集成方法
集成学习的主要思想是利用一定的手段学习出多个分类器,而只要求这多个分类器是弱分类器,然后将多个弱分类器进行组合预测。
核心问题就是如何训练多个弱分类器以及如何将这些弱分类器进行组合?
集成方法主要包括Bagging和Boosting两种方法,随机森林算法是基于Bagging思想的机器学习算法,AdaBoost算法、GBDT(Gradient Boost Decision Tree,梯度提升决策树)算法和XGBoost算法是基于Boosting思想的机器学习算法。在Bagging中,主要通过对训练数据集进行随机采样,以重新组合成不同的数据集,利用弱学习算法对不同的新数据集进行学习,得到一系列的预测结果,对这些预测结果做平均或者投票做出最终的预测。在Boosting思想中是通过对样本进行不同的赋值,提高那些被前一轮弱分类器错误分类样本的权值,而降低那些被正确分类样本的权值,那些没有得到正确分类的数据会受到更大的关注,最后通过弱分类器的加权多数表决来得到样本的最终分类。

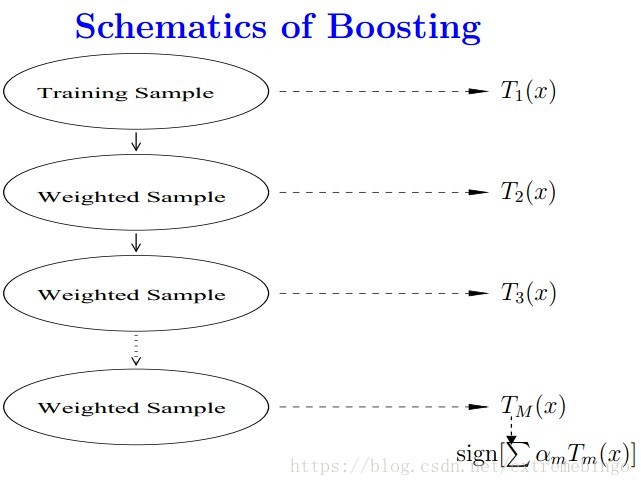
在提升方法中,其基本思想是:对于一个复杂任务来说,将多个专家的判断进行适当的综合所得出的判断,要比其中任何一个专家单独的判断好。实际上就是“三个臭皮匠顶个诸葛亮”的道理。提升方法中最具代表性的算法是AdaBoost。
AdaBoost
基本概念
Adaboost算法是将多个弱分类器,组合成强分类器。
AdaBoost,是英文”Adaptive Boosting“(自适应增强)的缩写。 它的自适应在于:前一个弱分类器分错的样本的权值会得到加强,正确分类样本的权值会减小,更新权值后的样本再次被用来训练下一个新的弱分类器。最后采用加权多数表决的方法将弱分类器进行组合。
算法
输入:训练数据集
输出:最终分类器
(1) 初始化训练数据的权值分布(假设训练数据集具有均匀的权值分布,即每个训练样本在基分类器的学习中作用相同)。
(2) 对
- 使用具有权值分布
Dm 的训练数据集学习,得到基本分类器
- 计算
Gm(x) 在训练数据集上的分类误差率
- 计算基本分类器
Gm(x) 的系数αm
- 更新训练数据集的权值分布
由权值更新公式可知,被基本分类器
(3) 构建基本分类器的线性组合
得到最终分类器
参考
[1] 简单易学的机器学习算法——集成方法(Ensemble Method)
[2] 统计学习方法——CART, Bagging, Random Forest, Boosting
[3] 统计学习方法. 李航