论文:Bounding_Box_Regression_With_Uncertainty_for_Accurate_Object_Detection
Github:https://github.com/yihui-he/KL-Loss
CVPR 2019 CMU&&face ++
论文提出了一种回归边框的不确定性的方法,来实现对于边框的后续矫正。主要包括
- 修改了回归,x,y,width,height为,x1,y1,x2,y2
- 修改了smooth L1 loss为KL散度loss
- 修改了后续soft nms部分,增加了对于nms处理后边框的矫正(var voting)
最终实现了再MS-COCO数据集上,基于VGG-16的基础结构的Faster RCNN,精度从23.6%提升到29.1%。对于ResNet50的基础结构的FPN Mask-RCNN平均精度提升1.8%。
学习KL loss的优点:
- 数据集中的边框的标注的歧义性可以很好的捕捉到。边框的回归可以得到更小的loss从歧义性的标注边框中
- 网络学习的方差是有用的,可以应用于后续后处理中。
- 学习的概率分布具有可解释性。包括,网络预测的高斯分布,ground truth的狄拉克分布。
边框回归修改:

这里不再像传统的检测网络一样回归,x,y,width,height,而是改为回归x1,y1,x2,y2
其中t表示坐标预测的偏移,
t*表示groundtruth坐标的偏移,
xa,ya,wa,ha表示anchor的大小
x1,y1,x2,y2表示预测的坐标

论文这里假设预测的坐标数据(x,y,w,h)服从高斯分布,
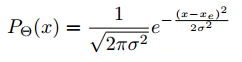
其中,Θ 是需要学习的参数
xe表示预测的x坐标
σ → 0,表示网络对于预测的坐标非常确信
ground truth的分布也可以假设为高斯分布,当方差σ → 0时,变为狄拉克分布(一种方差为0的高斯分布)
The ground-truth bounding box can also be formulated as a Gaussian distribution, with σ → 0, which is a Dirac delta function:

Xg表示ground truth的坐标位置。

网络结构上,需要新增一个分支,用于回归方差std,另外box的回归也修改为x1,y1,x2,y2。
KL loss:

算法用于回归预测坐标和label的两个数据分布的KL loss。
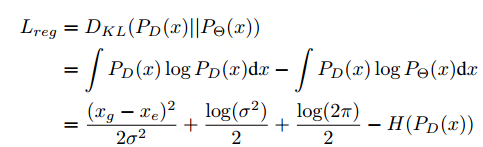
从上面式子可以看出,方差σ越大,回归的损失Lreg就越小。
由于上面式子的后2项log(2π)/2,H(PD(x))中木有需要学习的参数σ,所以可以将其当作常数项。因此可以直接去掉。
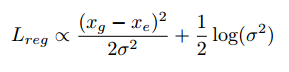
当方差σ变为1后,KL loss变化为欧式距离的loss,

将该式子对xe和σ求导,得到公式,

由于方差σ在分母,刚开始初始化为很小的值,训练中容易导致梯度爆炸,因此采用a来替代log(σ*σ),得到下面的式子,
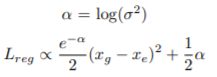
这样就成功的将需要学习的参数转化到分子上了。然后类比于smooth L1 loss,对上面的loss进行修改,得到下面最终需要优化的loss 函数

初始化的时候,需要设置a的均值为0.0001,方差为0。
方差投票Variance Voting:

论文整体需要学习的参数为{x1, y1, x2, y2, s, σx1, σy1, σx2, σy2},
方差投票基于soft nms进行加工修改,在完成soft nms之后,对得到的边框bm和得分p进行了基于网络学习到的方差σ的修正,其中,修正的方式采用下面的式子进行。
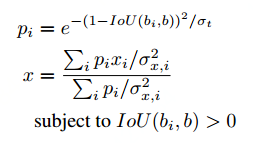
其中,两种相邻的box会得到较小的权重,
- 具有较大方差的box
- 和候选框有比较小的IOU的预测框
代码:
def soft(dets, confidence=None, ax = None):
thresh = cfg.STD_TH
if cfg.STD.METHOD == 'stdiou' and thresh > .1:
thresh = 0.01
sigma = .5
N = len(dets)
x1 = dets[:, 0].copy()
y1 = dets[:, 1].copy()
x2 = dets[:, 2].copy()
y2 = dets[:, 3].copy()
scores = dets[:, 4].copy()
areas = (x2 - x1 + 1) * (y2 - y1 + 1)
ious = np.zeros((N,N))
kls = np.zeros((N,N))
for i in range(N):
xx1 = np.maximum(x1[i], x1)
yy1 = np.maximum(y1[i], y1)
xx2 = np.minimum(x2[i], x2)
yy2 = np.minimum(y2[i], y2)
w = np.maximum(0.0, xx2 - xx1 + 1.)
h = np.maximum(0.0, yy2 - yy1 + 1.)
inter = w * h
ovr = inter / (areas[i] + areas - inter)
ious[i,:] = ovr.copy()
i = 0
while i < N:
maxpos = dets[i:N, 4].argmax()
maxpos += i
dets[[maxpos,i]] = dets[[i,maxpos]]
confidence[[maxpos,i]] = confidence[[i,maxpos]]
ious[[maxpos,i]] = ious[[i,maxpos]]
ious[:,[maxpos,i]] = ious[:,[i,maxpos]]
ovr_bbox = np.where((ious[i, i:N] > thresh))[0] + i
assert cfg.STD_NMS
if cfg.STD.METHOD == 'stdiou':
p = np.exp(-(1-ious[i, ovr_bbox])**2/cfg.STD.IOU_SIGMA)
dets[i,:4] = p.dot(dets[ovr_bbox, :4] / confidence[ovr_bbox]**2) / p.dot(1./confidence[ovr_bbox]**2)
else:
assert cfg.STD.METHOD == 'soft'
pos = i + 1
while pos < N:
if ious[i , pos] > 0:
ovr = ious[i , pos]
if cfg.STD.SOFT == 'hard':
if ious[i, pos] > cfg.TEST.NMS:
dets[pos, 4] = 0
else:
dets[pos, 4] *= np.exp(-(ovr * ovr)/sigma)
if dets[pos, 4] < 0.001:
dets[[pos, N-1]] = dets[[N-1, pos]]
confidence[[pos, N-1]] = confidence[[N-1, pos]]
ious[[pos, N-1]] = ious[[N-1, pos]]
ious[:,[pos, N-1]] = ious[:,[N-1, pos]]
N -= 1
pos -= 1
pos += 1
i += 1
keep=[i for i in range(N)]
return dets[keep], keep
实验结果:

KL loss,soft-nms,var voting对最终结果的贡献:

推理时间只增加2ms,

VOC准确性结果,

MS-COCO准确性结果,

总结:
边框回归不准确,不紧致,是检测领域一直以来的问题。在传统的目标检测中,可能影响不大,但是在行人重识别REID,OCR检测等领域,检测的框少一块,或者多一块,都会产生REID中的对齐问题,OCR中的识别错误问题。
本文的方法,本质上类似一个回归坐标+refinement的操作。但是更加具备可解释性。相比直接回归坐标偏移的refinement更加显得高端。
其他检测算法添加refinement分支的(CTPN,CornerNet,deeplabcut,CenterNet),但是那个refinemen是为了解决预测结果向上取整的误差,就是预测的结果还原会原图的误差,因为大多数预测的feature map是对原图进行了缩小的,该feature map上一个像素代表原图的好几个像素,还原回原图到底代表哪个像素是不知道的,这时候引入这样一个损失。这点上和本文的操作还是有点区别。
