背景
现有的异常检测方法主要是通过对正常样本的描述,给出一个正常样本在特征空间中的区域,对于不在这个区域中的样本,视为异常。这些方法的主要缺点是,异常检测器只会对正常样本的描述做优化,而不会对异常样本的描述做优化,这样就有可能造成大量的误报,或者只检测到少量的异常。
异常的两个特点:异常数据只占很少量、异常数据特征值和正常数据差别很大。
孤立森林,不再是描述正常的样本点,而是要孤立异常点,由周志华教授等人于2008年在第八届IEEE数据挖掘国际会议上提出。
先了解一下该算法的动机。目前学术界对异常(anomaly detection)的定义有很多种,在孤立森林(iForest)中,异常被定义为“容易被孤立的离群点 (more likely to be separated)”,可以将其理解为分布稀疏且离密度高的群体较远的点。 在特征空间里,分布稀疏的区域表示事件发生在该区域的概率很低,因而可以认为落在这些区域里的数据是异常的。孤立森林是一种适用于连续数据(Continuous numerical data)的无监督异常检测方法,即不需要有标记的样本来训练,但特征需要是连续的。对于如何查找哪些点容易被孤立(isolated),iForest使用了一套非常高效的策略。在孤立森林中,递归地随机分割数据集,直到所有的样本点都是孤立的。在这种随机分割的策略下,异常点通常具有较短的路径。
直观上来讲,那些密度很高的簇是需要被切很多次才能被孤立,但是那些密度很低的点很容易就可以被孤立。这里参考下面的图进行说明。
在图(a)和图(b)中,可以看到,正常点
isolation tree (iTree)
定义:假设
给定
异常检测的任务是给出一个反应异常程度的排序,常用的排序方法是根据样本点的路径长度或异常得分来排序,异常点就是排在最前面的那些点。
Path Length
定义: 样本点
Anomaly Score
给定一个包含
其中
样本
其中,
由上图可以得到一些结论:
当
E(h(x))→c(n) 时,s→0.5 ,即样本x 的路径平均长度与树的平均路径长度相近时,则不能区分是不是异常。当
E(h(x))→0 时,s→1 ,即x 的异常分数接近1时,被判定为异常。当
E(h(x))→n−1 时,s→0 ,被判定为正常。
孤立树的特点
孤立森林作为孤立树的总体,将具有较短路径长度的点识别为异常点,不同的树扮演不同异常识别的专家。
已经存在的那些异常检测的方法大部分都期望有更多的数据,但是在孤立森林中,小数据集往往能取得更好的效果。样本数较多会降低孤立森林孤立异常点的能力,因为正常样本会干扰隔离的过程,降低隔离异常的能力。子采样就是在这种情况下被提出的。
swamping和masking是异常检测中比较关键的问题。swamping指的是错误地将正常样本预测为异常。当正常样本很靠近异常样本时,隔离异常时需要的拆分次数会增加,使得从正常样本中区分出异常样本更加困难。masking指的是存在大量异常点隐藏了他们的本来面目。当异常簇比较大,并且比较密集时,同样需要更多的拆分才能将他们隔离出来。上面的这两种情况使得孤立异常点变得更加困难。
造成上面两种情况的原因都与数据量太大有关。孤立树的独有特点使得孤立森林能够通过子采样建立局部模型,减小swamping和masking对模型效果的影响。其中的原因是:子采样可以控制每棵孤立树的数据量;每棵孤立树专门用来识别特定的子样本。
下面两张图说明了上述的现象。
iForest用于异常检测
基于iForest的异常检测包括两个步骤:训练阶段,基于训练集的子样本来建立孤立树;测试阶段,用孤立树为每一个测试样本计算异常分数。
训练阶段
在训练阶段,iTree的建立是通过对训练集的递归分隔来建立的,直到所有的样本被孤立,或者树达到了指定的高度。树的高度限制
子样本大小
评估阶段
在评估阶段,每一个测试样本的异常分数由期望路径长度
Example

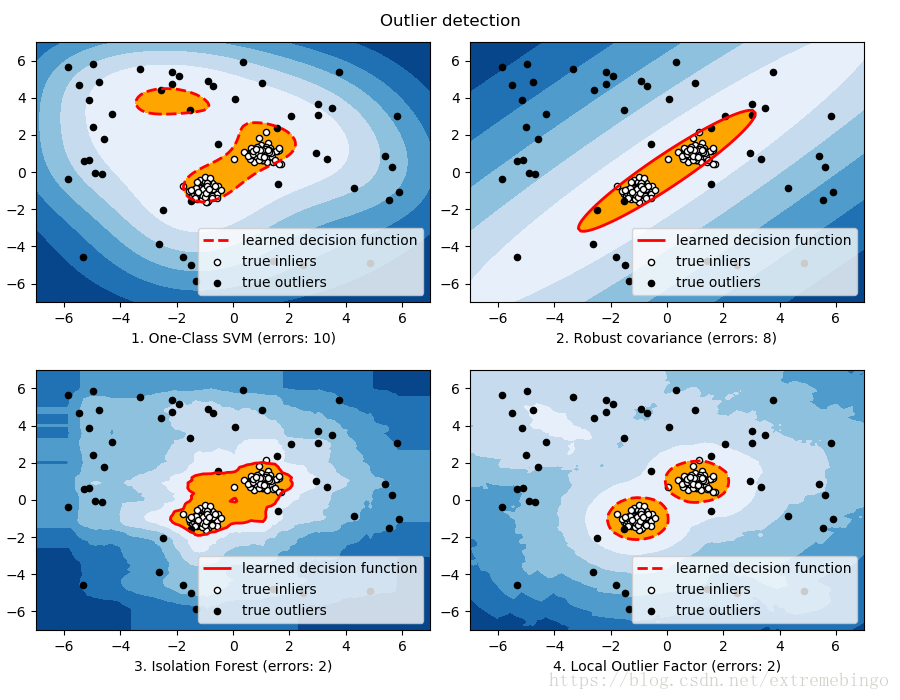
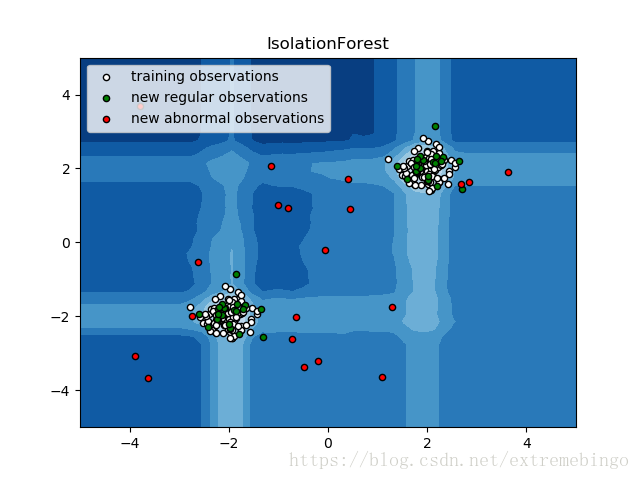
参考
[1] Liu, Fei Tony, Kai Ming Ting, and Zhi-Hua Zhou. “Isolation forest.” Data Mining, 2008. ICDM’08. Eighth IEEE International Conference on. IEEE, 2008.
[2] Liu, Fei Tony, Kai Ming Ting, and Zhi-Hua Zhou. “Isolation-based anomaly detection.” ACM Transactions on Knowledge Discovery from Data (TKDD) 6.1 (2012): 3.
[3] Preiss, Bruno R. Data structures and algorithms with object-oriented design patterns in Java. John Wiley, 2000.
[4] https://www.jianshu.com/p/5af3c66e0410?utm_campaign=maleskine
[5] http://scikit-learn.org/stable/modules/generated/sklearn.ensemble.IsolationForest.html