Isolation Forest
链接
异常点定义为那些 “容易被孤立的离群点” —— 可以理解为分布稀疏,且距离高密度群体较远的点。

常见的场景包括:网络安全中的攻击检测、金融交易欺诈检测、疾病侦测、**噪声数据过滤(数据清洗)**等。
与其他算法的区别
大多数基于模型的异常检测算法会先 ”规定“ 正常点的范围或模式,如果某个点不符合这个模式,或者说不在正常范围内,那么模型会将其判定为异常点。

训练过程
孤立森林是类似与集成算法,建立很多棵树,然后最后平均所有树的结果,成为我们最终的结果。
建立一棵树的过程
1.在训练数据中随机选择特征,作为一颗孤立树的根节点。
2.随机指定一个维度。在当前的特征内,随机产生一个切割点p
3.此时将当前数据空间切分为2个子空间,一个是所选维度大于p的点,一个是小于p的点。
4.在两个子空间内在递归2 3 步,不断构造新的叶子节点,直到叶子节点上只有一个数据(无法再继续切割)或者达到了我们我设置的树的高度。
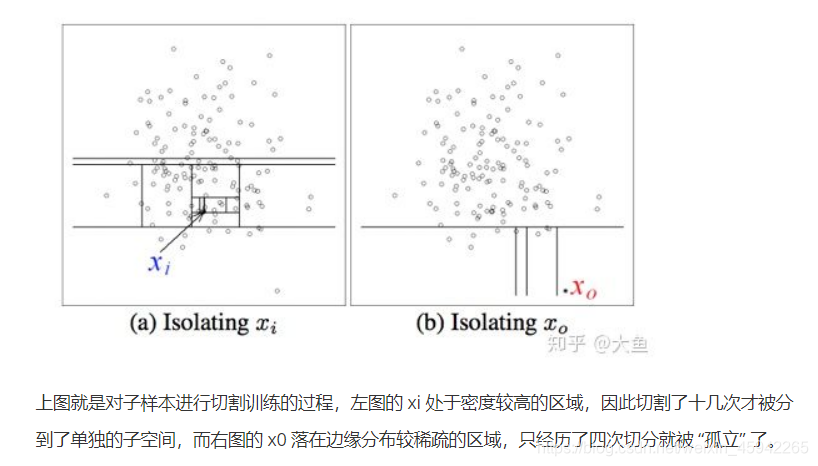
整合全部孤立树的结果
由于切割过程是随机的,我们是随机的选取特征进行分割,所以需要集成的方法也就是集合所有树的结果来使结果收敛,即反复的从头开始切,然后计算每次切分结果的平均值。
例子

武林外传有很多很多人物,即全部样本为x,我们选取子样本即其中9个人物建立其中一颗孤立树。把这9个人作为一个子样本放入一颗孤立树的根节点,
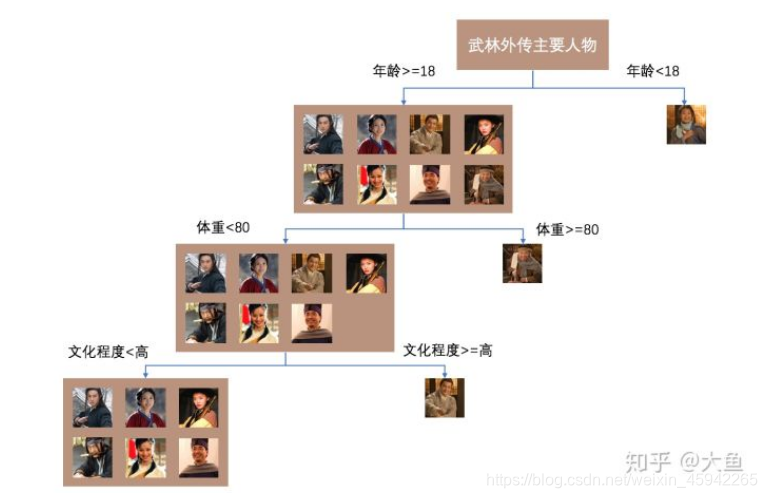
然后随机选择特征,随机选择一个切割点p,大于18和小于18.。。

但看一棵树,莫小贝的异常程度最高。但是,他之所以最先被孤立出来,与随机选择到的特征顺序有关,所以我们通过对多棵树进行训练,来去除这种随机性,让结果尽量收敛。
https://www.pianshen.com/article/3092770169/