关联规则,肯定很多人都听说过:一个男士买尿布时顺带买啤酒的事情;
具体事物之间真的是否具有关联,有多大的关联,这就是本篇博客需要分享学习的知识。
其实现实生活当中,运用到关联规则的例子有很多:首先就是购物、推荐系统、文本词汇间关联分析等等;在这里以超市购物为例进行具体讲解:

在这里x,y就是购买的部分商品,I表示所有的商品;其含义就是购买商品x与购买商品y之间的关联关系;
同时在这里引入对规则定量的描述:

支持度就是所买商品中中同时含有x,y的概率;置信度就是同时含有x,y商品占含有x商品的概率,因为这里表示的是由x推出y的概率,所以是除以含有x的数量;
下面这个例子非常明确:
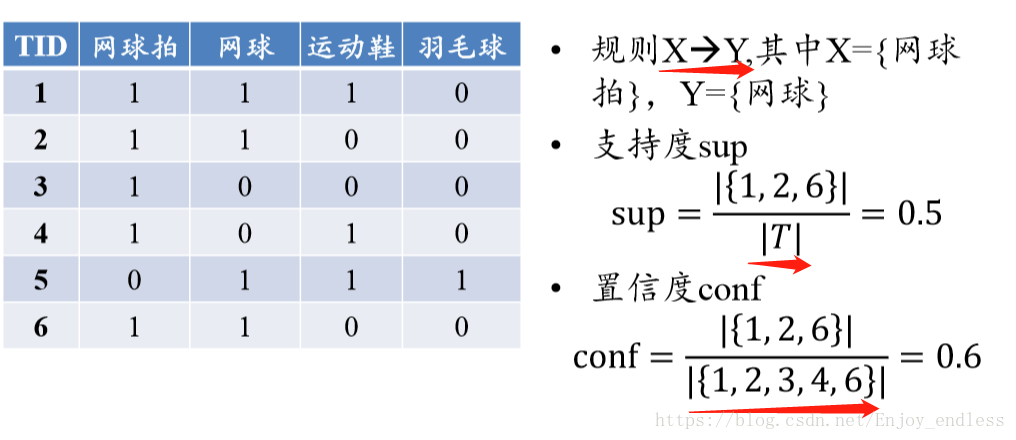
关联规则挖掘的目标是什么,就是找到具有关联的商品,而对于商品之间的关联程度需要有一个界定,称为:最小支持度和最小置信度;
如何找到满足条件的关联规则,在这里学习一种Apriori算法:
两个步骤:
1、寻找所有满足最小支持度的频繁集(满足最小支持度的项目集合);
2、基于频繁集产生规则。
(在这里解释一个概念:频繁集(例如含有三个商品ABD)的子集都是频繁集—–子集代表着含有较少的商品例如子集商品A,那么子集A的支持度肯定>=父集ABD的支持度,所以子集A满足频繁集条件)
实例讲解过程:

首先给出基本需要满足的条件,最小支持度0.5,得到次数2次;
1、第一次扫描统计单个商品出现的个数C1,剔除掉不符合条件(<2次)的得到F1;合并组合F1中的集合得到C2;
2、第二次扫描所有商品得到符合C2集的个数,去掉不符合条件的得到F2;再次组合得到C3;
3、利用同上方法,得到F3,此时F3只剩一个集合,算法结束;
利用如上方法可以找到最终满足条件的规则,但是有一个可以优化的地方;在上面我们解释了一个频繁集的性质,即其子集也必须是频繁集;利用这个性质,在我们得到的合并集合C2、C3等,可以在下一次扫描全集T之前进行简化处理:如上的C3,其{1,2,3}含有子集{1,2},而其根据C2其{1,2}个数可以直接排除,所以在第三次扫描T的时候就没有必要求{1,2,3}的个数;同理{1,3,5}其含有{1,5}所以也可以直接排除;
最后我们来看一下Apriori算法的具体实现:


对于如上算法的理解其实已经是非常简单的了,集合的选取、递归合并及剔除,然后就是计算概率选取满足条件的规则即可。
如上就生成了频繁集,而频繁集不等价于关联规则;
那么如何定义关联规则:

关联规则是频繁集的子集,对于其所有可能的子集进行最小支持度判断,找到最终的关联规则。
实例:

小结:

如上所述,m个商品集合生成的规则数量是比较庞大的,每次扫描所有商品进行计数代价也是很大的;所以应该结合实际情况,对K和最小支持度进行适当的调整,以达到更加切合实际、高效快捷的目的。