需要根据不同任务进行调节。

表一对比了深度神经网络和gcForest的超参数设置。从表中可以看出,gcForest所需超参数更少,结构更加简单。
三、算法实现
官方开源地址:https://github.com/kingfengji/gcForest
3.1 安装
将代码clone到本地,然后将lib下的gcforest复制到你的python路径:
$ cp -r lib/gcforest/ ~/anaconda3/lib/python3.5/site-packages/
3.2 使用
from gcforest.gcforest import GCForest gc = GCForest(config) # should be a dict X_train_enc = gc.fit_transform(X_train, y_train) y_pred = gc.predict(X_test)
四、总结
相比于深度神经网络,gcForest具有以下优点:
1. 对于某些领域,gcForest的性能较之深度神经网络具有很强的竞争力;
2. gcForest所需参数少,容易训练;
3. gcForest对于超参数的设置不敏感,同样的超参数设置在不同数据集上都能获得很好的性能;
4. gcForest对于数据量没有要求,在小数据集上也能获得很好的性能。
【参考文献】
Deep Forest: Towards an Alternative to Deep Neural Networks
版权声明:本文为博主原创文章,请尊重原创,转载请注明原文地址和作者信息!