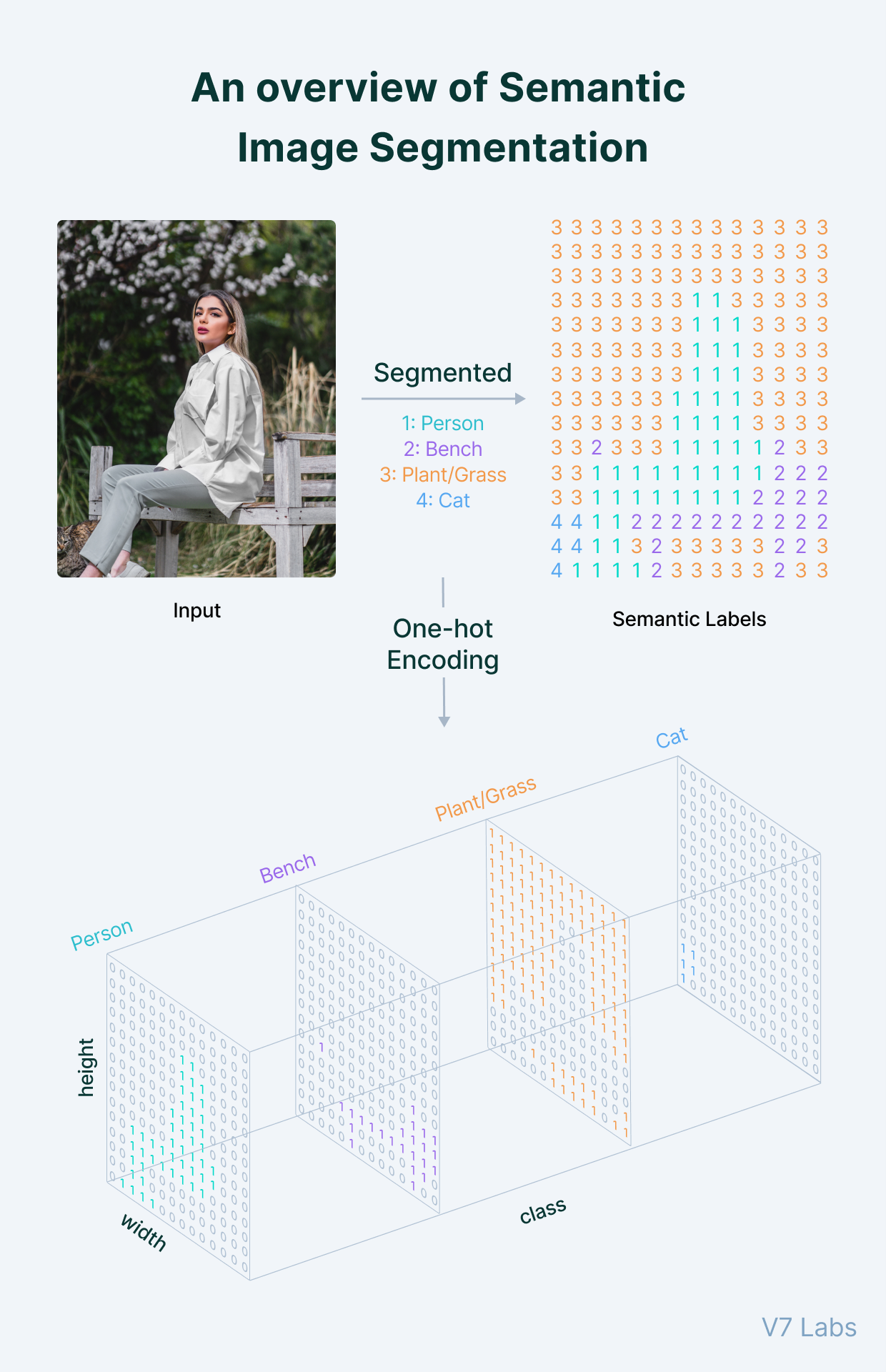
3.2、数据集(Dataset)
Pytorch提供了Dataset和Data Loader来帮助处理数据集。对于语义分割的训练数据,假设我们已经有了原始图像及对应的标签图像。为了训练网络模型,我们需要原始图像的Tensor数据,形状为(N,C, H, W)。其中N为样本数量,C为通道数量,H和W表示图像的像素高度和宽度。同时需要保证所有训练图像具有相同的C,H和W。标签数据可以使用(N,H,W)形状的标准标签,或者使用one-hot encoding标签。
3.2.1、自定义Dataset
要在pytorch中实现自定义数据集,我们可以继承pytorch的Dataset,并实现__len__(用来返回数据数量)和__getItem__(用来返回图像数据和标签数据)方法。这里我们在训练数据集目录下做一个npy文件,用来统计所有训练数据。npy文件的形状为(N, 2), N代表样本数量,2代表图像和标签。
我们生成1.jpg, 1.png, 直到237.jpg,237.png的237个训练样本的py文件数据
data = np.array([[f'raw_data/{x}.jpg', f'groundtruth/{x}.png'] for x in range(1, 237)])
root = os.getcwd() + "/final"
np.save(f"{root}/index.npy", data)
colors数据定义标签图像中,不同分类的颜色值
colors = torch.tensor([[0, 0, 0], # background
[128, 0, 0], # cat
[0, 128, 0]] # cow
)
接下来,我们定义一个自定义Dataset,读取图片我们使用的torchvision库,并指定返回RGB格式的数据。这里有一些细节需要我们注意下:
- pytorch输入需要的图片形状是(N,C,H,W),其中N由DataLoader来生成,所有自定义Dataset需要返回(C,H,W)形状的图像数据。一些其它的库,比如matplot,在显示图像时,需要的数据的形状是(H,W,C),我们需要在需要时,做必要的转换。
- 如果使用其它库来读取图像数据,比如opencv或者Python自身的Image库,需要注意返回数据的形状及不同维度代表的含义。比如opencv返回的图像数据的形状是(H,W, C),且C的顺序是BGR(torchvision是RGB)。在使用数据之前,可能需要我们对图像数据做对应的转换。RGB或者BGR并不影响模型计算,但需要和colors定义的顺序保持一致。
- 不同图像处理库,返回数据的类型是不同的。比如opencv返回的是numpy array. 而torchvision返回的数据是Tensor。
- 图像数据和标签数据,数据类型是有要求的,这点我们在“训练”章节或详细讨论
class SSDataset(Dataset):
def __init__(self, root: str, colors: Tensor, transform=None):
self.root = root
self.colors = colors
self.transform = transform
self.data_list = np.load(f'{root}/index.npy')
def __len__(self):
return len(self.data_list)
def __getitem__(self, index) -> T_co:
names = self.data_list[index]
image_file_path = f'{self.root}/{names[0]}'
mask_file_path = f'{self.root}/{names[1]}'
image = torchvision.io.read_image(image_file_path, ImageReadMode.RGB)
mask = torchvision.io.read_image(mask_file_path, ImageReadMode.RGB)
if self.transform is not None:
image = self.transform(image)
mask = self.transform(mask)
mask = OneHotEncoder.encode_mask_image(mask, self.colors)
return image, mask
###3.2.2、one-hot编码
直接读取的标签图像数据,是无法用于损失计算的。我们需要对它进行编码,编码的结果可以是典型的(H,W)形状的标签数据,或者采用one-hot编码。
one-hot编码能够把分类数据(cow, cat and etc.)编码成计算机可识别的二值数据, 它的最大优势是,编码后的分类数据是公平的,有利于计算机对离散分类数据的处理工作。对于语义分割,我们采用one-hot编码, 好处是如果我们需要对分割后的对象做对象检测,实例边框绘制等操作,one-hot编码的数据更加容易实现。
我们的one-hot编码实现了对图像的tensor数据和score进行one-hot编码的功能.对score进行one-hot编码的功能将用于模型训练和验证。
class OneHotEncoder():
@staticmethod
def encode_mask_image(mask_image: Tensor, colors: Tensor) -> Tensor:
height, width = mask_image.shape[1:]
one_hot_mask = torch.zeros([len(colors), height, width], dtype=torch.float)
for label_index, label in enumerate(colors):
one_hot_mask[label_index, :, :] = torch.all(mask_image == label[:, None, None], dim=0).float()
return one_hot_mask
@staticmethod
def encode_score(score: Tensor) -> Tensor:
num_classes = score.shape[1]
label = torch.argmax(score, dim=1)
pred = F.one_hot(label, num_classes=num_classes)
return pred.permute(0, 3, 1, 2)
3.2.3、数据预处理-数据变换(Transform)
原始的图像数据,并不总是能符合数据处理需求的标准,我们使用的不同的人工智能框架,也对应了不同类型和要求的输入数据格式, 所以我们需要对数据进行预处理。数据预处理是一个功能庞大的概念,在本文中,我们主要使用数据预处理中的数据变换功能,处理时机被分为两个阶段:图像加载阶段和数据处理阶段。
在图像加载阶段,我们面临了读取的图片的大小,长宽比例,图片格式不同,以及不同的图像处理库带来的数据差异等问题。对应的需要做缩放,裁减,格式转换,维度变换等一些列预处理操作。在上面数据集的代码中,我们预留了转换参数 transform, 可以根据需要插入多项预处理程序。
torchvision.transforms包中已经包含了大量预置的预处理程序,我们也可以定制自己的预处理程序. 如果使用的图片处理库时PIL或者opencv, torchvision的tranform包,提供了对PIL image或ndarray转换成Tensor的ToTensor转换,方便我们应对不同类型的数据。这里我们以图片缩放和长宽比统一为例,加入Resize和CenterCrop两个预处理程序。
transform = T.Compose([
T.Resize(224),
T.CenterCrop(224)
])
ss_dataset = SSDataset(root, colors, transform)
经过上述预处理程序,dataset返回的数据都将被裁减成224*224大小的数据。
在数据处理阶段,我们需要对数据进行归一化和正态分布,以便提升收敛速度。torchvison.transorm,提供了正态分布的预处理程序Normalize,其中需要均方差(mean)和标准差(std)两个参数。我们有两种方式来使用这个处理程序:
- 先进行归一化处理,再使用其它程序标准的经验方差和标准差来进行正态分布计算
- 对训练数据计算其均方差和标准差,再使用它们进行正态分布计算
这里我们使用第一种方式,归一化和正态分布独立成两个过程。Torchvisontion提供的其它格式图像数据转换成Tensor的ToTensor方法,内部做了归一化处理,我们当然可以先把我们的Tensor转换成(H,W,C)格式的ndarray再使用这个处理程序进行归一化, 但这样的操作显然不太优雅。 这里我们直接使用颜色的最大值255作为除数,直接对Tensor数据进行归一化处理。均方差和标准差我们使用imagenet提供的数值:
transform = T.Compose([
T.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
])
…
input = transform(input/255.)
数据处理阶段的预处理程序,我们选择提到dataset外面,在训练之前使用。那么在测试,验证和预测之前,需要注意必须要使用同样的数据预处理程序来对数据做预处理。
3.2.4、数据加载器(Data Loader)

pytorch 使用数据加载器来(DataLoader)来间接使用数据集。通常完整的数据集会被份组成训练集,验证集和测试集三部分,为了简化,我们把数据集中的数据按0.8, 0.2的比例,拆分成训练集和验证集二部分。
data_len = len(ss_dataset)
indices = list(range(data_len))
split = int(data_len * 0.8)
train_indices, val_indices = indices[:split], indices[split:]
train_data = Subset(ss_dataset, train_indices)
val_data = Subset(ss_dataset, val_indices)
BATCH_SIZE = 4
train_loader = DataLoader(
train_data,
BATCH_SIZE,
shuffle=True,
drop_last=True,
num_workers=4,
pin_memory=True,
)
val_loader = DataLoader(
val_data,
1,
shuffle=False,
drop_last=True,
num_workers=2,
pin_memory=False,
)
3.2.5、交叉验证(Cross Validation)
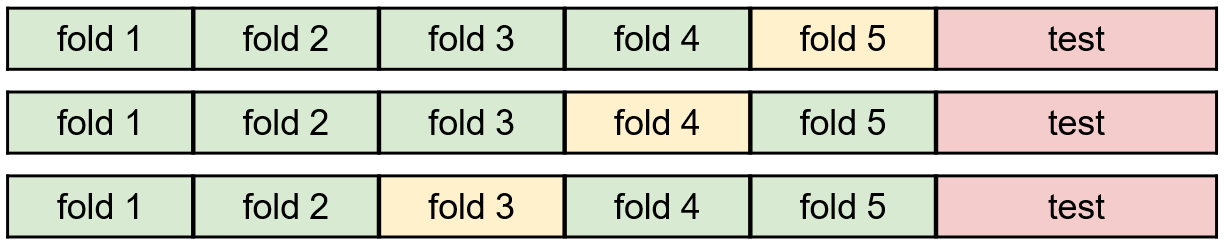
拆分了训练集和验证集的数据集,使得用于训练和验证的数据规模变得更小,不利于模型训练。交叉验证把样本数据分成k份, 称为k fold,选择其中一份用作验证,其它用作训练。之后再选择另一份用作验证,如此循环指定的次数或者全部fold都被作为验证集训练过。
交叉验证通常在样本数量较少时有用,当有大量样本时,通常不做交叉验证。
3.3、训练(Train)
至此,我们已经准备好了网络模型,数据集,并且使用数据加载器对数据集进行了拆分。接下来,我们使用数据集对网络模型进行训练,用以获取理想的权重值。
为了训练网络模型,我们需要关注已下几个方面:学习准则,优化和指标
3.3.1、学习准则(Criterion)
学习准则是模型如何学习的评估标准。对于语义分割网络,我们的学习准则需要能够对多个分类进行损失评估,常用的损失函数有Softmax, SVM , CrossEntropy。这里我们选用CrossEntropyLoss作为学习准则, 并在前向计算后通过学习准则计算损失。
Pytorch提供了CrossEntropyLoss的实现,是Softmax和CrossEntropy的组合,其内部实现首先使用Softmax把打分转换成不同分类的概率,再使用log函数把概率转换成熵值,最后使用NLLLoss计算损失值。
criterion = nn.CrossEntropyLoss()
…
# forward
score = model(input)
loss = criterion(score, target)
train_loss += loss.item()
3.3.2、优化(Optimizer)
优化是通过学习准则,优化模型参数,使得学习准则中的损失可以随着学习达到降低的效果。常用的优化函数有SGD,Adam。
这里我们选用SGD作为优化函数,配合动量来避免局部最优解, 并在反向传播时优化模型权重值。SGD通过backward来计算梯度,并调整权重值。对于权重参数,pytorch要求参数必须是requires_grad=True且is_leaf=False才会计算梯度。在权重初始化章节,我们的初始化方式,默认已经正确设置了这两个属性。另外,在模型训练上,我们通常先使用一个较大的学习率,用以加快收敛速度,之后使用较小的学习率,在小范围内寻找最优权重值。为此我们使用了lr_scheduler,用以在训练过程中动态降低学习率。
optimizer = torch.optim.SGD(model.parameters(), lr=learning_rate, momentum=momentum)
scheduler = lr_scheduler.StepLR(optimizer, step_size=Trainer.STEP_SIZE, gamma=0.5)
…
# backward
optimizer.zero_grad()
loss.backward()
optimizer.step()
…
scheduler.step()
3.3.3、指标(Metrics)
在模型训练,验证和测试阶段,我们需要获取一些指标参数,用来反馈结果是否理想。常见的指标有Loss,Precision,Recall, F Measure, Pixel Accuracy, Mean Accuracy, Mean IU,Frequency Weighted IU, Jaccard Similarity等。
# metrics
pred = OneHotEncoder.encode_score(score)
cm = Trainer.confusion_matrix(target, pred)
acc = torch.diag(cm).sum().item() / torch.sum(cm).item()
train_acc += acc
iu = torch.diag(cm) / (cm.sum(dim=1) + cm.sum(dim=0) - torch.diag(cm))
mean_iu += torch.nanmean(iu).item()
if verbose and iteration % iterations_per_epoch == 0:
print(f'epoch {epoch + 1} / {epochs}: loss: {train_loss/iterations_per_epoch:.5f}, accuracy:{train_acc/iterations_per_epoch:.5f}, mean IU:{mean_iu/iterations_per_epoch:.5f}')
train_loss = 0.0
train_acc = 0.0
mean_iu = 0.0
3.3.4、混淆矩阵(Confusion Matrix)
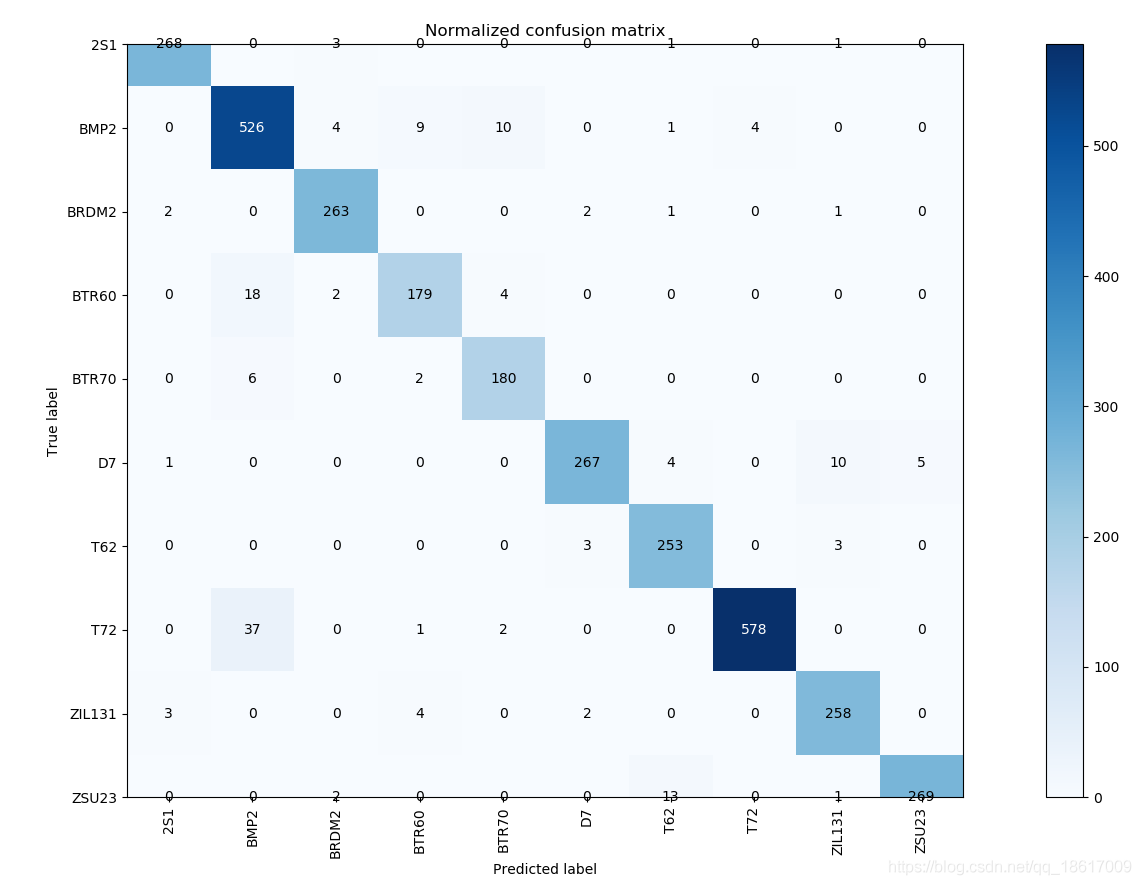
Confusion Matrix可以辅助计算诸如Precision, Recall, F Measure等多个指标值。这里我们使用Confusion Matrix来计算Pixel Accuracy和Mean IU。
@staticmethod
def confusion_matrix(target: Tensor, input: Tensor) -> Tensor:
if target.dim() != input.dim():
raise IOError('target and input must has same dimension')
if 4 == target.dim():
y_true = torch.flatten(target.permute(1, 0, 2, 3), 1, 3).int()
y_pred = torch.flatten(input.permute(1, 0, 2, 3), 1, 3).int()
elif 3 == target.dim():
y_true = torch.flatten(target, 1, 2).int()
y_pred = torch.flatten(input, 1, 2).int()
else:
raise IOError('target and input must be a 3D or 4D matrix')
n_classes = y_true.shape[0]
cm = torch.zeros((n_classes, n_classes))
for i in range(n_classes):
for j in range(n_classes):
num = torch.sum((y_true[i] & y_pred[j]).int())
cm[i, j] += num
return cm
现在,数据读取,学习准则,优化和指标结合起来的训练代码是这样子的:
class Trainer(object):
def __init__(self, model: torch.nn.Module, transform, train_loader: DataLoader, val_loader: DataLoader, class_names, class_colors):
self.model = model
self.transform = transform
self.visualizer = Visualizer(class_names, class_colors)
self.acc_thresholds = 0.95
self.best_mean_iu = 0
self.train_loader = train_loader
self.val_loader = val_loader
def train(self, epochs=50, learning_rate=1e-3, momentum=0.7, step_size=2, verbose=True):
start_time = datetime.now()
print(f'start training at {start_time}')
iterations_per_epoch = 20
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
optimizer = torch.optim.SGD(self.model.parameters(), lr=learning_rate, momentum=momentum)
scheduler = lr_scheduler.StepLR(optimizer, step_size=step_size, gamma=0.5)
criterion = nn.CrossEntropyLoss()
train_loss = 0.0
train_acc = 0.0
train_iu = 0.0
data_len = len(train_loader)
self.model.to(device)
self.model.train()
for epoch in range(epochs):
lr_current = optimizer.param_groups[0]['lr']
print(f'learning rate:{lr_current}')
for batch_index, data in enumerate(self.train_loader):
iteration = batch_index + epoch * data_len + 1
input = Variable(self.transform(data[0].float()/255).to(device))
target = data[1].float().to(device)
# forward
score = self.model(input)
loss = criterion(score, target)
train_loss += loss.item()
# backward
optimizer.zero_grad()
loss.backward()
optimizer.step()
# metrics
pred = OneHotEncoder.encode_score(score)
cm = Trainer.confusion_matrix(target, pred)
acc = torch.diag(cm).sum().item() / torch.sum(cm).item()
train_acc += acc
iu = torch.diag(cm) / (cm.sum(dim=1) + cm.sum(dim=0) - torch.diag(cm))
train_iu += torch.nanmean(iu).item()
if verbose and iteration % iterations_per_epoch == 0:
mean_acc = train_acc/iterations_per_epoch
mean_iu = train_iu/iterations_per_epoch
print(f'epoch {epoch + 1} / {epochs}: loss: {train_loss/iterations_per_epoch:.5f}, accuracy:{mean_acc:.5f}, mean IU:{mean_iu:.5f}')
train_loss = 0.0
train_acc = 0.0
train_iu = 0.0
scheduler.step()
end_time = datetime.now()
print(f'end training at {end_time}')
@staticmethod
def confusion_matrix(target: Tensor, input: Tensor) -> Tensor
if target.dim() != input.dim():
raise IOError('target and input must has same dimension')
if 4 == target.dim():
y_true = torch.flatten(target.permute(1, 0, 2, 3), 1, 3).int()
y_pred = torch.flatten(input.permute(1, 0, 2, 3), 1, 3).int()
elif 3 == target.dim():
y_true = torch.flatten(target, 1, 2).int()
y_pred = torch.flatten(input, 1, 2).int()
else:
raise IOError('target and input must be a 3D or 4D matrix')
n_classes = y_true.shape[0]
cm = torch.zeros((n_classes, n_classes))
for i in range(n_classes):
for j in range(n_classes):
num = torch.sum((y_true[i] & y_pred[j]).int())
cm[i, j] += num
return cm
…
}
这里需要注意的地方是从DataLoader取到的数据,除了预处理程序,我们还对输入数据和标签数据做了类型转换,这是因为我们使用的网络模型,优化器,对输入数据是有类型要求的。这里我们使用的网络模型和损失函数需要输入是float类型的数据,所以通过DataLoader获取的数据,我们都进行了类型转换。