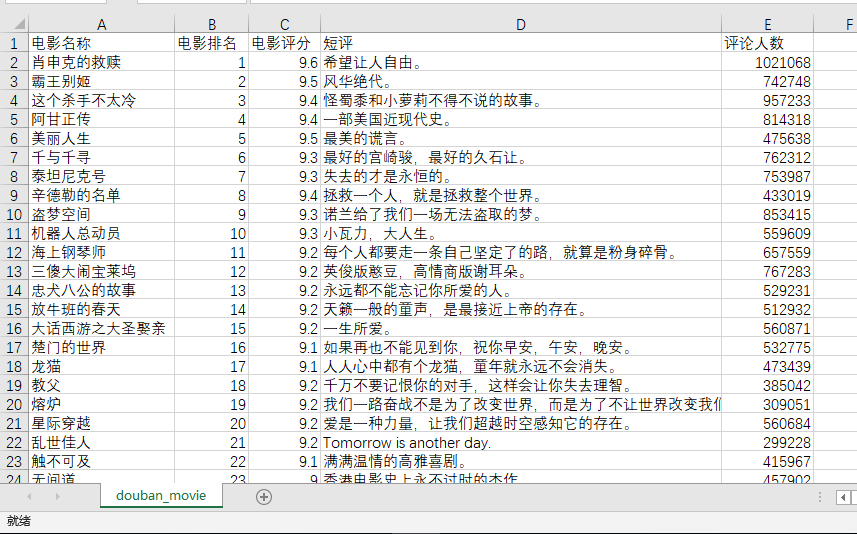
【前言】
本文从豆瓣网爬取前250部电影,并以CSV格式下载至电脑。本人才疏学浅,如有不足之处,还请各位大神指正。
【用到的软件包和知识点】
requests:下载网页
BeautifulSoup4:解析网页,提取所需数据
re:匹配正则表达式
pandas:将数据转化为data frame, 再输出为csv格式
【思路】
采用divide-and-conquer方法,先对一个网页进行分析和抓取,再用循环,应用于多个网页。
先从第一页开始,网页是 https://movie.douban.com/top250?start=
第二页网址是 https://movie.douban.com/top250?start=25&filter=
第三页网址是 https://movie.douban.com/top250?start=50&filter=
以此类推,网页以每页25递增,末尾的‘&filter=’可以省略,不影响网页的读取。由此可得到所有网址的列表。
def make_url_list():
url_list = []
url = 'https://movie.douban.com/top250?start='
step = 25
for i in range(10):
res = url + str(i*step)
url_list.append(res)
return url_list
url_list = make_url_list()
我们再来查看网页的源代码:
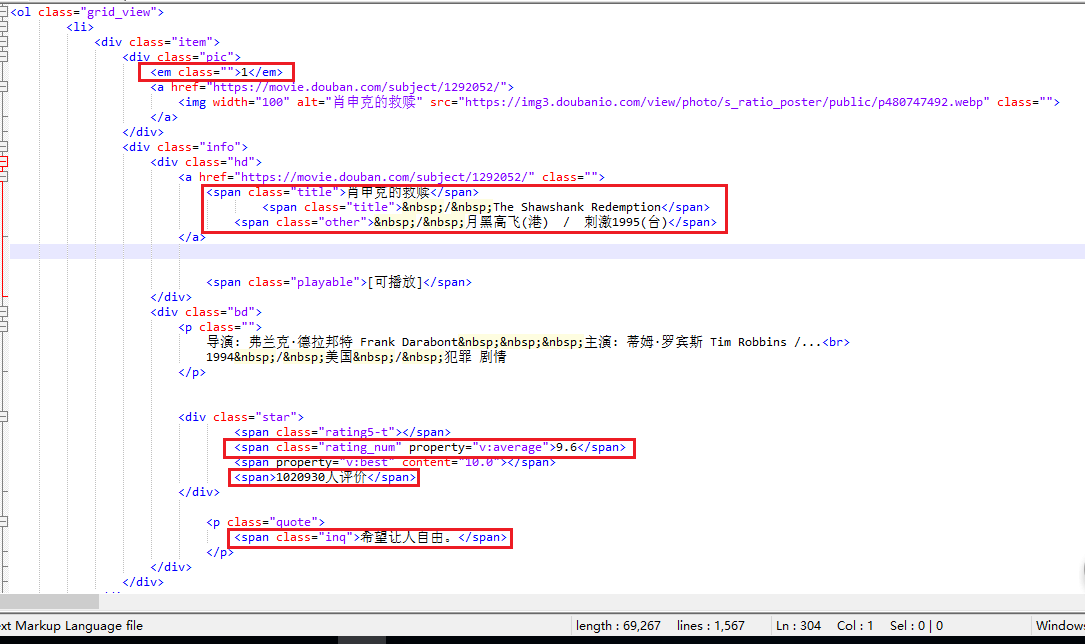
其中,电影排名、电影评分、短评的属性是唯一的,直接用BeautifulSoup里的select方法选出,生成list。
电影名称和评论人数的属性不是唯一的,因此,电影名称使用BeautifulSoup里的find选出第一个匹配值.
评论人数先用find找出所在的标签属性,再用正则表达式匹配倒数第一位数字.
短评属性唯一,但存在空值, 生成的list长度只有248,生成data frame时会报错。因此用find选出每次的匹配值,如果匹配值为空,返回‘无’,再加到list里,这样能生成长度为250的list。
【代码】
# -*- coding: utf-8 -*-
"""
Created on Fri Apr 27 15:37:41 2018
@author: ASUS
"""
import requests
from bs4 import BeautifulSoup
import pandas as pd
import re
# 获取所有网页的地址
def make_url_list():
url_list = []
url = 'https://movie.douban.com/top250?start='
step = 25
for i in range(10):
res = url + str(i*step)
url_list.append(res)
return url_list
url_list = make_url_list()
# 设定所需的5列数据:电影排名、电影名称、电影评分、评论人数、短评
total_rank_list = []
total_movie_name = []
total_movie_score = []
total_comment_num = []
total_quote_list = []
for url in url_list:
# 设定每次循环所需的5列数据:电影排名、电影名称、电影评分、评论人数、短评
movie_name = []
comment_num = []
quote_list = []
# 下载一个网页
res = requests.get(url)
res.raise_for_status()
res.encoding = 'utf-8'
'''获取一个网页包含的电影排名、电影名称、电影评分、评论人数、短评。其中,电影排名、
电影评分、短评的属性是唯一的,直接用BeautifulSoup里的select方法选出,生成list'''
soup = BeautifulSoup(res.text, "html.parser")
rank = soup.select('em')
rank_list = [i.getText() for i in rank]
score = soup.select('.rating_num')
movie_score = [j.getText() for j in score]
'''电影名称和评论人数的属性不是唯一的,电影名称使用BeautifulSoup里的find选出第一个匹配值,
评论人数先用find找出所在的标签属性,再用正则表达式匹配倒数第一位数字. 短评属性唯一,但存在空值,
因此用find选出每次的匹配值'''
movie_list = soup.find('ol',attrs={'class':'grid_view'})
for movie in movie_list.find_all('li'):
name = movie.find('span',attrs={'class':'title'}).getText()
movie_name.append(name)
comment_info = movie.find('div',attrs = {'class':'star'})
num = re.findall(r'\d+',str(comment_info))[-1]
comment_num.append(num)
quote = movie.find('span',attrs = {'class':'inq'})
if quote is not None:
quote_list.append(quote.getText())
else:
quote_list.append('无')
'''将每次循环得到的列表加到总列表里'''
total_rank_list.extend(rank_list)
total_movie_name.extend(movie_name)
total_movie_score.extend(movie_score)
total_comment_num.extend(comment_num)
total_quote_list.extend(quote_list)
# 用pandas输出为csv格式的文件
data = {'电影排名':total_rank_list,'电影名称':total_movie_name,\
'电影评分':total_movie_score,'评论人数':total_comment_num,\
'短评':total_quote_list}
df = pd.DataFrame(data)
df.to_csv('douban_movie.csv',index=False)