1.介绍
由于最近要用到语义分割模块,所以又把相应资料拿来读了一下,顺便也做一个笔记,发一篇博客,哈哈。今天的猪脚是FCN、SegNet和PSPNet,由于比较基础,就三个拿来一起介绍。其中,FCN是用深度学习做语义分割的开山之祖。
2.模型结构
1)FCN
它的结构与VGG(当然这个基础网络你用其它的也行)相似,只是把后面的全链接改成全卷积,为了得到更精细的结果,作者提出将第4层的输出和第3层的输出也依次反卷积,分别做16倍和8倍上采样,最后把不同层级的池化层上采样得到的结果图像叠加在一起
优点:端到端,适应任何输入图片大小
缺点:1.是得到的结果还是不够精细。进行8倍上采样虽然比32倍的效果好了很多,但是上采样的结果还是比较模糊和平滑,对图像中的细节不敏感。2.是对各个像素进行分类,没有充分考虑像素与像素之间的关系。忽略了在通常的基于像素分类的分割方法中使用的空间规整(spatial regularization)步骤,缺乏空间一致性。
2)SegNet
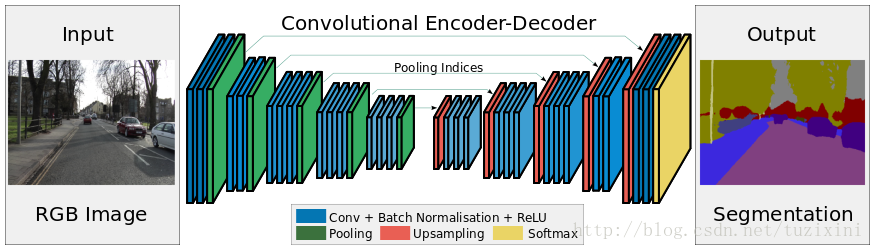
SegNet可以看出一个自编码器,只不过输出是一个分割图而已
SegNet的创新点在于解码器对低特征图的上采样处理方式。具体来讲,解码器利用在max-pooling过程中计算出的池化indices,计算对应的编码器的非线性上采样。这个过程就省去了上采样学习的过程。
3)PSPNet
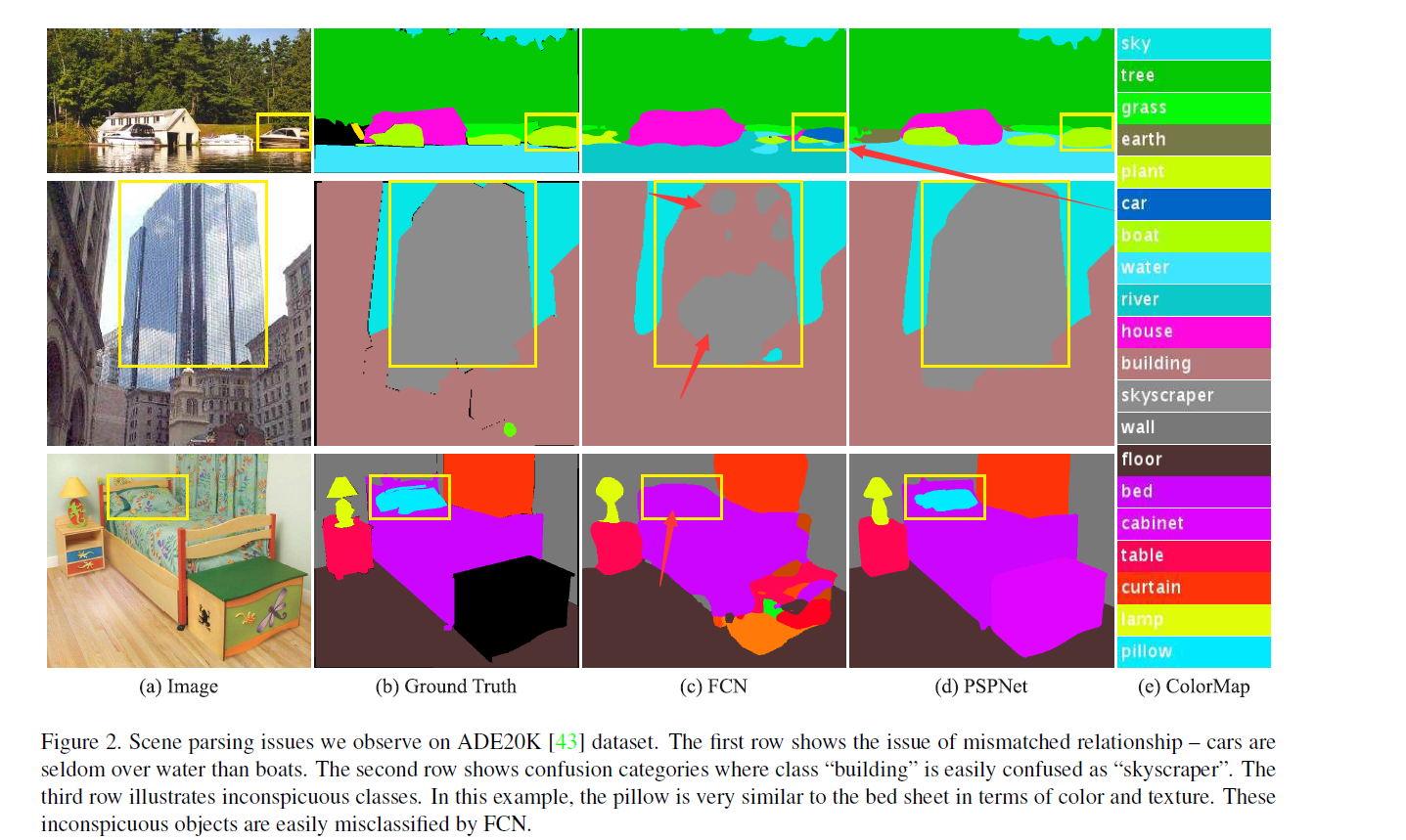
前面两个模型都不够精细,没有充分利用上下文关系,大多数先进的场景解析框架大多数基于FCN,但FCN存在的几个问题:
1.Mismatched Relationship:上下文关系匹配对理解复杂场景很重要,例如在上图第一行,在水面上的很可能是“boat”,而不是“car”。虽然“boat和“car”很像。FCN缺乏依据上下文推断的能力。
2.Confusion Categories: 许多标签之间存在关联,可以通过标签之间的关系弥补。上图第二行,把摩天大厦的一部分识别为建筑物,这应该只是其中一个,而不是二者。这可以通过类别之间的关系弥补。
3.Inconspicuous Classes:模型可能会忽略小的东西,而大的东西可能会超过FCN接收范围,从而导致不连续的预测。如上图第三行,枕头与被子材质一致,被识别成到一起了。为了提高不显眼东西的分割效果,应该注重小面积物体。
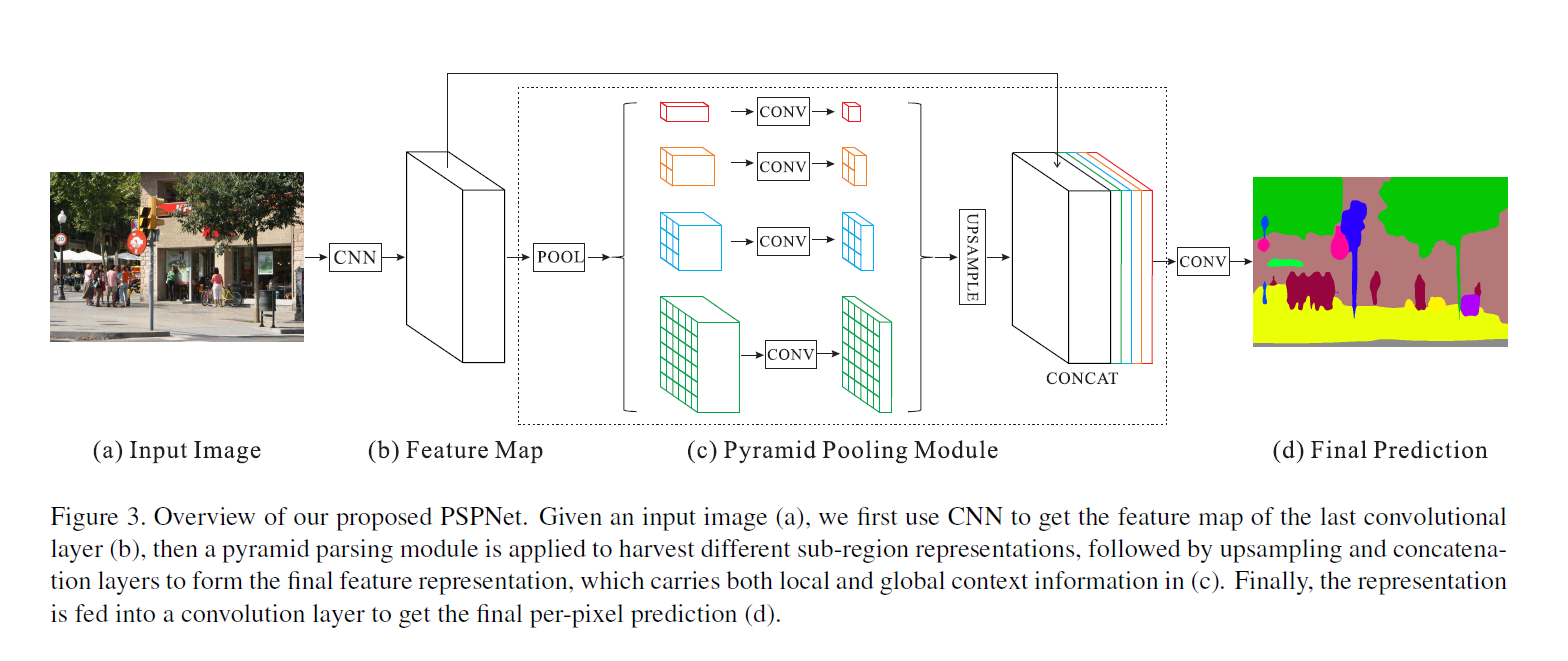
针对上面问题,作者提出了一个具有层次全局优先级,包含不同子区域之间的不同尺度信息的模块,该模块融合了4种不同金字塔尺度的特征,第一行红色是最粗糙的特征–全局池化生成单个bin输出,后面三行是不同尺度的池化特征。为了保证全局特征的权重,如果金字塔共有N个级别,则在每个级别后使用1×1的卷积将对应级别通道降为原本的1/N。再通过双线性插值获得未池化前的大小,最终concat到一起。