版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/yyoc97/article/details/80489977
记录Logistic的一次详尽公式推导及使用
简介
文章针对像我一样数学弱又想学好机器的朋友们!手写推导过程尽可能的详尽。后面还有案例实现,希望也能帮助大家理解。
Logistic 回归模型和线性回归一样,都是 y = wx + b ,其中 x 可以是一个多维特征,唯一不同的地方在于Logistic 回归会对 y 作用一个Logistic 函数,将其变为一种概率结果,Logistic 函数作为逻辑回归核心,也称谓sigmod函数。基本公式
下面公式不好表示,就用图片形式展示了。
假设:
代价函数
效果的好坏需要定义一个代价函数来反映。如果将线性回归的代价函数(平方误差等)用在非线性中,那J(θ)很有可能就是非凸函数,即存在很多局部最优解,但不一定是全局最优解。我们希望构造一个凸函数,也就是一个碗型函数做为逻辑回归的代价函数。联想到高数的似然方程,按照求最大似然函数的方法,定义逻辑回归似然函数:
问题转换为求L(θ)的极值。其中,m为样本总数,y(i)表示样本的类别,x(i)表示第i个样本,需要注意的是θ为多维向量,x(i)也是多维向量。下面利用似然函数常处理的方法,两边去log将乘法运算转换为加法。
然后就是求导取极值(如果存在)。求导过程
根据公式:
我们可以把logL(θ)看成3部分处理。
最终求得:
代码实现
最后我们用代码实现来加深下这个公式的理解。自己实现一个梯度下降或者上升的方法。
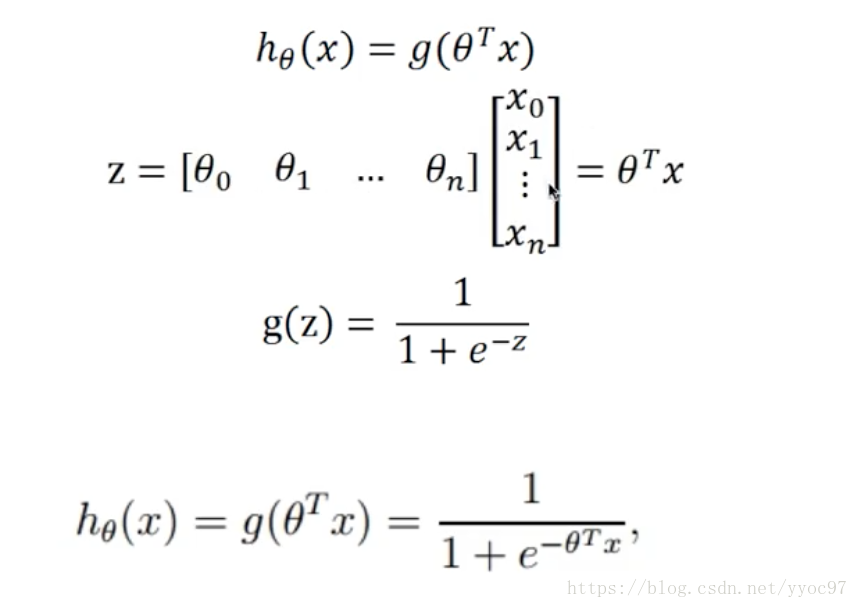
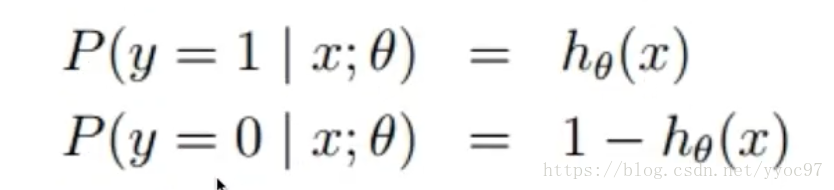

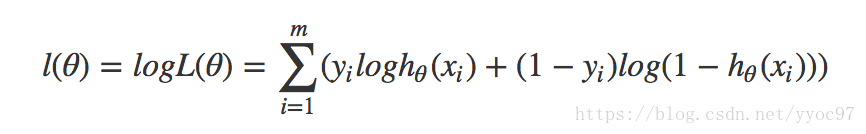
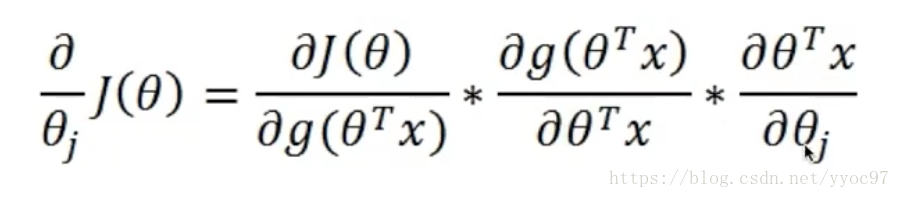
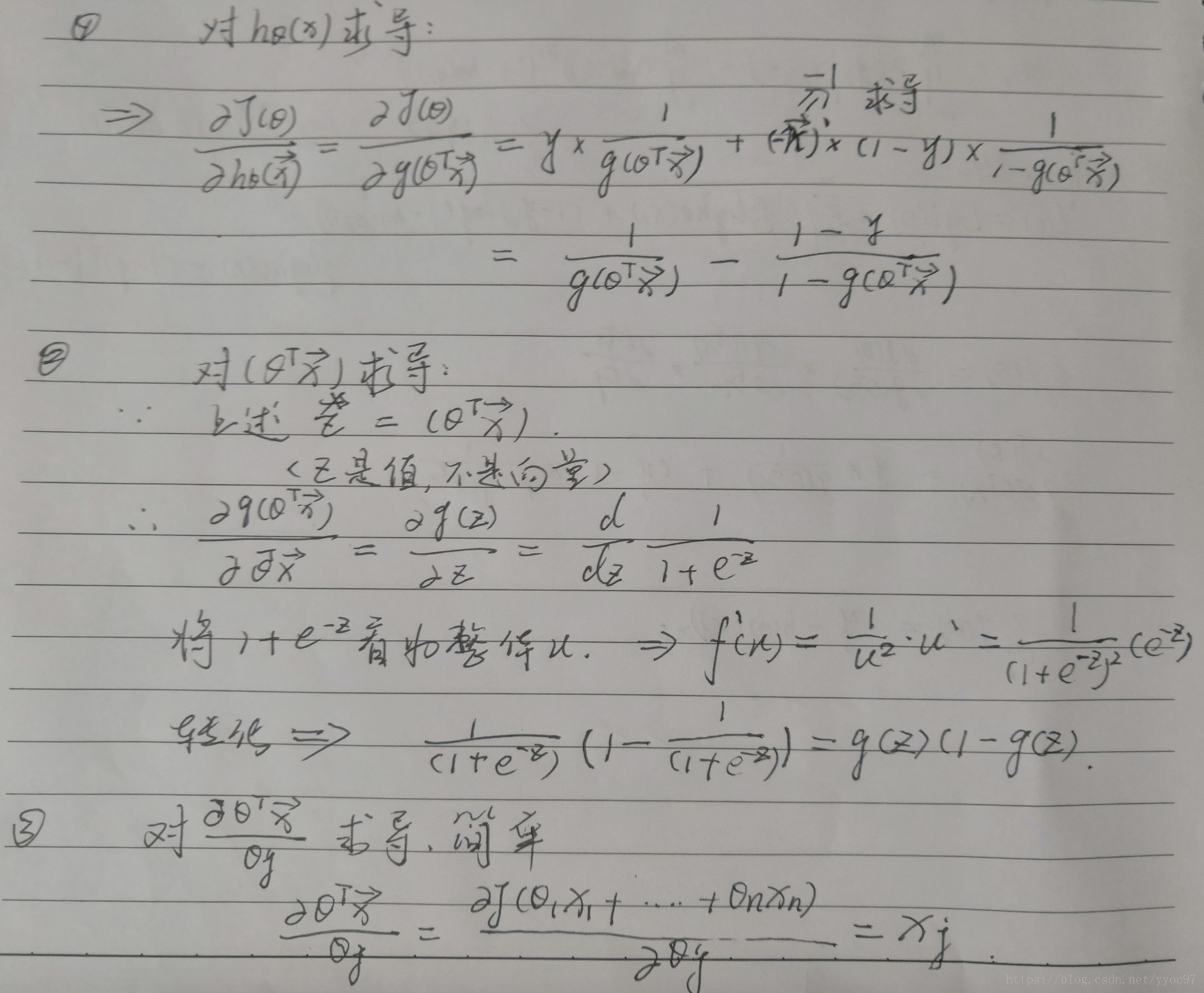
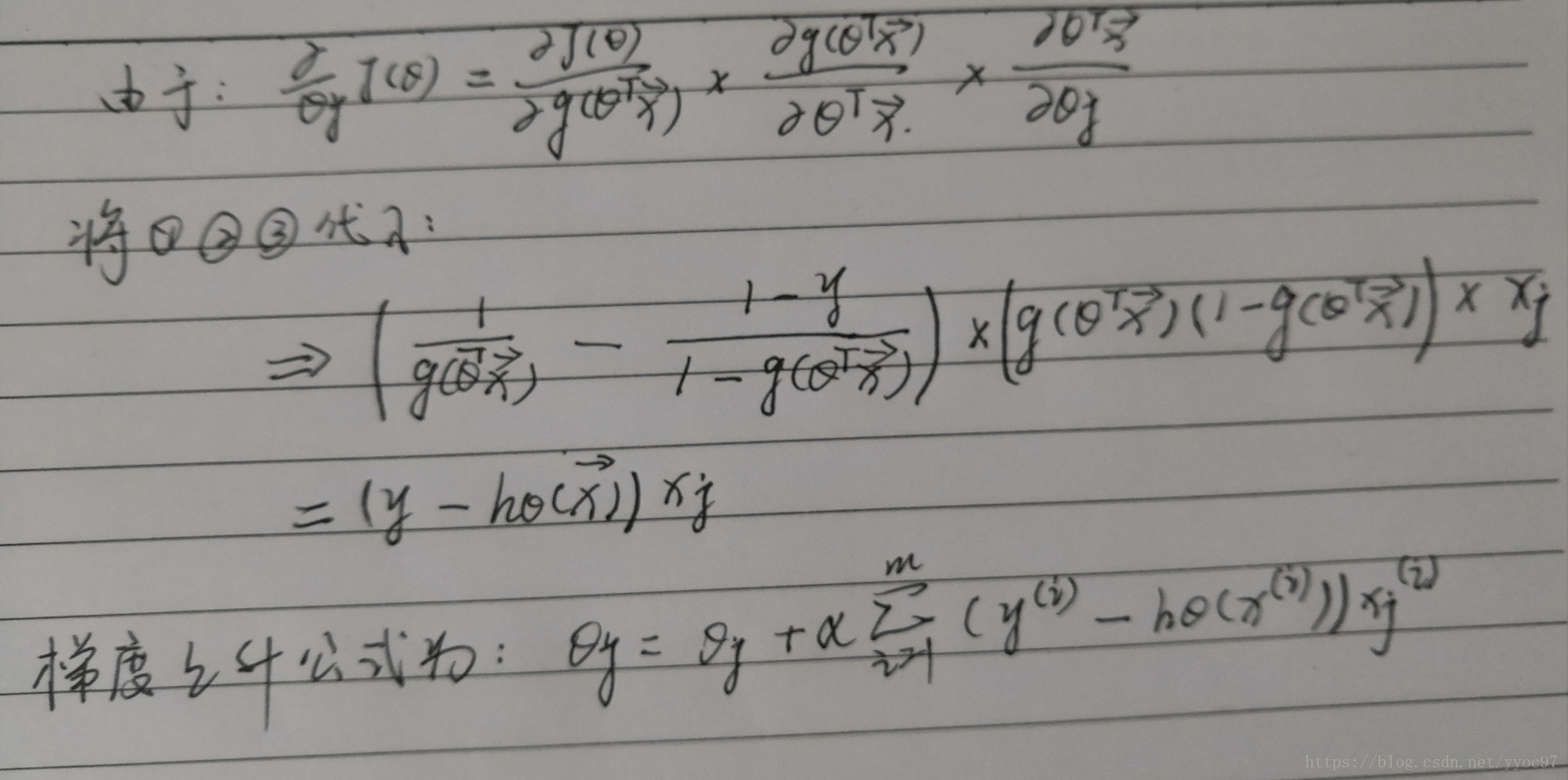
import numpy as np;
from tensorflow import sigmoid
# 梯度上升方法
def gradAscent(dataMatIn , classLabels):
dataMatrix = np.mat(dataMatIn) #转换成numpy 的mat
labelMat = np.mat(classLabels).transpose() #转换成numpy的mat格式,再装置
m,n = np.shape(dataMatrix); #获取dataMatrix的行列数
alpha = 0.01 #更新速率
maxCycles = 5000 #迭代次数
weights = np.ones((n,1)) #初始化权重矩阵
for i in range(maxCycles):
h = sigmoid(dataMatrix * weights) # 计算预测值h
error = labelMat - h
# 我们刚才推导的公式!
weights = weights + alpha * dataMatrix.transpose() * error
return weights.getA() #将矩阵转换为数组,返回权重数组