版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/u012535605/article/details/80669848
上一篇爬虫文章记录了利用scrapy爬去西安天气数据,本文主要是记录在学习中利用scrapy爬去豆瓣top250的电影并进行分析数据过程。
1.建立一个爬虫项目
scrapy startproject douban2.在spider中建立douban爬虫文件
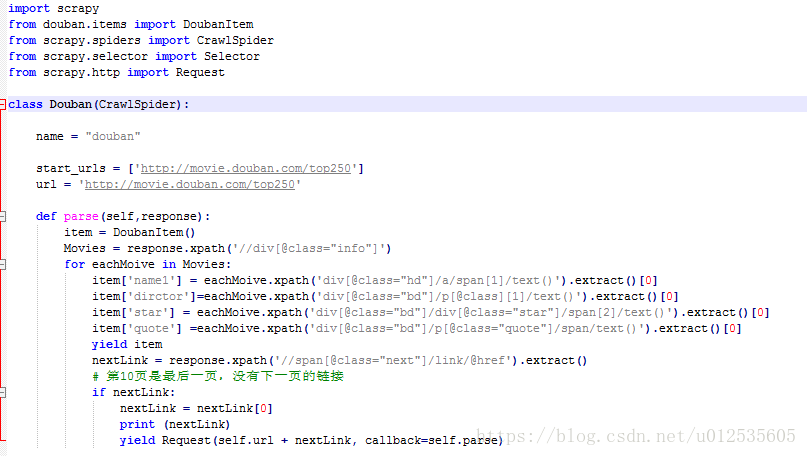
3.配置items.py文件
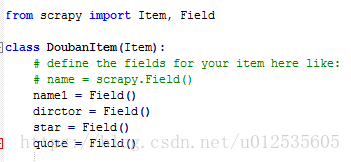
4.配置settings.py文件
USER_AGENT换成自己的电脑信息
5.开始爬虫
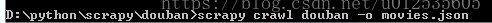
这是会在屏幕出现如图所示:说明爬虫成功

7.利用python进行数据处理
1.读数据

2.常规统计
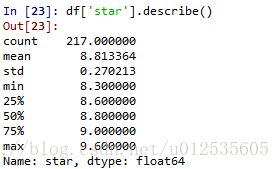
3.对quote进行分词处理并利用词云展示
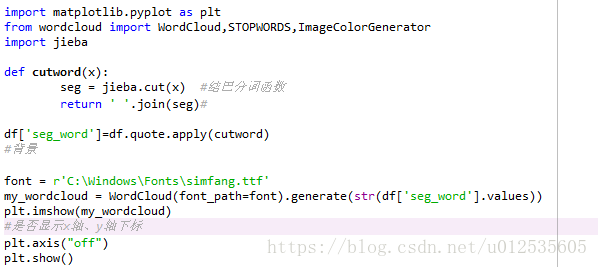

电影、世界、人生、我们、永远、上帝、爱情、超越为经常出现的词
至此利用scrapy爬取数据并利用python预处理基本完成,后续学习更深入的知识,补充并完善自己的对爬虫知识的理解