一、网络结构
FCN涉及到了不同尺度的feature map的融合。
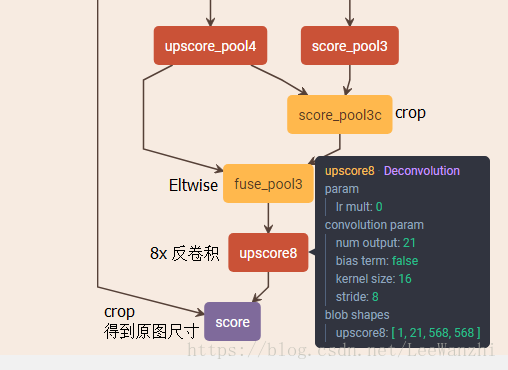
融合理由是:低层特征具有较多的的分辨率信息,更加精细,但语义信息较弱。高层特征具有较多语义信息,然而较粗糙,分辨率信息不足。为了融合语义信息和细节信息,对高层的feature map进行反卷积,然后将低层的feature map crop成相同尺寸,最后进行像素级的相加。
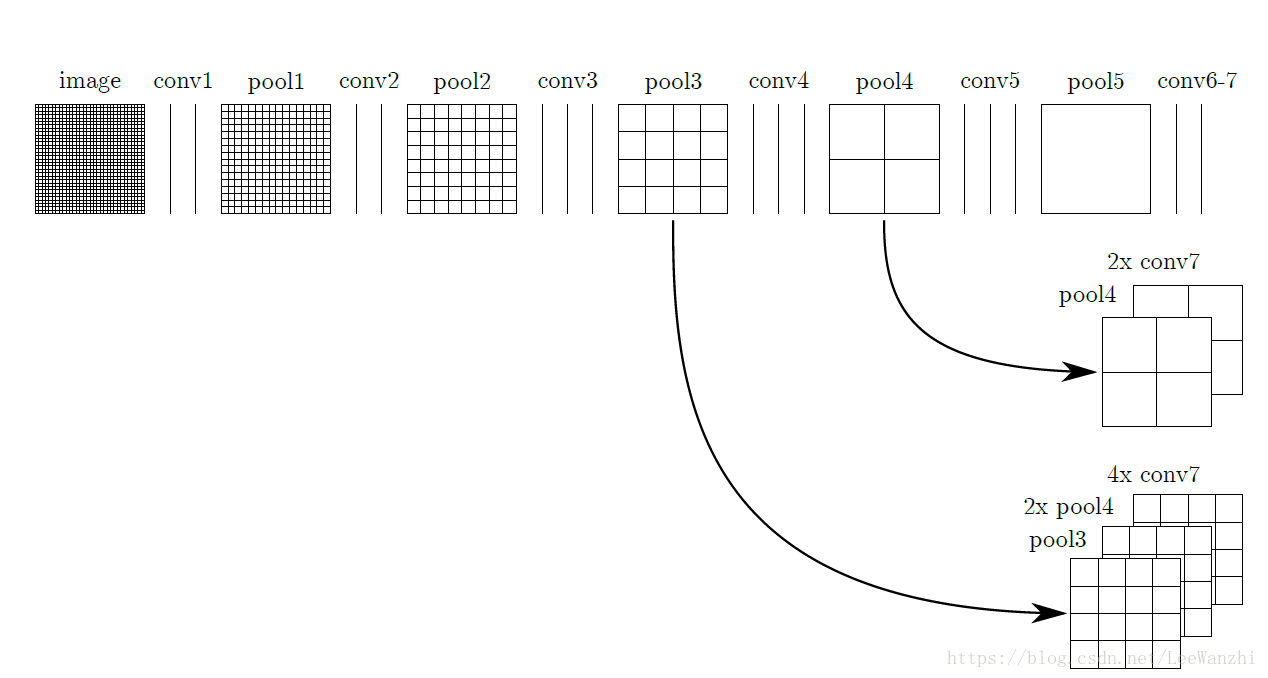
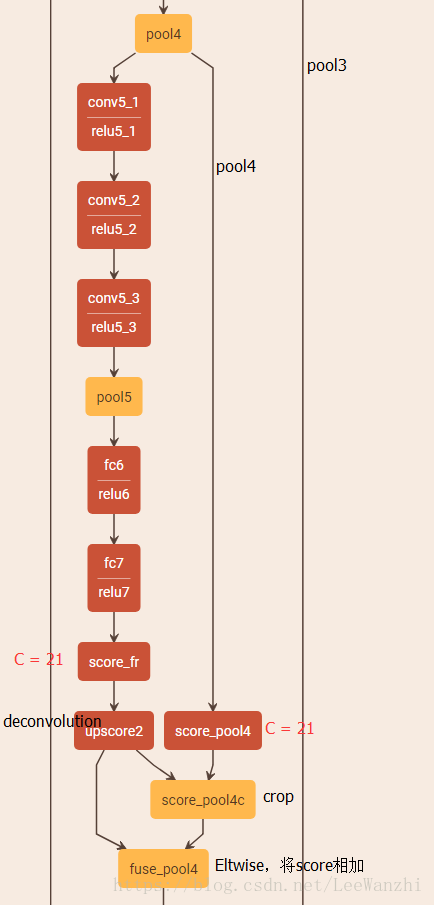
最后,从pool3处融合输出的feature map进行8倍反卷积,得到原图尺寸。
损失函数为交叉熵损失。
二、crop layer
layer {
name: "score"
type: "Crop"
bottom: "upscore8"
bottom: "data"
top: "score"
crop_param {
axis: 2
offset: 31
}
}
crop的原理是这样的: 两个bottom,一个作为crop之后的shape[n1,c1,w1,h1],一个作为待crop的feature map[n2,c2,w2,h2]。
axis = 2,表明[n,c,w,h]我们只针对w及w后面的维度进行crop,说白了就是平面crop。
offset = 31,表明我们从w2后面第31个像素开始crop,取w1个像素;同理从h2后面第31个像素开始crop,取h1个像素。
三、deconvolution
反卷积初始化值为双线性插值,并且参数可以学习。
而最后一层反卷积,则固定为双线性插值。
反卷积的forward就是卷积的backward。反卷积的backward就是卷积的forward。
四、度量标准(Evalueate Metric)
先介绍几个表达形式:
nij: 表示属于第i类但是被预测为第j类的像素数。
ncl: 表示类别数
表示第i类的像素总数。
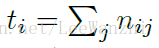
常用的度量标准是: mean IU. 即预测值与GT的交并比。
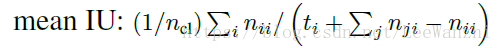
五、问题
FCN没有考虑像素之间的联系,孤立的对每个像素进行分类。