主要功能
1.利用lxml爬取豆瓣电影top250https://movie.douban.com/top250
2.用xpath确定所爬取数据的位置
3.获取数据,将数据写到txt文档中保存
实现步骤
1.网页分析,进入网站(本文使用的是谷歌浏览器)
2.按F12打开开发者工具,找到Elements,进行网页内容的分析
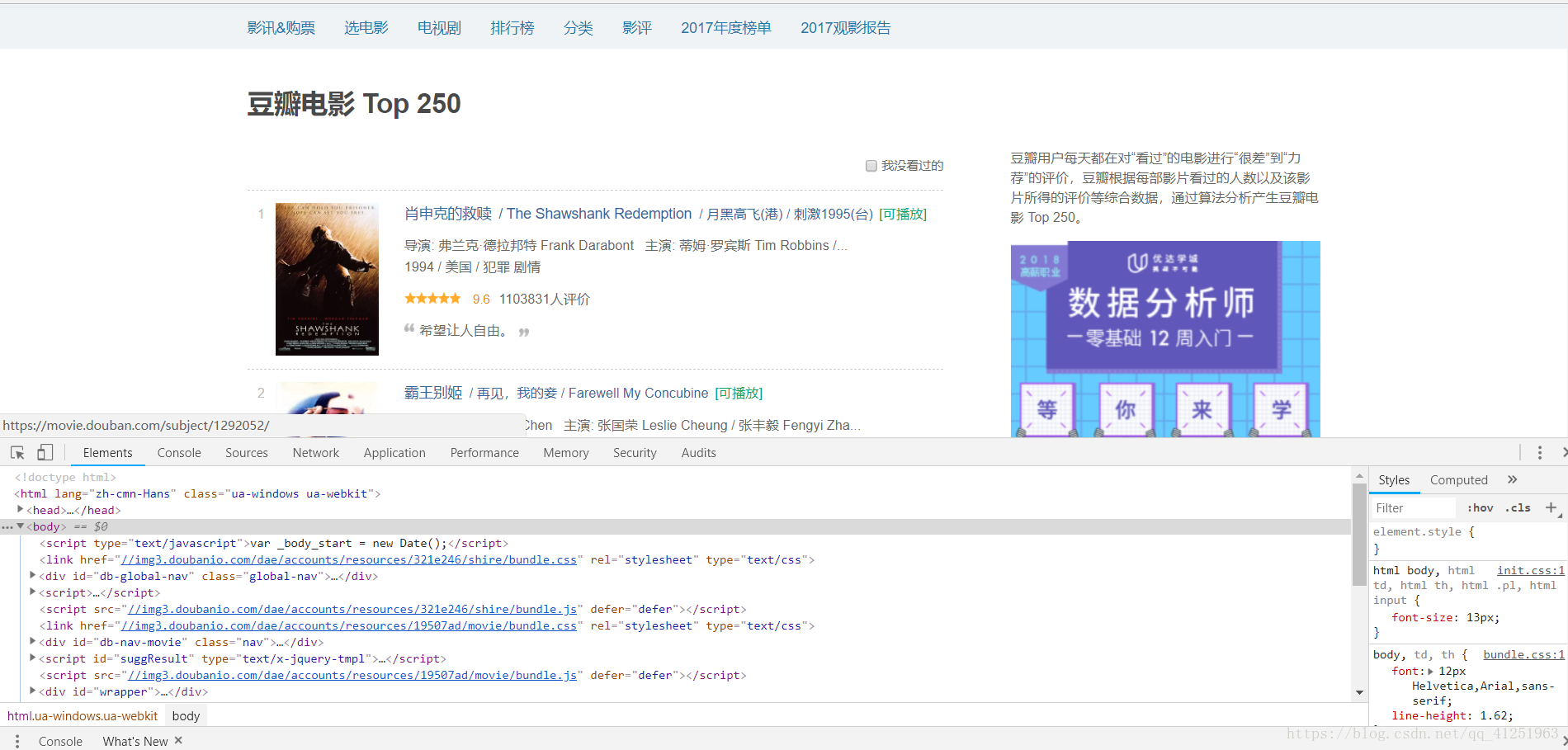
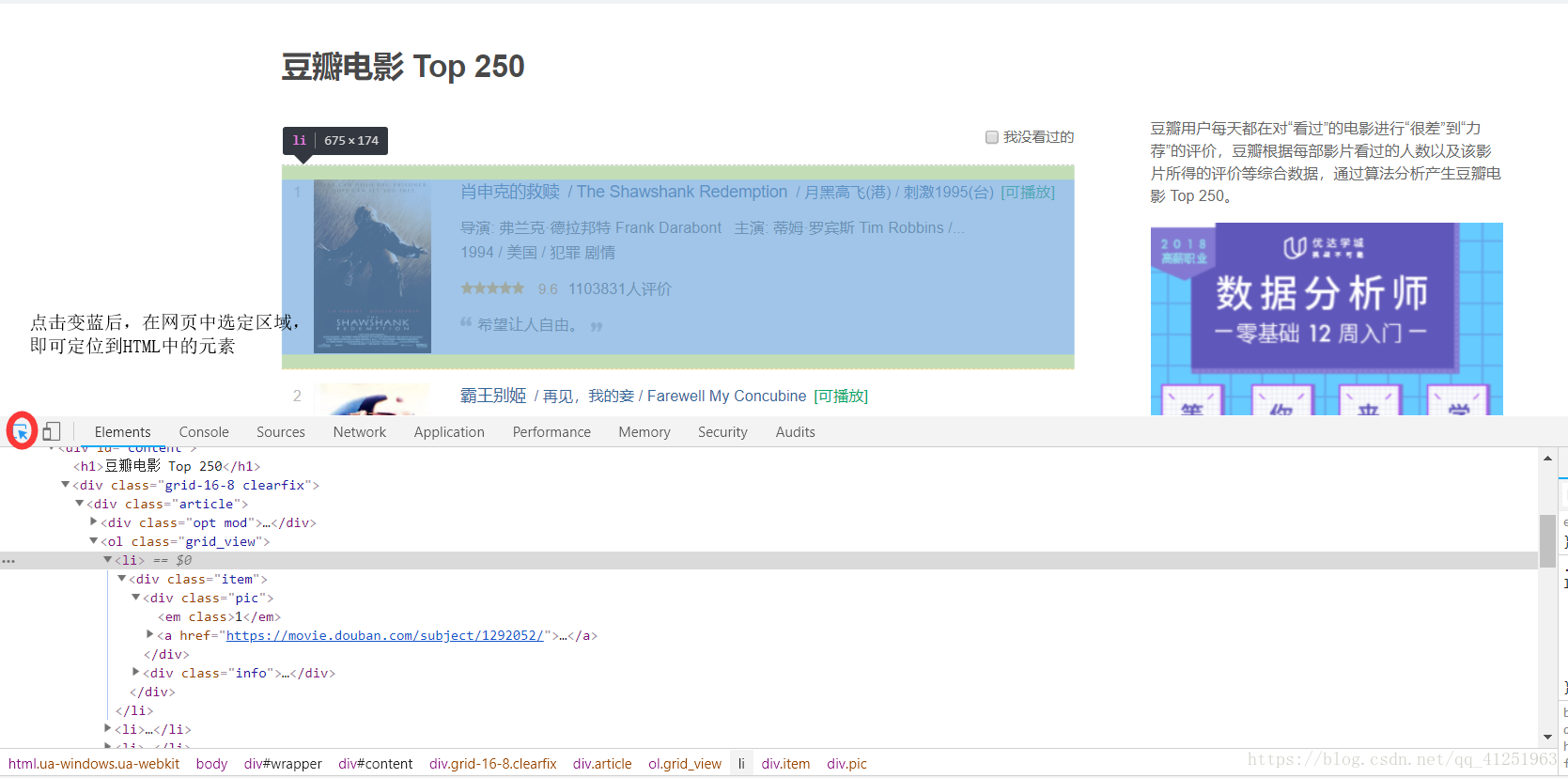
3.我们发现,网页里面有很多<li>...</li>标签,而且每一个标签里面都有一个电影的信息。我们想要的就是标签里面的文字信息。
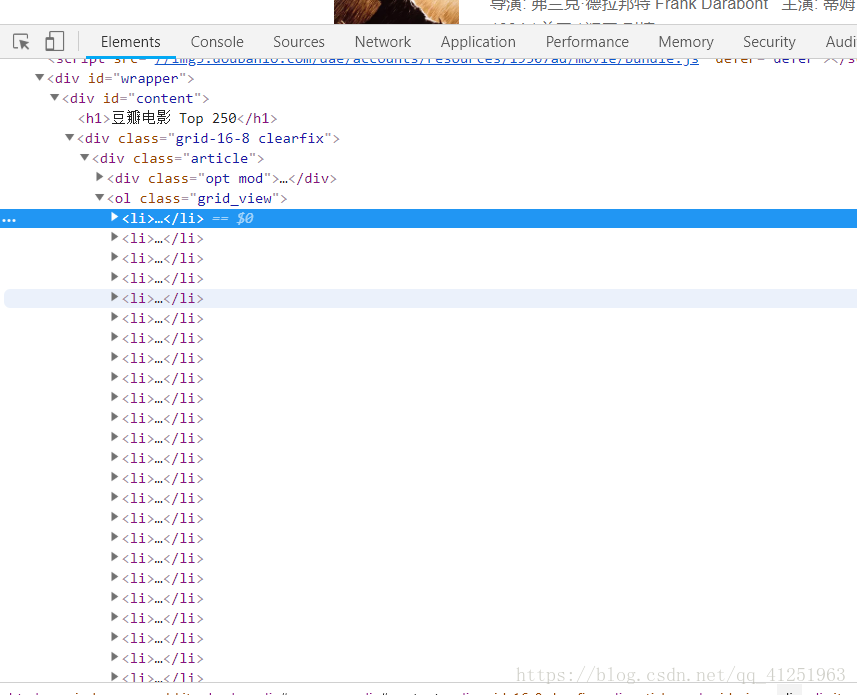
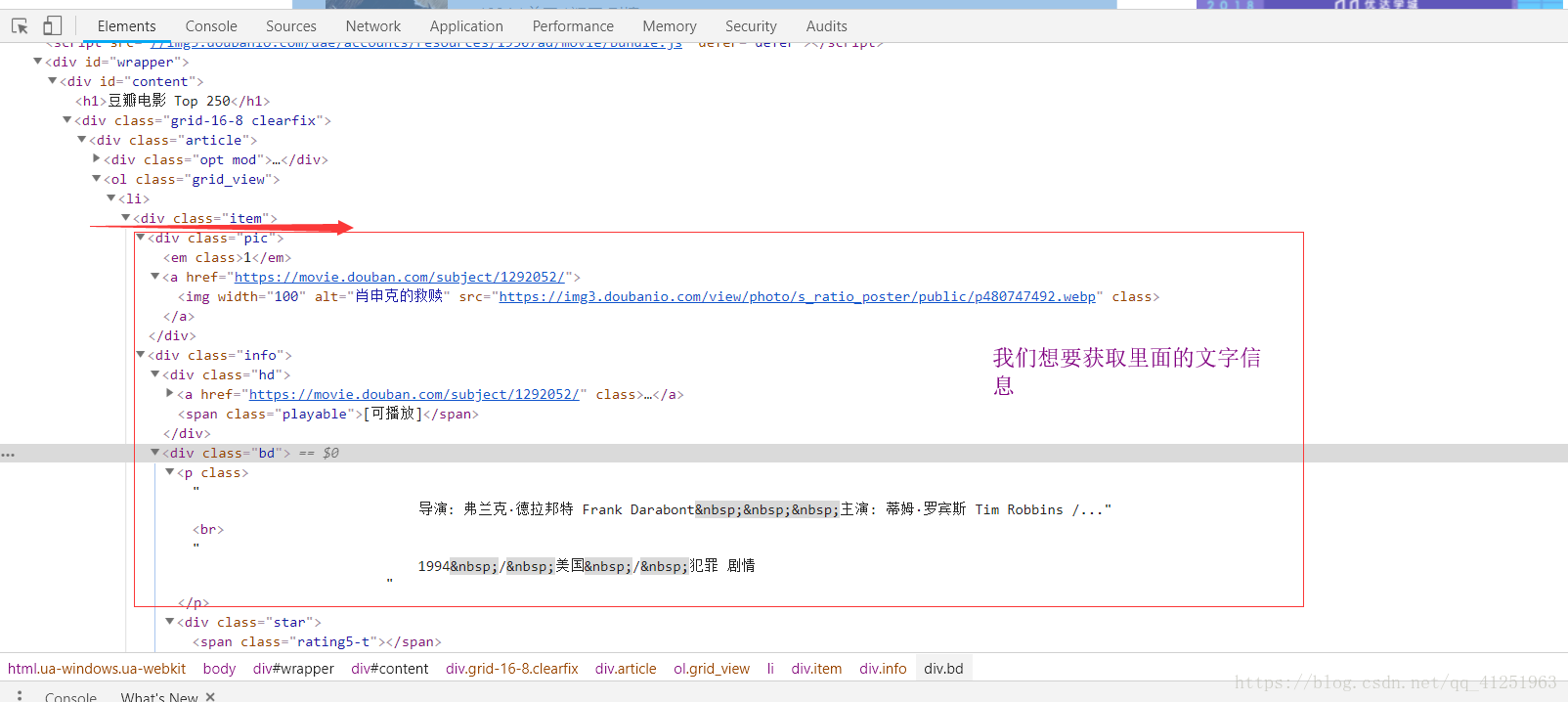
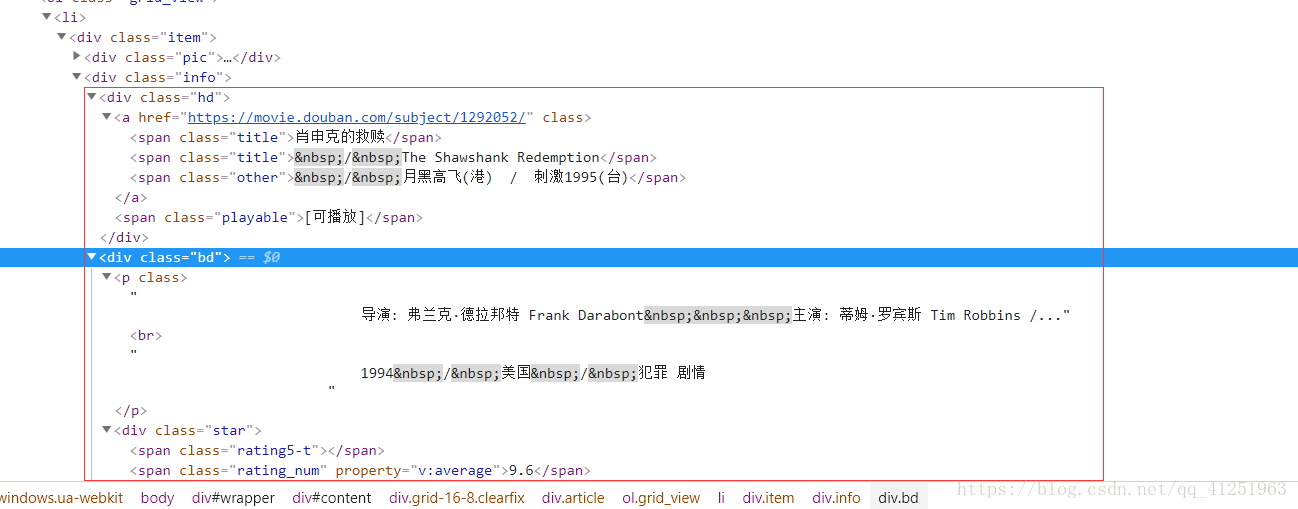
4.所有的信息都在class属性为info的div标签里,可以先把这个节点取出来 //*[@id=”content”]/div/div[1]/ol
这里我们介绍一下xpath的语法格式:
XPath 使用路径表达式在 XML 文档中选取节点。节点是通过沿着路径或者 step 来选取的。
下面列出了最有用的路径表达式:
| 表达式 | 描述 |
|---|---|
| nodename | 选取此节点的所有子节点。 |
| / | 从根节点选取。 |
| // | 从匹配选择的当前节点选择文档中的节点,而不考虑它们的位置。 |
| . | 选取当前节点。 |
| .. | 选取当前节点的父节点。 |
| @ | 选取属性。 |
使用实例
| 路径表达式 | 结果 |
|---|---|
| /bookstore/book[1] | 选取属于 bookstore 子元素的第一个 book 元素。 |
| /bookstore/book[last()] | 选取属于 bookstore 子元素的最后一个 book 元素。 |
| /bookstore/book[last()-1] | 选取属于 bookstore 子元素的倒数第二个 book 元素。 |
| /bookstore/book[position()<3] | 选取最前面的两个属于 bookstore 元素的子元素的 book 元素。 |
| //title[@lang] | 选取所有拥有名为 lang 的属性的 title 元素。 |
| //title[@lang=’eng’] | 选取所有 title 元素,且这些元素拥有值为 eng 的 lang 属性。 |
| /bookstore/book[price>35.00] | 选取 bookstore 元素的所有 book 元素,且其中的 price 元素的值须大于 35.00。 |
| /bookstore/book[price>35.00]/title | 选取 bookstore 元素中的 book 元素的所有 title 元素,且其中的 price 元素的值须大于 35.00。 |
5.知道xpath的用法后,我们就可以轻松的拿到我们想要的信息了!!!
影片名称 :title = i.xpath('div[@class="hd"]/a/span[@class="title"]/text()')[0]
导演演员信息:info = i.xpath('div[@class="bd"]/p[1]/text()')
评分:rate = i.xpath('//span[@class="rating_num"]/text()')[0]
评论人数:comCount = i.xpath('//div[@class="star"]/span[4]/text()')[0]
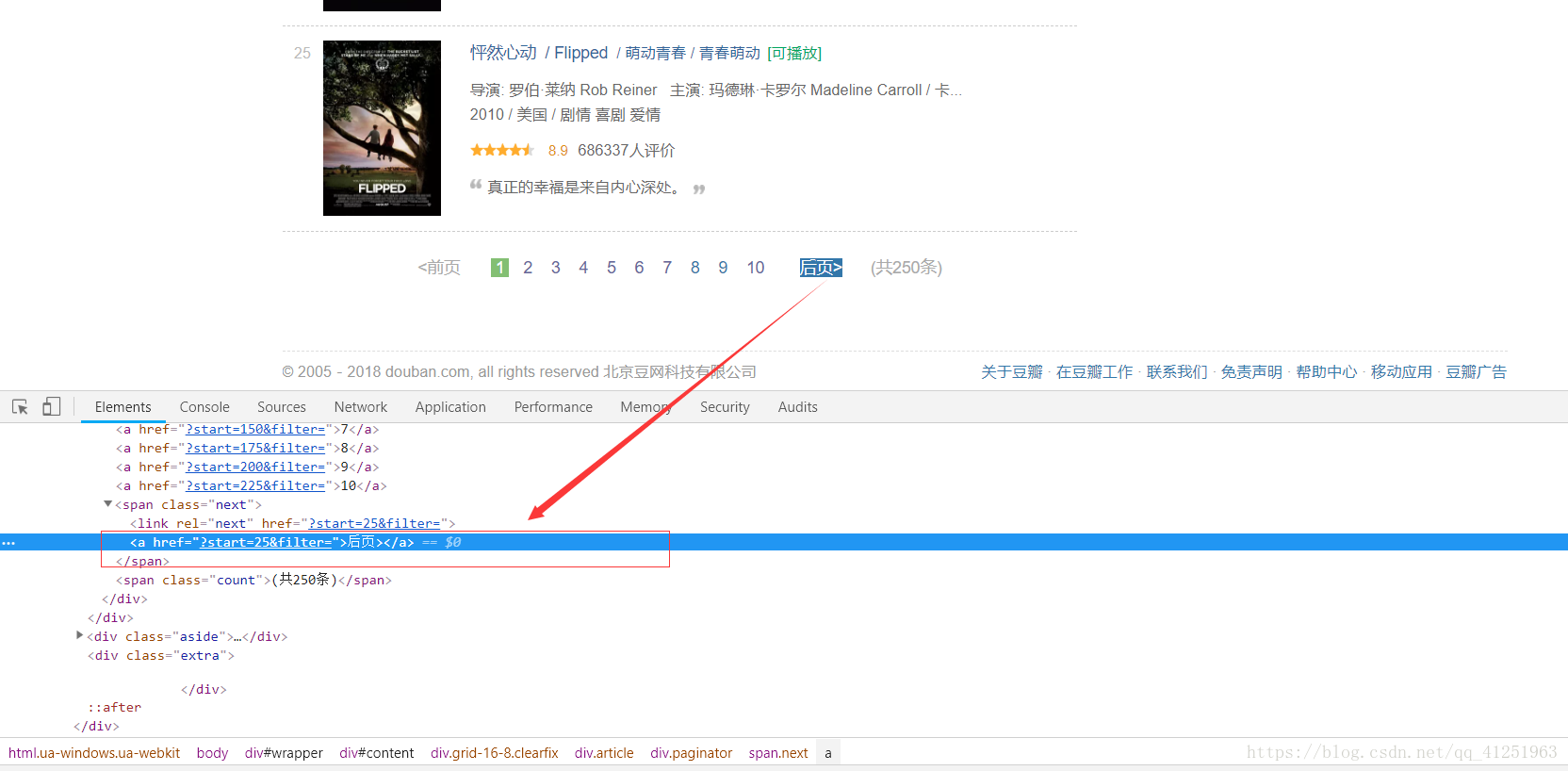
6.已经知道如何获取电影信息了,现在的任务是找到请求网址,我们可以翻页寻找网址的规律,看看第二页,第三页……网址是什么样的。
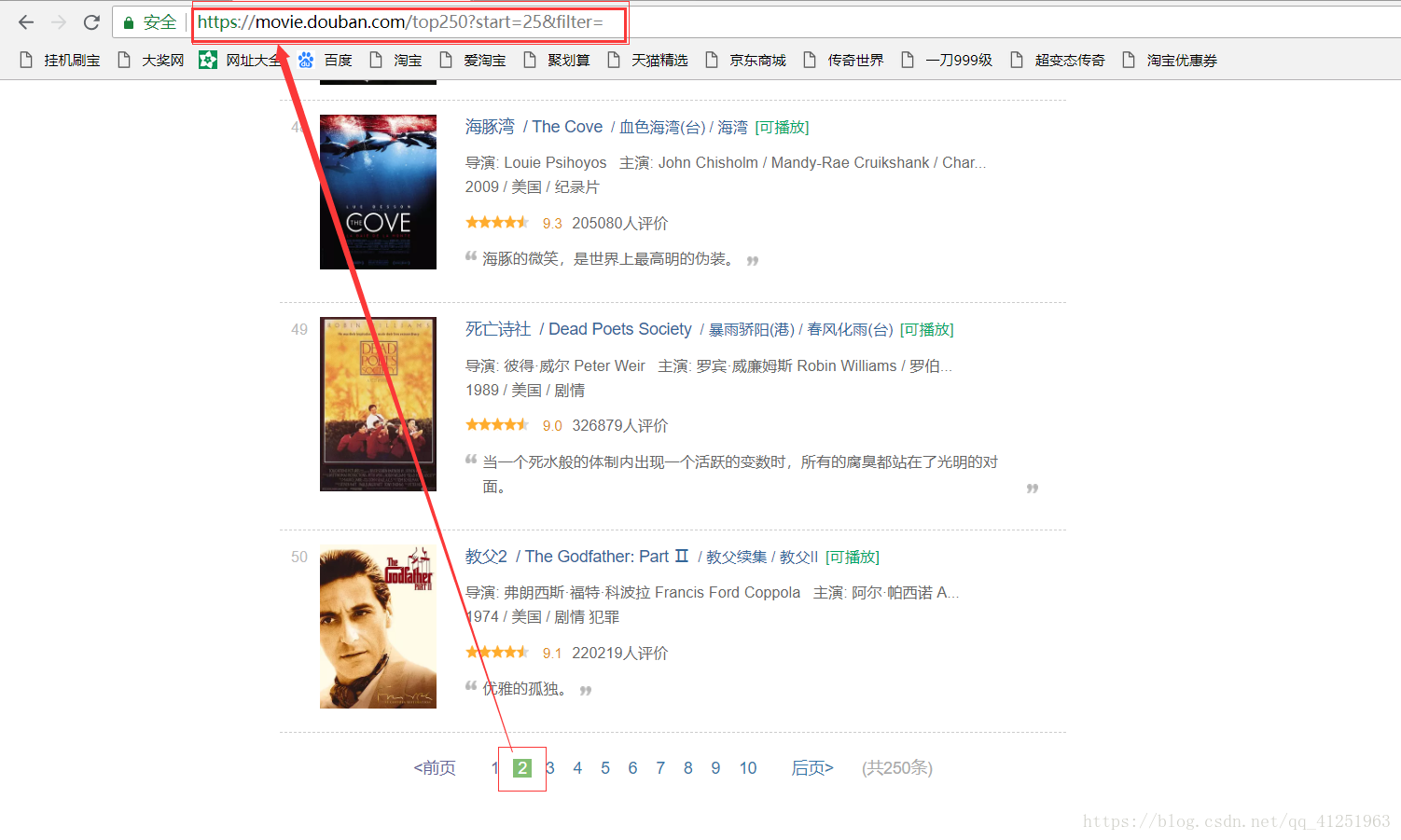
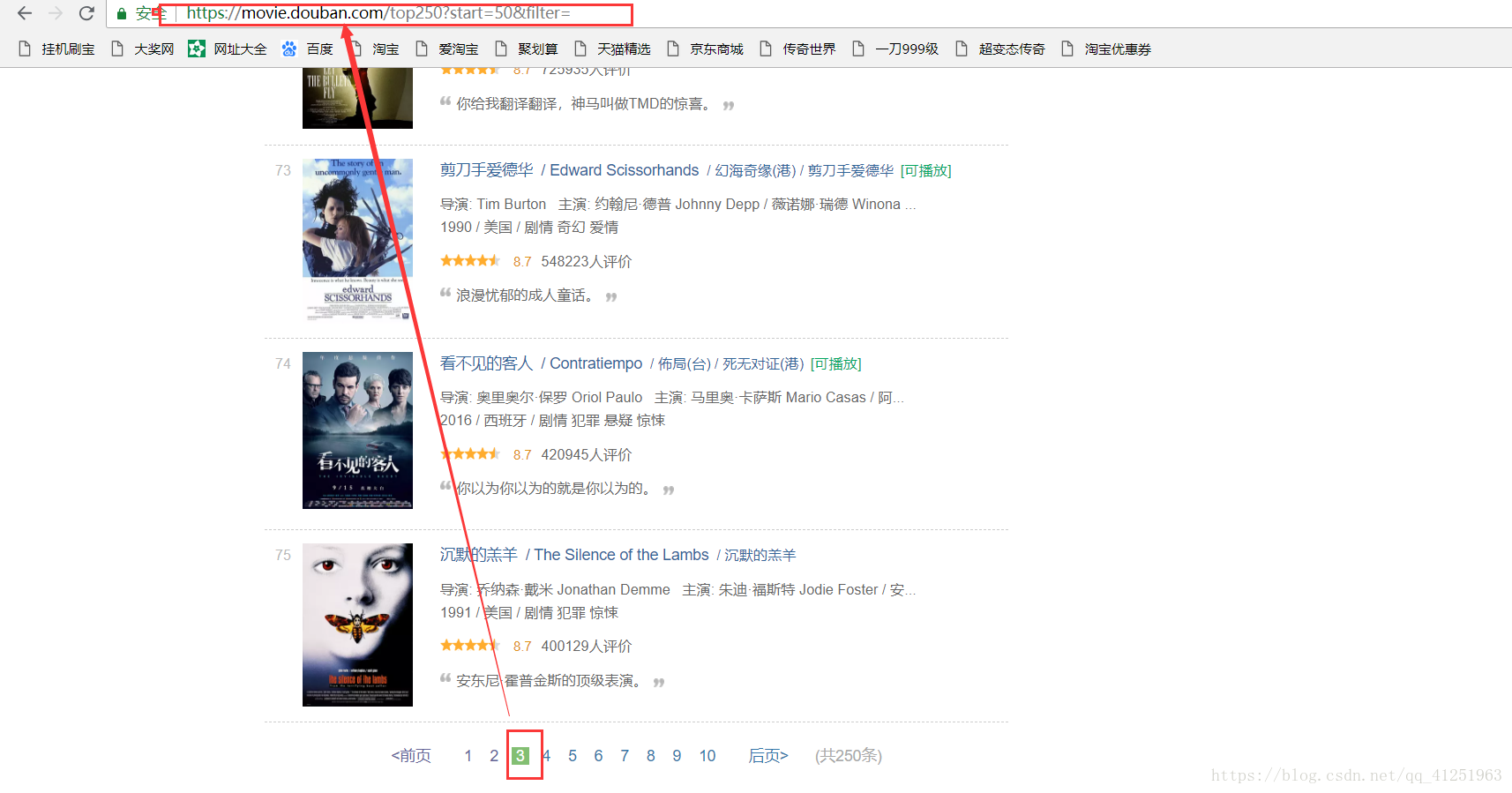
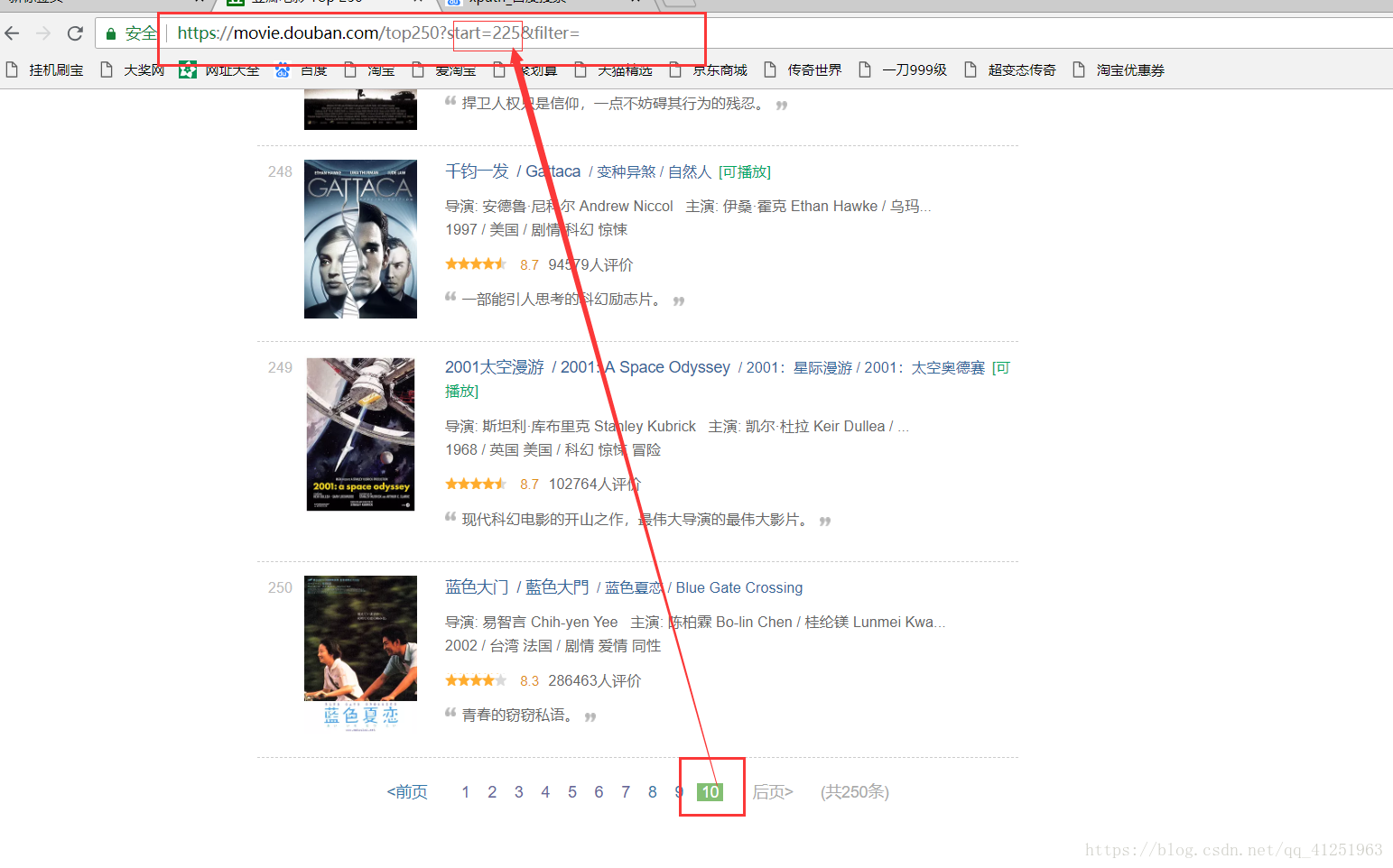
不难发现规律,只是每页网址的start=发生变化。我们可以使用for循环来请求每页网址,
for i in range(10):
url = 'https://movie.douban.com/top250?start={}&filter='.format(i*25)除此之外,我们也可利用xpath获取后页的链接(//div[@class=”paginator”]/span[@class=”next”]/a/@href),与‘https://movie.douban.com/top250’拼接,同样可以获取下一页地址。
完整代码
# coding:utf-8
import requests
from lxml import html
k = 1
for i in range(10):
url = 'https://movie.douban.com/top250?start={}&filter='.format(i*25)
con = requests.get(url).content
sel = html.fromstring(con)
# 所有的信息都在class属性为info的div标签里,可以先把这个节点取出来 //*[@id="content"]/div/div[1]/ol
for i in sel.xpath('//div[@class="info"]'):
# 影片名称
title = i.xpath('div[@class="hd"]/a/span[@class="title"]/text()')[0]
#print(title)
info = i.xpath('div[@class="bd"]/p[1]/text()')
# 导演演员信息
info_1 = info[0].replace(" ", "").replace("\n", "")
# 上映日期
date = info[1].replace(" ", "").replace("\n", "").split("/")[0]
# 制片国家
country = info[1].replace(" ", "").replace("\n", "").split("/")[1]
# 影片类型
geners = info[1].replace(" ", "").replace("\n", "").split("/")[2]
# 评分
rate = i.xpath('//span[@class="rating_num"]/text()')[0]
# 评论人数
comCount = i.xpath('//div[@class="star"]/span[4]/text()')[0]
# 打印结果看看
print ("TOP%s" % str(k))
print( title, info_1, rate, date, country, geners, comCount )
# 写入文件
with open("top250.txt", "a",encoding='utf-8') as f:
f.write("TOP%s\n影片名称:%s\n评分:%s %s\n上映日期:%s\n上映国家:%s\n%s\n" % (k, title, rate, comCount, date, country, info_1))
f.write("==========================\n")
k += 1扩展
将爬取的数据存入Mysql数据库
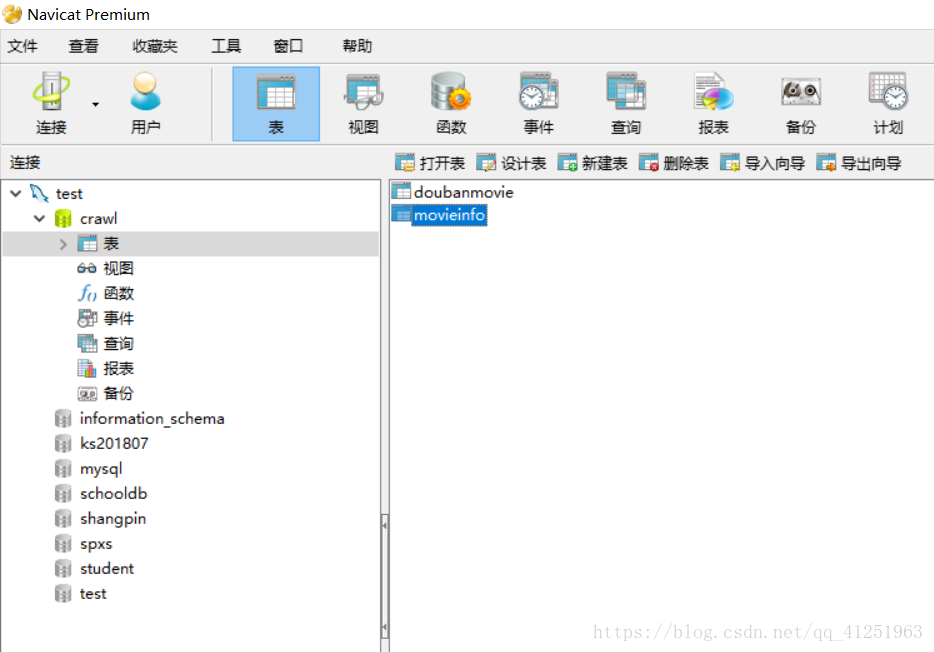
1.新建数据库crawl,并在数据库crawl中新建表doubanmovie,所建表如图所示。
2.对上面的代码稍作修改,将存取到TXT文档改为数据库,完整代码如下:
# coding:utf-8
import requests
import pymysql
from lxml import html
k = 1
for i in range(10):
url = 'https://movie.douban.com/top250?start={}&filter='.format(i*25)
con = requests.get(url).content
sel = html.fromstring(con)
# 所有的信息都在class属性为info的div标签里,可以先把这个节点取出来 //*[@id="content"]/div/div[1]/ol
for i in sel.xpath('//div[@class="info"]'):
# 影片名称
title = i.xpath('div[@class="hd"]/a/span[@class="title"]/text()')[0]
#print(title)
info = i.xpath('div[@class="bd"]/p[1]/text()')
# 导演演员信息
info_1 = info[0].replace(" ", "").replace("\n", "")
# 上映日期
date = info[1].replace(" ", "").replace("\n", "").split("/")[0]
# 制片国家
country = info[1].replace(" ", "").replace("\n", "").split("/")[1]
# 影片类型
geners = info[1].replace(" ", "").replace("\n", "").split("/")[2]
# 评分
rate = i.xpath('//span[@class="rating_num"]/text()')[0]
# 评论人数
comCount = i.xpath('//div[@class="star"]/span[4]/text()')[0]
# 打印结果看看
print ("TOP%s" % str(k))
print( title, info_1, rate, date, country, geners, comCount )
connection=''
try:
# 获取一个有效的数据库连接对象,此处填写你的数据库信息,特别注意charset一定要写成'utf8',不能写成'utf-8'。
connection = pymysql.connect(host='localhost', port=3306,
user='root', password='mysql',
db='crawl', charset='utf8')
if connection:
print("[mysql]>>正确获取数据库的连接对象")
# 创建一个游标对象
curosr = connection.cursor()
print('[mysql]正确获取游标对象')
# 设置插入数据的sql语句模板
sql = "insert into doubanmovie VALUES (null,'%d','%s','%s,','%s','%s','%s','%s')" % (k, title, rate, comCount, date, country, info_1)
print('[mysql]>>%s' % sql)
# 使用游标对象发送sql语句并将服务器结果返回
affectedRows = curosr.execute(sql)
msg = '[mysql]>>写入操作成功' if affectedRows > 0 else '[mysql]>>写入失败'
print(msg)
# 事务提交
connection.commit()
print("[mysql]>>事务提交")
except:
connection.rollback()
print('[mysql]事务回滚')
finally:
# 关闭数据库连接
connection.close()
print("[mysql]>>关闭数据库连接")
k += 1注意事项及功能均在代码注释中。
运行结果如图:
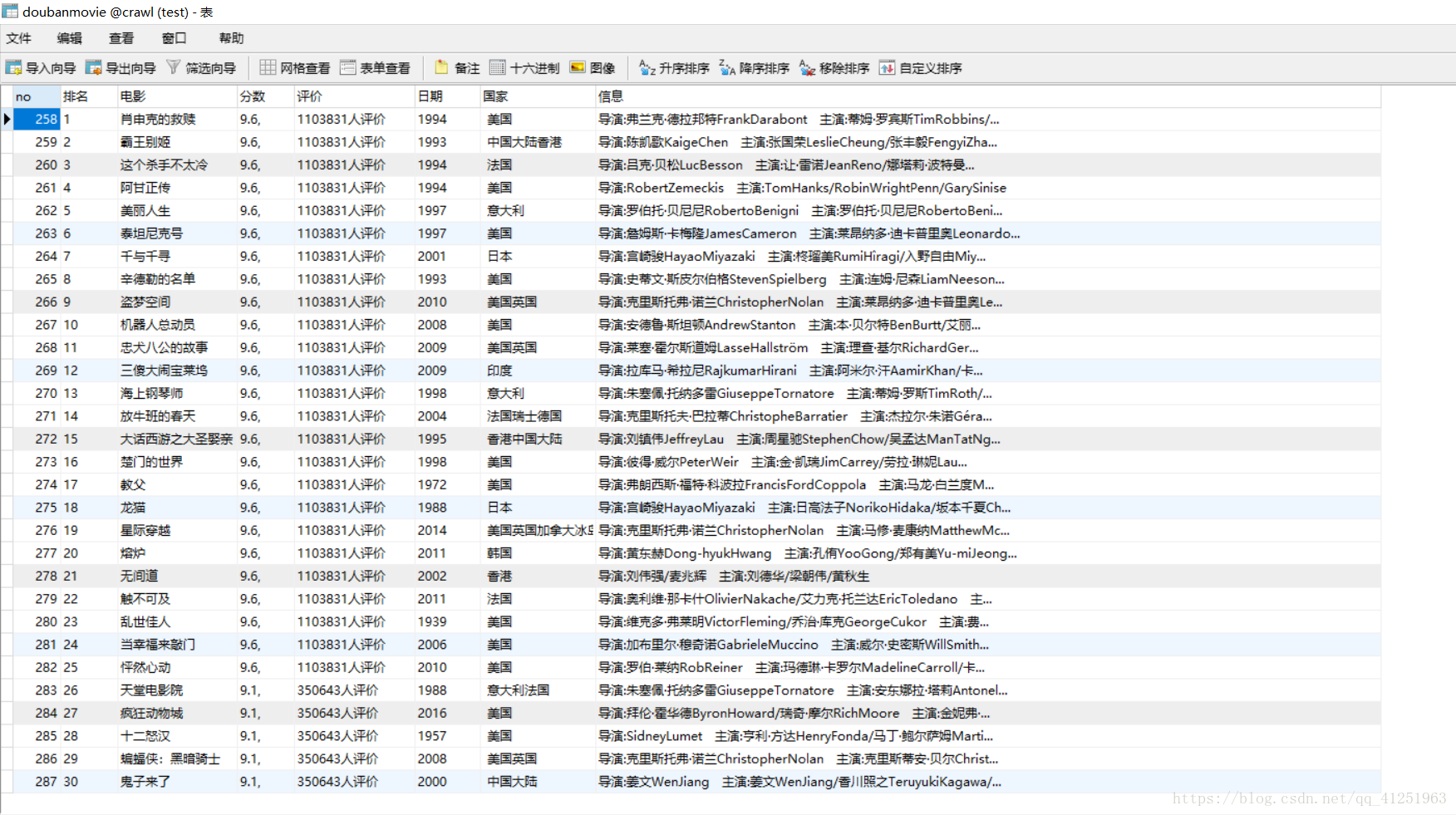
如图已将所有信息存入到数据库中!