(作者:陈玓玏)
1. 为什么我们需要逻辑回归?
逻辑回归的基础是线性回归,但如果我们用线性回归可能会出现两个问题,第一个问题受Rachel_zhang的博客启发,描述如下:
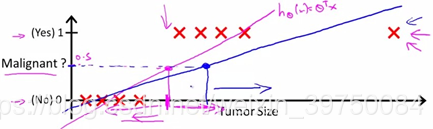
如果我们通过线性回归来预测癌症,特征是肿瘤的size。当数据点只有左边八个时,可以用粉红色的线来做线性回归,回归的结果是
hθ(x),当结果值大于0.5时,我们可以认为样本属于正样本,反之属于负样本。但当样本增加后,也就是加入最右边的红色样本时,拟合的线性函数将会发生偏移,如果此时我们还以0.5作为分类阈值,那么判断为癌变的肿瘤大小要增大不少。
第二个问题是我自己的拙见,认为这里所举的线性回归的例子能够比较好地拟合到靠近[0,1]的范围,但是也有可能偏移这个范围,导致阈值不容易确定。
因此我们需要逻辑回归来解决以上问题,通过激活函数将线性回归的结果转换到[0,1]区间,转换为概率值。
2. 逻辑回归为什么用sigmoid这个激活函数?
这个问题可以反向来思考,我们可以看看用
p来表示
y是什么情况。先写出逻辑回归的表达式:
hθ(X)=y^=i=1∑mxiθi
p=(1+e−y^)1
从
y转换成
p的过程使用的就是 sigmoid激活函数,从以上式子可以得到:
y^=ln1−pp
其中,
p表示样本预测为正样本的概率,
1−p表示样本预测为负样本的概率。也就是说激活函数会把线性回归得到的y值与一个比率值等价起来,
y越大,表示样本属于正样本的概率相比属于负样本的概率越大。这样就不需要辛苦地去找一个阈值,截断地说属于你得了恶性肿瘤或者没得,而是说你有多大可能性得了恶性肿瘤。
3. 逻辑回归原理推导
和线性回归一样,我们需要求解逻辑回归的参数,就需要先写出其代价函数。逻辑回归的代价函数采用的是对数损失函数,其得来的过程如下:
在统计学中,估计参数采用的是极大似然估计,需要先知道样本的概率分布情况,那么在逻辑回归中我们可以认为样本是伯努利分布(n重二项分布)。
P{Y=n}={p,1−p,if n =1if n =0
似然函数:
L(θ∣Y)=P(Y=y∣θ)=i=1∏mP(yi=1)yiP(yi=0)(1−yi)
将概率值代入似然函数,得到:
L(θ∣Y)=i=1∏mhθ(xi)yi(1−hθ(xi))(1−yi)
令代价函数为负的似然函数的对数(取对数为了求导方便,因为乘积求导很麻烦),那么使得似然函数(似然函数是后验概率的乘积,这篇文章:https://www.cnblogs.com/zhizhan/p/4113614.html 的例子很好,就是知道你已经头痛了,通过你的各种表现,即你的病理特征,来判断你是因为哪种原因感冒的,判断正确的样本越多,后验概率乘积越大。)最大的参数值就是使得代价函数最小的参数值。因此逻辑回归采用的是对数损失函数。具体的公式如下:
logL(θ∣Y)=i=1∑m[yiloghθ(xi)+(1−yi)log(1−hθ(xi))]
因为似然函数要最大化,而代价函数要最小化且需要求平均,因此转换成以下形式:
−m1logL(θ∣Y)=−m1i=1∑m[yiloghθ(xi)+(1−yi)log(1−hθ(xi))]
最终损失函数为:
J(θ)=−m1i=1∑m[yiloghθ(xi)+(1−yi)log(1−hθ(xi))]
yi是样本的真实值,
hθ(x−i)是样本的预测值。知道代价函数之后,我们就能对参数进行求解了。依旧是根据以下公式更新:
θi=θi−α∂θi∂J(θ)
判断学习率的方法就是看是否每一次
J(θ)都在下降。
4. 二分类及多分类
通过逻辑回归可以实现二分类,也可以实现多分类。实现二分类时,我们只需要判断每个样本属于正样本的概率有多大,那么多分类怎么做呢?很简单,有两种方法,一种是套用现在的框架,我们可以每次都将其中一个类作为正样本,其他类统一归到负样本,然后重复多次,取多轮预测中为正样本的概率最大的那个分类作为该样本的分类结果即可。如下图所示:
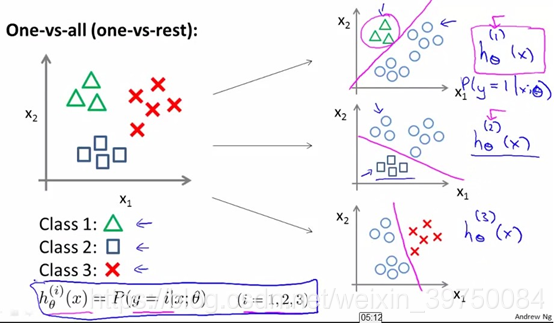
另外一种方法需要改变激活函数,使用softmax函数,这个函数可以作为多分类,其公式为:
softmax(xi)=∑i=1Kexiexi
其中
K为总的类别数,其实本质和上面是一样的,无非就是当第
i类作为正样本时,其他样本也能求得概率,而不需要重复计算多次罢了。
5. 正则化
正则化的作用是什么?防止过拟合,那过拟合的意思是什么?看图
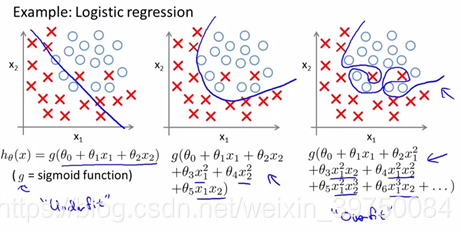
虽然图中公式用的变量是多项式变量,但其实和我们平时用的变量是一样的,那么一句话,过拟合就是过分精确地去拟合样本,甚至是拟合了噪声,导致我们学习到了一些不必要的信息。比如一些重要程度很低的特征,像手指纤细,在某个样本集中,手指纤细的都是女生,手指更粗一些的都是男生,并不影响其准确率,但是当样本扩大到更大的范围时,手指纤细也可能是男生,但我们也会把他们归类于女生,导致准确率急剧下降。
欠拟合就是拟合不够,特征太少不足以正确分类。比如留长发的男生很少,但是我们在分类时只根据头发长度来区分男女,那么我们就可能把留长发的男生识别为女生,如果再加入喉结、胡子等特征,我们才能区分得更准确些。
因此,过拟合一个可能的原因是特征冗余、而欠拟合可能的原因是特征太少。正则化就是用来解决过拟合的一种非常有效的手段。
正则化实际的意义就是两个:
1) 去掉多余的特征(通常L1正则化就会让某些权重减小到0,从而减少特征数量);
2) 降低部分特征的权重(通常L2正则化就会让某些特征权重接近0)。
在代价函数中加入正则项后,线性回归的代价函数变为:
J(θ)=2m1[i=1∑m(hθ(xi)−yi)2+λj=1∑nθj2]
θ0是没有惩罚项的。对加入了正则项的损失函数求导,除了
θ0之外,其他参数结果如下:
θj=θj−αm1[i=1∑m(hθ(xi)−yi)xj+λθj]
合并一下:
θj=θj(1−mαλ)−αm1i=1∑m(hθ(xi)−yi)xj
假设我们在建模时用
10W个样本,并且取惩罚因子
λ=107,取学习率
α=0.01,那么参数更新的第一项就变为0了,而第二项本身就是一个很小的值,则参数也会接近0,因此,惩罚因子增大,会去掉一些特征或降低它们的影响,从而减少过拟合,而惩罚因子过大,可能会导致几乎所有特征接近0。
最小二乘法的正则:

从这个公式能看出,
λ过大,几乎所有的
θ都会变为0,而
λ设置合适时,权重较低的
θ会接近0,从而避免过拟合。
参考文献:
- https://blog.csdn.net/abcjennifer/article/details/7716281
- https://blog.csdn.net/saltriver/article/details/63683092
- https://blog.csdn.net/luanpeng825485697/article/details/78957577