python3代码实现在https://github.com/yantijin/Lean_DataMining上,时间匆忙,敬请之处错误之处,谢谢!
以下内容转自:https://blog.csdn.net/androidlushangderen/article/details/43635115,原文中有JAVA实现,可以参考
介绍
在介绍AdaBoost算法之前,需要了解一个类似的算法,装袋算法(bagging),bagging是一种提高分类准确率的算法,通过给定组合投票的方式,获得最优解。比如你生病了,去n个医院看了n个医生,每个医生给你开了药方,最后的结果中,哪个药方的出现的次数多,那就说明这个药方就越有可能性是最由解,这个很好理解。而bagging算法就是这个思想。
算法原理
而AdaBoost算法的核心思想还是基于bagging算法,但是他又一点点的改进,上面的每个医生的投票结果都是一样的,说明地位平等,如果在这里加上一个权重,大城市的医生权重高点,小县城的医生权重低,这样通过最终计算权重和的方式,会更加的合理,这就是AdaBoost算法。AdaBoost算法是一种迭代算法,只有最终分类误差率小于阈值算法才能停止,针对同一训练集数据训练不同的分类器,我们称弱分类器,最后按照权重和的形式组合起来,构成一个组合分类器,就是一个强分类器了。算法的主要过程:
1、对D训练集数据训练处一个分类器Ci
2、通过分类器Ci对数据进行分类,计算此时误差率
3、把上步骤中的分错的数据的权重提高,分对的权重降低,以此凸显了分错的数据。为什么这么做呢,后面会做出解释。
完整的adaboost算法如下

最后的sign函数是符号函数,如果最后的值为正,则分为+1类,否则即使-1类。
我们举个例子代入上面的过程,这样能够更好的理解。
adaboost的实现过程:

图中,“+”和“-”分别表示两种类别,在这个过程中,我们使用水平或者垂直的直线作为分类器,来进行分类。
第一步:

根据分类的正确率,得到一个新的样本分布D2,一个子分类器h1
其中划圈的样本表示被分错的。在右边的途中,比较大的“+”表示对该样本做了加权。
算法最开始给了一个均匀分布 D 。所以h1 里的每个点的值是0.1。ok,当划分后,有三个点划分错了,根据算法误差表达式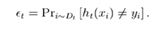 得到 误差为分错了的三个点的值之和,所以ɛ1=(0.1+0.1+0.1)=0.3,而ɑ1 根据表达式 的可以算出来为0.42. 然后就根据算法 把分错的点权值变大。如此迭代,最终完成adaboost算法。
得到 误差为分错了的三个点的值之和,所以ɛ1=(0.1+0.1+0.1)=0.3,而ɑ1 根据表达式 的可以算出来为0.42. 然后就根据算法 把分错的点权值变大。如此迭代,最终完成adaboost算法。
第二步:

根据分类的正确率,得到一个新的样本分布D3,一个子分类器h2
第三步:

得到一个子分类器h3
整合所有子分类器:

因此可以得到整合的结果,从结果中看,即使简单的分类器,组合起来也能获得很好的分类效果,在例子中所有的。后面的代码实现时,举出的也是这个例子,可以做对比,这里有一点比较重要,就是点的权重经过大小变化之后,需要进行归一化,确保总和为1.0,这个容易遗忘。