本文实现数据挖掘中关联规则的挖掘。关联规则挖掘一般针对交易数据库,挖掘每次交易中用户购买的项(即购买的物品)之间的关联关系。最常用的度量方式有:置信度,支持度,兴趣度,期望可达度等等。
假设交易数据库为D={T1,T2,T3,.......,Tn},购买的物品的项集为I={I1,I2,I3,.......,In}。假设X为某次交易Ti购买的项,Y为每次交易Tj购买的项。置信度: X-->Y = P(X|Y)=P(X,Y)/P(X),置信度实际上反应了一个可信度的度量,即由X推出Y的可信度,在计算上本质是一个条件概率。支持度:Support(X-->Y) = Num(X,Y)/Num(D),即(X,Y)同时发生的频率,本质上反应了关联规则X-->Y的重要程度。期望可达度P(Y)=Num(Y)/Num(X),即Y本身的频率统计。兴趣度:(置信度-支持度)/Max(置信度,支持度),一条规则的兴趣度大于0,实际利用价值越大。
若一条规则满足最小支持度以及最小置信度,则称这条规则为强关联规则。
Apriori利用最小支持度,统计频繁项集。频繁一项:即每个项在整个交易数据库中出现的次数(每个一项的次数需要满足最小支持度)。频繁二项:先由频繁一项的物品,排列组合得到二项组合,再根据最小支持度,得到频繁二项集。频繁三项:由频繁二项组合得到.......知道某一项的频繁项集为空。得到各频繁项集,相应就得到了关联规则。具体来说:频繁一项-->频繁二项-->频繁三项-->频繁四项-->........
Apriori会出现组合爆炸,搜索时间可能会较长,也和数据量有关。本文的数据集是关联规则分析经典数据集Groceries数据,有9896条交易数据。
运行结果如下图所示:
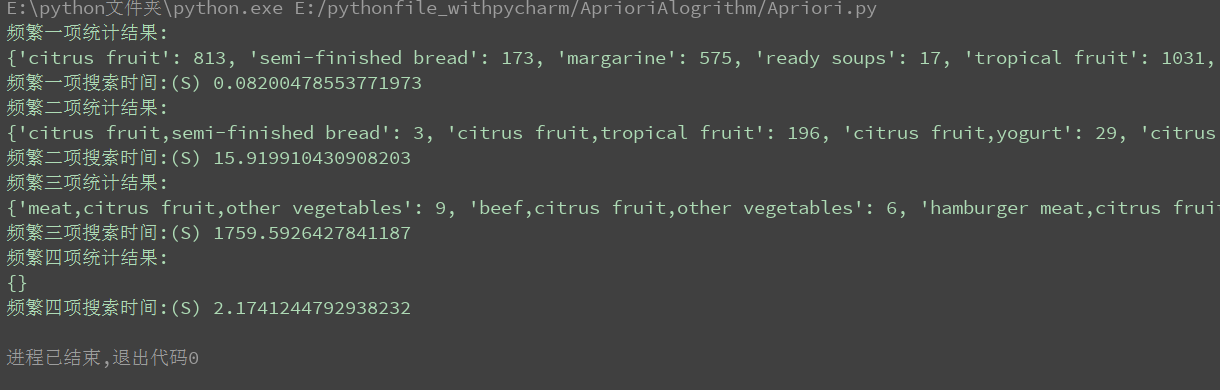
本文最小支持度设置为3,到了频繁四项为空,算法结束。频繁三项的搜索时间大概20分钟左右,最小支持度设置的越小,所花费的时间越长。
源代码如下:
# !/usr/bin/env python
# -*- coding:utf-8 -*-
# Author: wsw
# 数据挖掘中关联规则Apriori算法
import pandas as pd
import re
import time
import numpy as np
def main():
datapath = '../Groceries.csv'
rowdata = pd.read_csv(datapath)
# 数据集中的项集
itemSets = rowdata.loc[:, 'items']
# 得到交易个数
Num = itemSets.shape[0]
# 定义最小支持度为4
minSupport = 3
# 正则模式
# 匹配2个字符中间的内容,注意括号里面是要匹配的内容,'{'或者','开头,','或者'}'结尾
pattern = re.compile('[{,](.*)?[,}]')
# 得到频繁一项统计
freqOne, time1 = countFreqOneItem(itemSets, pattern, minSupport)
print('频繁一项统计结果:')
print(freqOne)
print('频繁一项搜索时间:(S)', time1)
freqTwo, time2 = countFreqTwo(itemSets, freqOne, minSupport)
print('频繁二项统计结果:')
print(freqTwo)
print('频繁二项搜索时间:(S)', time2)
freqThree, time3 = countFreqThree(itemSets, freqTwo, minSupport)
print('频繁三项统计结果:')
print(freqThree)
print('频繁三项搜索时间:(S)', time3)
freqFour, time4 = countFreqFour(itemSets, freqTwo, minSupport)
print('频繁四项统计结果:')
print(freqFour)
print('频繁四项搜索时间:(S)', time4)
pass
# 统计数据集中的频繁一项
def countFreqOneItem(itemset, pattern, minSupport):
# 支持度度量统计
start = time.time()
countSupport = {}
for itemTransction in itemset:
# 拆分每次交易中,单个物品
res = re.findall(pattern, itemTransction)
items = res[0].split(',')
for item in items:
if item in countSupport.keys():
countSupport[item] += 1
else:
countSupport[item] = 0
# 频繁一项
freqOne = {}
for key, value in countSupport.items():
if value >= minSupport:
freqOne[key] = value
end = time.time()
time1 = end - start
return freqOne, time1
pass
# 统计项集中的频繁二项
def countFreqTwo(itemset, freqOne, minSupport):
# 二项集列表
start = time.time()
twoItemsList = []
itemNames = list(freqOne.keys())
num = len(itemNames)
for i in range(num - 1):
for j in range(i + 1, num):
twoItemsList.append(','.join([itemNames[i], itemNames[j]]))
# 得到二项集的支持度统计
countSupport = {}
for item in twoItemsList:
countSupport[item] = 0
for itemcollection in itemset:
if item in itemcollection:
countSupport[item] += 1
# 得到频繁二项集
freqTwo = {}
for key, value in countSupport.items():
if value >= minSupport:
freqTwo[key] = value
end = time.time()
time2 = end - start
return freqTwo, time2
pass
# 统计频繁三项
def countFreqThree(itemset, freqTwo, minSupport):
# 三项集列表
start = time.time()
ThreeItmeList = []
twoItemNames = list(freqTwo.keys())
num = len(twoItemNames)
for i in range(num-1):
for j in range(i+1, num):
# 拆分得到当前的物品名称
currentItem = twoItemNames[i].split(',')
# 拆分得到下一个二项集物品的名称
nextItem = twoItemNames[j].split(',')
# 融合得到三项集
for item in nextItem:
tempCurrent = currentItem[:]
tempCurrent.append(item)
threeItem = set(tempCurrent)
if len(threeItem) == 3:
# 将集合转成列表进行处理
threeItem = list(threeItem)
threeItem = ','.join(threeItem)
ThreeItmeList.append(threeItem)
# 得到三项集的支持度度量
countSupport = {}
for threeitem in ThreeItmeList:
countSupport[threeitem] = 0
for itemcollection in itemset:
if threeitem in itemcollection:
countSupport[threeitem] += 1
# 统计频繁三项集
freqThree = {}
for key, value in countSupport.items():
if value >= minSupport:
freqThree[key] = value
end = time.time()
time3 = end - start
return freqThree, time3
pass
# 统计频繁四项的个数
def countFreqFour(itemset, freqThree, minSupport):
# 四项集列表
start = time.time()
fourItmeList = []
threeItemNames = list(freqThree.keys())
num = len(threeItemNames)
for i in range(num-1):
for j in range(i+1, num):
# 拆分得到当前的物品名称
currentItem = threeItemNames[i].split(',')
# 拆分得到下一个三项集物品的名称
nextItem = threeItemNames[j].split(',')
# 融合得到四项集
for item in nextItem:
tempCurrent = currentItem[:]
tempCurrent.append(item)
fourItem = set(tempCurrent)
if len(fourItem) == 4:
# 将集合转成列表进行处理
fourItem = list(fourItem)
fourItem = ','.join(fourItem)
fourItmeList.append(fourItem)
# 得到四项集的支持度度量
countSupport = {}
for fouritem in fourItmeList:
countSupport[fouritem] = 0
for itemcollection in itemset:
if fouritem in itemcollection:
countSupport[fouritem] += 1
# 统计频繁四项集
freqFour = {}
for key, value in countSupport.items():
if value >= minSupport:
freqFour[key] = value
end = time.time()
time4 = end - start
return freqFour, time4
pass
if __name__ == '__main__':
main()
pass