1. 背景介绍
GBDT和Random Forest都是两种常见的集成算法,虽然两者都是基于决策树的集成方式,但是两者都有不同的侧重点,本文从不同的角度来讲述不同的学习方式。他们都是通过某种策略把多个弱学习器组合起来,形成一个具有很高预测准确率的强学习算法。
2. Bagging 和 Boosting
集成学习是机器学习领域的一个重要分支,其不仅仅是一种具体的算法,而是一种学习思想,主要分为两种重要方法:Bagging和Boosting。他们都是通过某种策略把多个弱学习器组合起来,形成一个具有很高预测准确率的强学习算法。
2.1 Bagging
Bagging即为套袋法,具体算法如下:
(1)从原始样本集中抽取训练,每轮从原始样本中使用Boostrap Aggregation的方法抽取n个训练样本(在训练集中,有些样本可能被多次抽取到,而有些样本可能一次都没有被抽中)。共进行k轮抽取,得到K个训练集(k个训练集之间是相互独立的)。
(2)每次使用一个训练集得到一个模型,k个训练集共得到k个模型(注:这里没有具体的分类算法或回归算法,我们可以根据具体问题采用不同的分类或回归方法,如决策树、感知器等)。
(3)对分类问题:将上述步骤得到的k个模型采用voting的方式得到分类的结果,对于回归问题,上述模型的均值作为最后的结果(所有模型的重要性认为是相同的)。
2.2 Boosting
Boosting是一个加法模型,从常数开始迭代,每一轮增加一个函数,每次新添加的函数是基于以往所有的学习结果和真实值之间的残差上学习的模型。如下式:

3. GBDT
GBDT 是 Boosting 的代表,每次训练都是使用所有数据,但是最终结果是多颗树的叠加,训练完一棵树以后,将结果的残差作为下一棵树的训练目标。在这个过程中还使用了梯度近似残差的方法。
GBDT的损失函数值优化可以看成是在函数空间,而不是在参数空间。![]() 包含平方损失
包含平方损失![]() 和绝对值
和绝对值![]() 用于回归问题,负二项对数似然
用于回归问题,负二项对数似然![]() ,
,![]() 用于分类,但是关注点是预测函数的加性扩展。
用于分类,但是关注点是预测函数的加性扩展。
强分类器是由多个弱分类器线性加成的。


这里的![]() 指代回归树,例如CART,
指代回归树,例如CART,![]() 是模型参数,这里指代每个节点的分裂特征(变量),最佳分割点,节点的预测值。M就是有多少个弱分类器。
是模型参数,这里指代每个节点的分裂特征(变量),最佳分割点,节点的预测值。M就是有多少个弱分类器。
3.1 CART生成
CART(分类回归树)生成的过程其实就是一个选择特征的过程。假设我们目前总共有 M 个特征。第一步我们需要从中选择出一个特征 j,做为二叉树的第一个节点。然后对特征 j 的值选择一个切分点 m。一个 样本的特征 j 的值 如果小于 m,则分为一类,如果大于 m,则分为另外一类。如此便构建了CART树的一个节点。其他节点的生成过程和这个是一样的。类似下图:

3.2 参数空间的优化
然后,我们来回顾下参数空间的数值优化,假设预测函数为![]() ,那么损失函数就是:
,那么损失函数就是:
![]()
优化后得到的参数最优解是:
![]()
优化方式是,常见的是基于梯度的方式,优化的每一步则为![]() ,从初始值
,从初始值![]() 开始,m对应每一步更新迭代,负梯度
开始,m对应每一步更新迭代,负梯度![]() 就是最速下降方向,
就是最速下降方向,![]() 就是在这个最速下降方向上进行线搜索得到的最优步长(学习率)。
就是在这个最速下降方向上进行线搜索得到的最优步长(学习率)。

![]()
将预测函数![]() 对应参数
对应参数![]() ,最优解变成了:
,最优解变成了:

相当于在函数空间上作梯度下降,每一步梯度下降:

回顾了参数空间的优化,我们把这个思想代入到 gradient boosting,我们之前已经得到预测函数为:
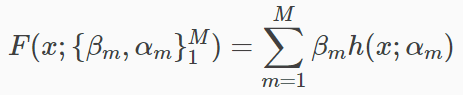
所需要做的事情就是得到预测函数的最优解,就是:
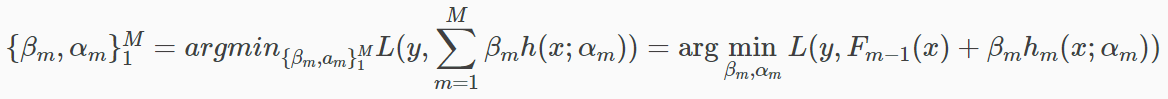
已知最速梯度下降方向为![]() ,为每一个
,为每一个![]() 都建立在最速梯度下降的方向,我们可以得到:
都建立在最速梯度下降的方向,我们可以得到:
![]()
可以认为是 ![]() 去拟合伪标签
去拟合伪标签![]() 。这里用最小二乘的原因是 GBDT 构造的树全是回归树(CART)。
。这里用最小二乘的原因是 GBDT 构造的树全是回归树(CART)。
最后进行搜索确定最优步长![]() :
:

3.3 Gradient Boosting 分类实例
以简单分类任务为例,对于Gradient Boosting来说,回归与分类任务均使用CART,原理和多分类的逻辑回归类似,对于下面一个三分类任务来说:
![]()
这里我们可以训练3棵树,分别表示是不是第一类,是不是第二类。如果当前样本属于第二类 :

下一轮的输入为:![]() ,当新来一个样本的时候:
,当新来一个样本的时候:![]()

以花萼长度来区分,若分类标准为5.1,则一号样本记为右子树>=5.1,右子树包含1,3,4,5,6号样本,左子树包含2号样本。对于真实值来说,山xx花来说标签是100,杂xx花标签为010,维吉尼亚xx花为001,这里就可以与预测值为(1-(1/5))^2=0.64,左边的损失就是(1-1)^2=0,那么仅仅看第一个位置,左右子树相加后即可得到结果。随着模型的切割,会以下面的图形展示:


每一次的迭代效果可以以直线画为:

4. Random Forest
Random Forest 是 Bagging 的 Decision Tree 模型集合,最后用简单的投票方式作为最终结果,同时,每棵决策树会对数据的特征进行随机采样,这样的目的也是让每个模型看起来像是原来数据的一部分。由于引入了随机性,使得训练的随机森林不太容易过拟合,也具有一定的高噪声额能力,能够处理高纬度数据,所以不用做特征选择,模型的训练过程中,可以很容易地实现并行化。
5. AdaBoost
AdaBoost以下图为例,下面是第一次数据集划分以及权重更新,每次分类后,就会更新相关权重值,并记录第一次分类模型F1(x)

反复如下,更新N轮(进行迭代),迭代得到F2(x),F3(x),F4(x),F5(x),后得到每个模型分类模型的好坏。

AdaBoost得到最终结果为,对每个模型至于不同的权重,将结果串联在一起,得到:

代码会在我的github链接中获得:https://github.com/Merlin5417,若觉得上述演示还ok,可以给小弟github一个start。