Python爬虫-利用Scrapy抓取豆瓣电影top250数据
简介
一段自动抓取互联网信息的程序
Python爬虫架构:
- 调度端:用来启动、停止、和监视爬虫
- URL管理:对等待爬取和已经爬取的URL进行管理,简单来说就是为后续模块提供可供爬取的URL
- 网页下载器:将供爬取的URL的网页下载下来,组成供解析的字符串
- 网页解析器:将字符串解析
scrapy抓取步骤:
- 新建项目 (Project) :新建一个新的爬虫项目
- 明确目标(Items):明确你想要抓取的目标
- 制作爬虫(Spider):制作爬虫开始爬取网页
- 存储内容(Pipeline):设计管道存储爬取内容
新建项目(抓取豆瓣电影top250数据)
打开DOM命令窗口,进入D盘(我是把新建项目文件放置在D盘),输入scrapy startproject douban,新建名称为 “douban” 的爬虫项目

开启PyCharm查看新建的爬虫项目
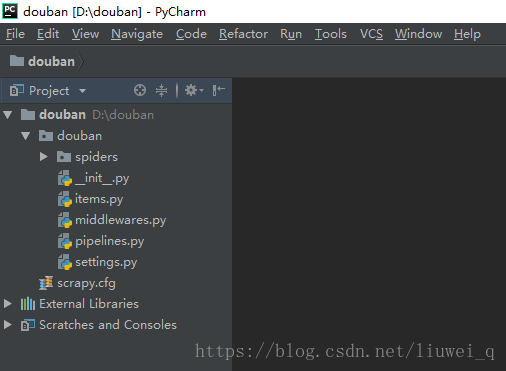
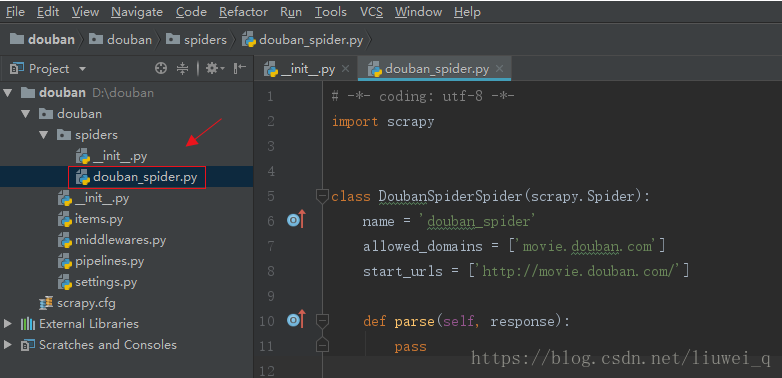
新建spider 爬虫主文件
- 输入命令:cd douban\douban\spiders,进入spiders文件目录下
输入命令:scrapy genspider douban_spider movie.douban.com, 新建名称为“douban_spider”的文件,其中“movie.douban.com”为域名(
douban_spider文件名称可以另取,该文件用于编写XPath和正则表达式)
PyCharm上自动刷新显示新建的爬虫文件

明确目标(明确需要抓取的网页信息)
打开items.py文件,在类 DoubanItem下定义抓取目标,代码如下:
# -*- coding: utf-8 -*-
# Define here the models for your scraped items
#
# See documentation in:
# https://doc.scrapy.org/en/latest/topics/items.html
import scrapy
class DoubanItem(scrapy.Item):
# define the fields for your item here like:
# name =scrapy.Field()
#序号
serial_number=scrapy.Field()
#电影名称
movie_name=scrapy.Field()
#电影介绍
introdue=scrapy.Field()
#星际
star=scrapy.Field()
#电影的评论数
evaluate=scrapy.Field()
#电影的描述
describe=scrapy.Field()
pass修改setting的USER_AGENT值
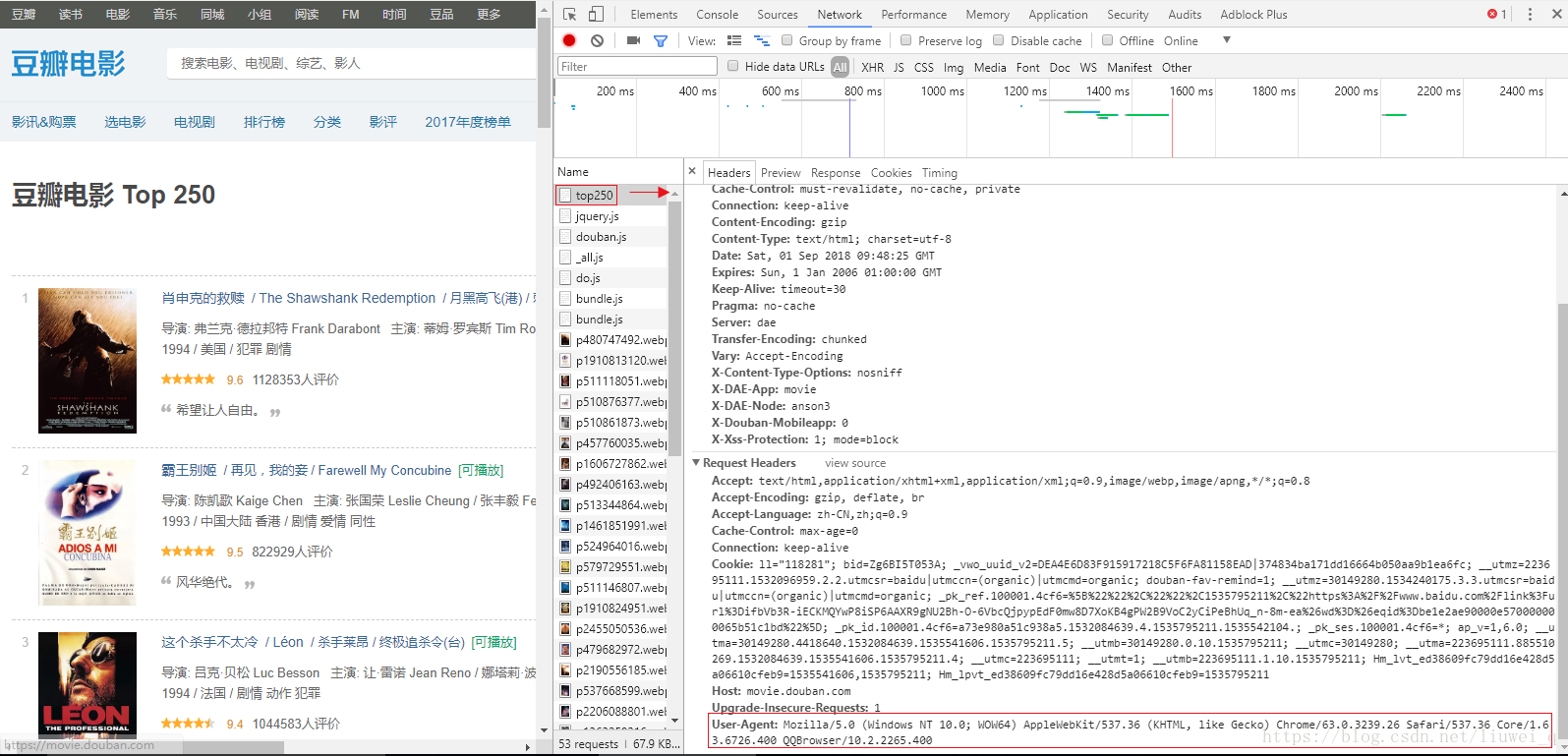
- 进入豆瓣网页(https://movie.douban.com/top250)
- 按F12,点击 Network ,再按F5刷新网页
- 点击top250,找到 User-Agent 项,复制其内容
- 打开 settings 文件,去掉USER_AGENT这行的注释,清空原内容,粘贴上述从浏览器获取的内容
制作爬虫(douban_spider文件编写),代码如下:
# -*- coding: utf-8 -*-
import scrapy
from douban.items import DoubanItem
class DoubanSpiderSpider(scrapy.Spider):
# 爬虫名字
name = 'douban_spider'
# 允许的域名
allowed_domains = ['movie.douban.com']
# 入口URL
start_urls = ['https://movie.douban.com/top250']
# 默认解析方法
def parse(self, response):
# 循环电影的条目
movie_list = response.xpath("//div[@class='article']//ol[@class='grid_view']/li")
for i_item in movie_list:
# item文件导进来
douban_item = DoubanItem()
# 写详细的xpath,进行数据的解析
douban_item['serial_number'] = i_item.xpath(".//div[@class='pic']//em/text()").extract_first()
douban_item['movie_name'] = i_item.xpath(".//div[@class='info']/div[@class='hd']/a/span[1]/text()").extract_first()
content = i_item.xpath(".//div[@class='info']/div[@class='bd']/p[1]/text()").extract()
for i_content in content:
# 去掉空格
content_s = "".join(i_content.split())
douban_item["introdue"] = content_s
douban_item['star'] = i_item.xpath(".//span[@class='rating_num']/text()").extract_first()
douban_item['evaluate'] = i_item.xpath(".//div[@class='star']/span[4]/text()").extract_first()
douban_item['describe'] = i_item.xpath(".//p[@class='quote']/span/text()").extract_first()
# 需要将数据yield到pipelines里面去
yield douban_item
# 解析下一页的规则,取的后一页的xpath
next_link = response.xpath("//span[@class='next']/link/@href").extract()
if next_link:
next_link = next_link[0]
yield scrapy.Request("https://movie.douban.com/top250"+next_link,callback=self.parse())
运行项目
一、通过命令运行
- 输入命令:cd douban\douban\spiders,进入根目录spiders文件下
- 输入命令:scrapy crawl douban_spider,运行spider文件
结果出现报错“SyntaxError: invalid syntax”(原因是manhole.py文件里的async字段变成了关键字,需要手动修改下名称)- 解决方案:进入manhole.py文件存放目录\Python37\Lib\site-packages\twisted\conch,打开manhole.py文件,修改async为shark(也可以修改为其它名称)
- 再次输入命令:scrapy crawl douban_spider,运行spider文件
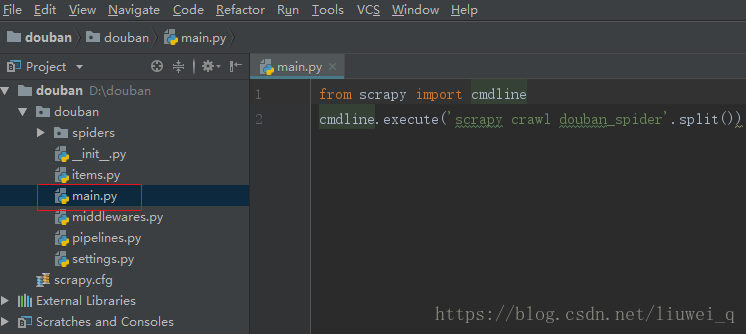
二、通过启动文件运行
- 在douban文件目录下新建启动文件 main.py (
文件名称可以另取) 打开main文件,编写代码如下:
from scrapy import cmdline cmdline.execute('scrapy crawl douban_spider'.split())
3.运行main文件,查看结果