版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/qq_37334135/article/details/85228107
这基本就是关于《统计学习方法》的笔记,当然自己会记的让人容易读懂,为了加深记忆,证明都证了两遍,便于加深理解还是打算写在博客里好了。接下来会先介绍什么是提示方法,再介绍Adaboost算法,接着会给个书上的例子,最后再给出一些推导(由于之前是写过的但是没保存好,所以这次有的部分就粘贴了)。
1、提升方法
定义:在分类问题中,该方法会改变训练样本的权重,学习到多个弱分类器,最后将这些分类器进行线性组合形成一个强分类器,从而提高分类的能力。
关于弱分类器可以简单理解为该模型可以分类但是分类能力不强,而强分类器则能很好的进行分类。
如此一来,对于提升方法我们需要考虑两个问题
- 每次迭代的时候如何改变样本的权重
- 如何将这些弱分类器组合成一个强分类器。
ps:如何获得弱分类器(或者说基本分类器)是根据需要的来决定的,与提升方法没有必然联系,比如可以是决策树模型,然后学习到一个强的决策树模型。
2、Adaboost
Adaboost就是一个典型的提升方法,那么它如何解决上面的两个问题呢?
- 每次迭代过程中,会提高上一轮误分类样本点(使用上一轮分类器不能进行正确分类的样本)的权重,使它在本轮中获得更多的关注;相反,上一轮正确分类的样本的权重则会降低;
- 提升方法中已经说了会对弱分类器进行线性组合形成强分类器,Adaboost的做法是采用加权多数表决的方法,具体的,增大分类误差率低的弱分类器的系数,降低分类误差率高的弱分类器的系数。
下面关于二分类问题给出该算法流程(昨天写了没保存好,所以不想写了就直接粘贴了)
Adaboost
输入:二分类样本集
T={(x1,y1),(x2,y2),...,(xN,yN)},其中
y={+1,−1};弱学习算法(来获得弱分类器);
输出:最终强分类器
G(x)


这里做一些必要的说明
- 算法最开始的时候,没有别的要求的话,设置每个样本的权重是一样的即
N1;
- 针对每个m我们是从
(a)计算到
(3),如果发现此时的最终分类器还是不能进行正确分类,那么设置
m=m+1进行下一轮
-
(b)步的分类误差率
em=i=1∑NwmiI(G(xi)̸=yi),其中
I是指示函数
I(true)=1,I(false)=0,所以实际上分类误差率就是被错误分类的样本的权重之和。和一般所认识的分类误差率
em=N1i=1∑NI(G(xi)̸=yi)很类似。显然值越小那么该分类器
Gm(x)的分类能力更好
- 对于
(c)步的分类器系数
αm=21log(em1−1),当
em<1/2的时候,
em越小(分类器
Gm(x)的分类能力更好)则系数越大,中一点在
2中已经提到过。
- 对于
(d)步,该步骤是更新样本权重的,如何更新?被错误分类的样本会增大权重从而会在下一轮引起重视,被正确分类的则减少权重。如果看的不清楚,因为是二分类问题所以
Gm(xi)=1或者
−1,所以下一轮的权重
wm+1,i 可以写成下面的形式(写在了最后面)。这也是上面1所说的
- 在第
(3)步,则是对弱分了器进行线性组合,比如第一轮得到的是
G1(x),那么这轮
f(x)=α1G1(x),第二轮得到的是
G2(x),那么这轮会进行叠加,即
f(x)=αaG1(x)+α2G2(x)。其中
f(x)的正负号表示分类结果,比如有样本
(x4,1),将
x4作为输出,如果有
f(x4)<0,那么表示对该样本分类错误了,需要继续学习。
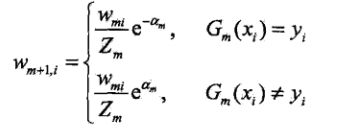
到这算法就算介绍完了,下面来个具体的例子(例子是李航老师《统计学习方法》中直接粘贴来的)




3、Adaboost训练误差界
上面的算法结束时得到了最终分类器
G(x),那么训练误差为
em=N1i=1∑NI(G(xi)̸=yi),下面来证明误差上界
N1i=1∑NI(G(xi)̸=yi)<=N1i=1∑Ne−yif(xi)=m=1∏MZm
左边证明:
由于
G(xi)̸=yi 所以
yif(xi)<0,从而
e−yif(xi)>=1,
I(G(xi)̸=yi)<=e−yif(xi) 左边得证。
再证右边:
N1i=1∑Ne−yif(xi)=N1i=1∑Ne−yim=1∑MαmGm(xi)=N1i=1∑Ni=1∏ne−yiαmGm(xi)
在初始的时候
w1i=N1,另外
wmie−αmyiGm(x)=Zmwm+1,i 带入到上式
i=1∑Nw1im=1∏Me−yiαmGm(xi)=i=1∑Nw1im=2∏Me−yiαmGm(xi)=Z1i=1∑Nw2ii=2∏ne−yiαmGm(xi)=Z1Z2i=1∑Nw3im=3∏Me−yiαmGm(xi)=...=Z1Z2...ZM−1i=1∑Ne−yiαMGM(xi)=m=1∏MZm
从证明的结果来看,在算法的每一轮可以选取适当的
Gm使得
Zm最小,从而使得训练误差下降的最快。关于后续的证明,这里就不证了。
