FCN介绍

输入和输出
网络的输入可以为任意尺寸的彩色图像;输出与输入尺寸相同,通道数为:n(目标类别数)+ 1(背景)。
全卷积
网络在CNN卷积部分不用全链接而是替换成卷积的目的是允许输入的图片超过某一尺寸的任意大小。
上采样(Up sampling)
由于在卷积过程中,我们的特征图像变得很小(比如长宽变为原图像的1/32),为了得到原图像大小的稠密像素预测,我们需要进行上采样。
上采样的三种方式:分别对应最大池化、平均池化和卷积操作的反过来使用。
1、插值法: 在两个值之间插入一个值(个人理解)
2、反池化: 由池化后的特征图反池化后,填充,特征图变大(个人理解)
3、反卷积(转置卷积): 本质是通过训练(学习)来放大图片,需要注意步长的选择,使用的比较多。

类自编码器结构
如果采用下图所示的类自编码器结构,或者直接对最后一层的特征图进行上采样到原图大小的分割,我们会损失很多细节。
随着卷积次数越来越多,特征会慢慢提取出来,然后就会提取到原来图片中的动物,比如狗。
语义分割的跳级结构
增加Skips结构将最后一层的预测(有更丰富的全局信息)和更浅层(有更多的局部细节)的预测结合起来,这样可以在遵守全局预测的同时进行局部预测。
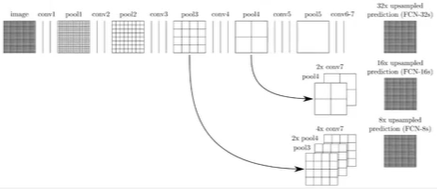
将底层(stride 32)的预测(FCN-32s)进行2倍的上采样得到的图像,并与从pool4层(stride 16)进行的预测融合起来(相加),这一部分的网络被称为FCN-16s。随后将这一部分的预测再进行一次2倍的上采样并与从pool3层得到的预测融合起来,这一部分的网络被称为FCN-8s。

全卷积神经网络(FCN)的缺点
1、得到的结果还不够精细,对细节不够敏感;
2、没有考虑像素与像素之间的关系,缺乏空间一致性等。