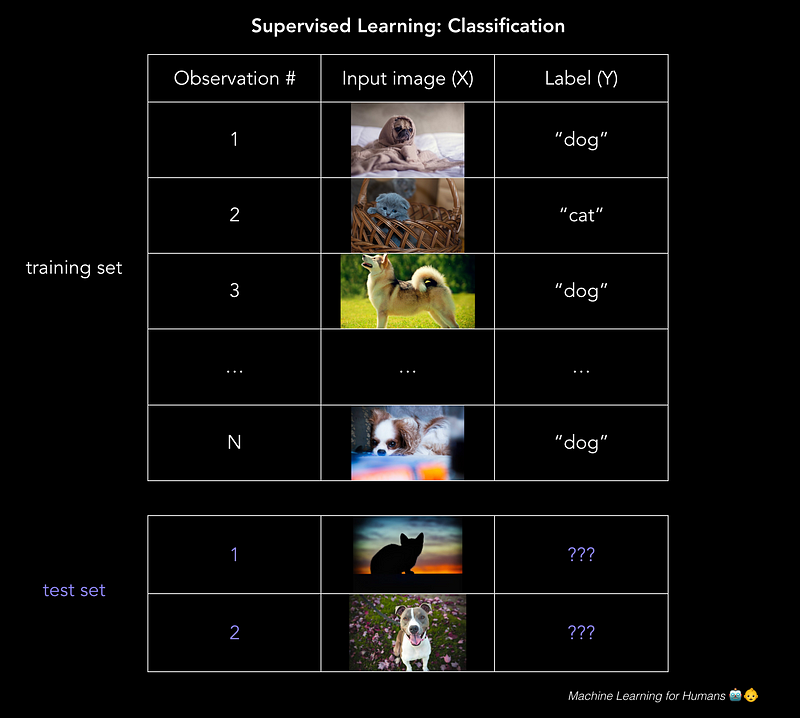
目录
使用逻辑回归和支持向量机(SVM)进行分类。
分类:预测标签
这封电子邮件是垃圾邮件吗?借款人是否会偿还贷款?这些用户是否会点击广告?Facebook图片中的那个人是谁?
分类 预测离散目标标签Y.分类是基于从标记的训练数据构建的分类模型将新观察分配给它们最可能属于的类的问题。
分类的准确性取决于您选择的算法的有效性,如何应用它,以及您拥有多少有用的训练数据。
Logistic回归:0还是1?
逻辑回归是一种分类方法:模型输出属于某一类的分类目标变量Y 的概率。
分类的一个很好的例子是确定贷款申请是否是欺诈性的。
最终,贷款人想知道他们是否应该给借款人一笔贷款,并且他们对申请实际上是欺诈性的风险有一定的容忍度。在这种情况下,逻辑回归的目标是计算应用程序欺诈的概率(在0%和100%之间)。有了这些概率,我们就可以设定一个门槛,高于这个门槛,我们愿意借给借款人,低于这个门槛,我们拒绝贷款申请,或者申请进一步审查。
虽然逻辑回归通常用于二级分类,其中有两个类,但请记住,分类可以使用任意数量的类别执行(例如,在为手写数字分配0到9之间的标签时,或使用面部识别来检测哪些朋友在Facebook图片)。
我可以使用普通的最小二乘法吗?
不。如果您在一组Y = 0或1的示例中训练了线性回归模型,您最终可能会预测一些小于0或大于1的概率,这是没有意义的。相反,我们将使用逻辑回归模型(或logit模型),该模型用于指定Y属于某个类的0%到100%之间的概率。
数学如何运作?
注意:本节中的数学很有意思,但可能更具技术性。如果您对高级概念更感兴趣,请随意浏览它。
logit模型是线性回归的修改,通过应用sigmoid函数确保输出介于0和1之间的概率,当绘制时,该函数看起来像稍后您将看到的特征S形曲线。

Sigmoid函数,用于压缩0到1之间的值。
回想一下我们简单的线性回归模型的原始形式,我们现在将其称为g(x),因为我们将在复合函数中使用它:

现在,为了解决模型输出小于0或大于1的问题,我们将定义一个新函数F(g(x)),它通过将线性回归的输出压缩到一个值来转换g(x)在[0,1]范围内。你能想到一个能做到这一点的功能吗?
你在想sigmoid功能吗?巴姆!普雷斯托!你是对的。
所以我们将g(x)插入到上面的sigmoid函数中,从而产生我们原始函数的函数(是的,事情变得元),输出0到1之间的概率:

换句话说,我们计算训练样本属于某个类的概率:P(Y = 1)。
在这里,我们在等式的左边隔离了p,即Y = 1的概率。如果我们想在右侧求解一个漂亮的干净β0+β1x+ε,那么我们可以直接解释我们将要学习的β系数,我们最终会得到log-odds ratio,或logit,on左侧 - 因此名称为“logit model”:

对数比值比只是比值比的自然对数,p /(1-p),它在日常对话中出现:
“哟,你认为Tyrion Lannister在这个权力的游戏中死去的 几率是多少?”
“嗯。它的发生率肯定是2倍。 赔率为2比1。当然,他似乎太重要了,不能被杀,但我们都看到了他们对Ned Stark的所作所为......“

请注意,在logit模型中,β1现在表示随着X变化的对数比值比的变化率。换句话说,它是“对数概率的斜率”,而不是“概率的斜率”。
对数概率可能稍微不直观,但值得理解,因为当您解释执行分类任务的神经网络的输出时它会再次出现。
使用逻辑回归模型的输出来做出决策
上面的逻辑回归模型的输出看起来像一条S曲线,显示基于X的值的P(Y = 1):

资料来源:维基百科
要预测Y标签 - 垃圾邮件/非垃圾邮件,癌症/非癌症,欺诈/非欺诈等 - 您必须为阳性结果设置概率截止值或阈值。例如:“如果我们的模型认为此垃圾邮件的可能性高于70%,请将其标记为垃圾邮件。否则,不要。“
阈值取决于您对误报与假阴性的容忍度。如果您正在诊断癌症,那么您对假阴性的耐受性非常低,因为即使患者患癌症的可能性很小,您也需要进行进一步的检查以确保治疗。因此,您为正面结果设置了一个非常低的阈值。
另一方面,在欺诈性贷款申请的情况下,误报的容忍度可能会更高,特别是对于较小的贷款,因为进一步的审查成本很高,而小额贷款可能不值得额外的运营成本和非欺诈性的摩擦。被标记为进一步处理的申请人。
通过逻辑回归最小化损失
与线性回归的情况一样,我们使用梯度下降来学习最小化损失的β参数。
在逻辑回归中,成本函数基本上是衡量真实答案为0时预测1的频率,反之亦然。下面是一个正则化的成本函数,就像我们用于线性回归的那样。
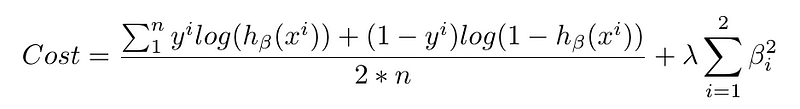
当你看到像这样的长方程时,不要惊慌!将其分解成块,并从概念上思考每个部分的内容。然后细节将开始有意义。
第一个数据块是数据丢失,即模型的预测与现实之间存在多少差异。第二个块是正则化损失,即我们对具有大量参数的模型进行了多少惩罚,这些参数会严重加重某些特征(请记住,这可以防止过度拟合)。
如上所述,我们将使用渐变下降最小化此成本函数,并且vo!我们建立了逻辑回归模型,以尽可能准确地进行类预测。
支持向量机(SVM)
“我们又在一间满是弹珠的房间里。为什么我们总是在一个装满大理石的房间?我可以发誓我们已经失去了它们。“
SVM是我们将要介绍的最后一个参数模型。它通常解决了与逻辑回归相同的问题 - 使用两个类进行分类 - 并产生类似的性能。这是值得理解的,因为算法在本质上是几何动机,而不是由概率思维驱动。
SVM可以解决的几个问题示例:
- 这是猫还是狗的形象?
- 这个评论是正面还是负面?
- 2D平面中的点是红色还是蓝色?
我们将使用第三个示例来说明SVM的工作原理。像这样的问题被称为玩具问题,因为它们不是真实的 - 但没有什么是真实的,所以它很好。
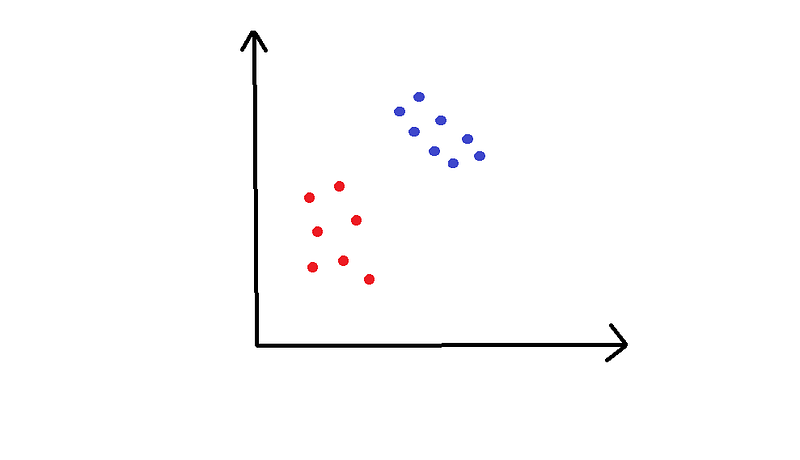
在这个例子中,我们在2D空间中有红色或蓝色的点,我们想要将两者分开。
训练集绘制在上图中。我们想在这个平面上对新的,未分类的点进行分类。为此,SVM使用分离线(或者,在多于两个维度中,使用多维超平面)将空间分成红色区域和蓝色区域。您已经可以想象分离线在上图中的外观。
具体来说,我们如何选择划线的位置?
以下是这样一行的两个例子:
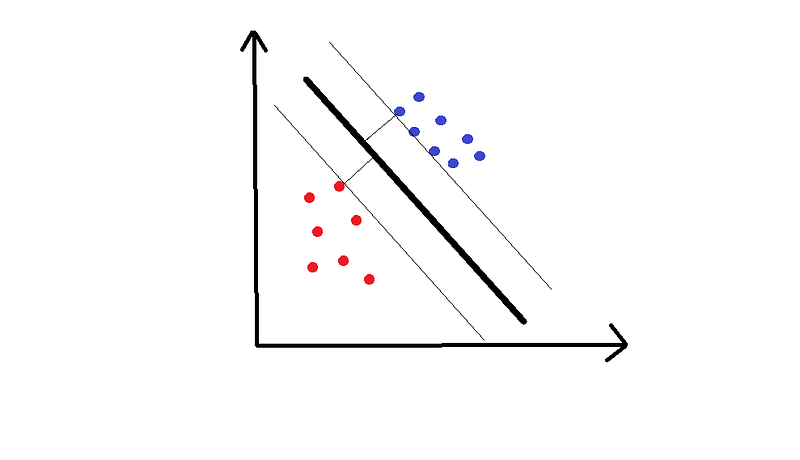
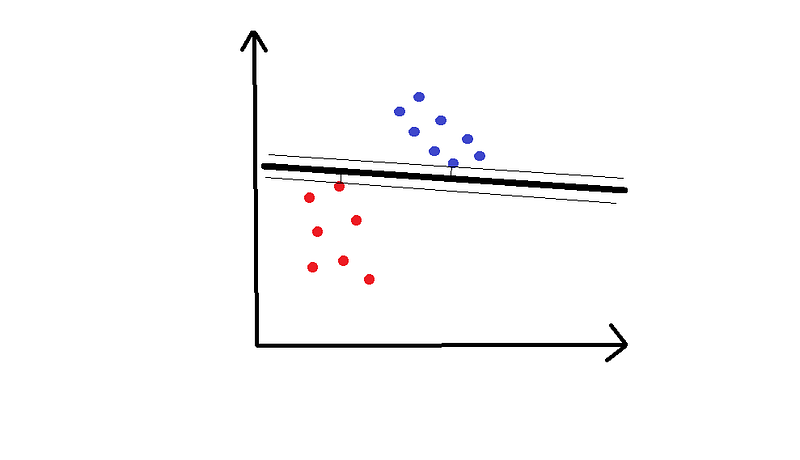
希望你能分享出第一条优秀的直觉。到线的两侧最近点的距离称为边距,SVM尝试最大化边距。你可以把它想象成一个安全空间:空间越大,嘈杂点被错误分类的可能性就越小。
基于这个简短的解释,出现了一些重大问题。
1.这项工作背后的数学如何?
我们想要找到最佳的超平面(在我的2D示例中是一条线)。这个超平面需要(1)干净地分离数据,线的一侧有蓝点,另一侧有红点,(2)边距最大。这是一个优化问题。解决方案必须遵守约束(1),同时最大化(2)中所要求的裕度。
解决这个问题的人类版本是拿一把尺子并继续尝试将所有点分开的不同线,直到你得到一个最大化边距的线。
事实证明,这种最大化是一种干净的数学方法,但具体细节超出了我们的范围。为了进一步探索,这里是一个视频讲座,展示了如何使用拉格朗日优化。
您最终得到的解超平面是根据其相对于某些x_i的位置定义的,这些x_i被称为支持向量,它们通常是最接近超平面的那些。
2.如果您无法干净地分离数据,会发生什么?
有两种方法可以解决这个问题。
2.1.软化“分离”的定义。
我们允许一些错误,这意味着我们允许红色区域中的一些蓝点或蓝色区域中的一些红点。我们通过在损失函数中为错误分类的示例添加成本C来实现这一点。基本上,我们说错误分类一点是可以接受但成本高昂的。
2.2.将数据投入更高的维度。
我们可以通过增加维数来创建非线性分类器,即包括x²,x³,甚至cos(x)等。突然间,当我们将它们带回到较低维度表示时,你会看到更加波浪形的边界。
直观地说,这就像在地面上放置红色和蓝色的大理石,使得它们不能被一条线干净地隔开 - 但如果你能让所有的红色大理石以正确的方式悬浮在地面上,你可以画一个平面分开他们。然后你让他们回到地面知道蓝色停止和红色开始的地方。

二维空间R²中的不可分离数据集,以及映射到三维上的相同数据集,第三维为x²+y²(来源:http://www.eric-kim.net/eric-kim-net/posts/1 /kernel_trick.html)

决策边界以绿色显示,首先在三维空间(左)中显示,然后返回到二维空间(右)。与上一张图像相同的来源。
总之,SVM用于分类有两个类。他们试图找到一个干净地将两个阶级分开的平面。如果无法做到这一点,我们要么软化“单独”的定义,要么将数据放到更高的维度,以便我们可以干净地分离数据。
成功!
在本节中,我们介绍了:
- 监督学习的分类任务
- 两种基本分类方法:逻辑回归和支持向量机(SVM)
- 重复概念:sigmoid函数,log-odds(“logit”),误报与假阴性,
在第2.3部分:监督学习III中,我们将进入非参数监督学习,其中算法背后的思想非常直观,性能对于某些类型的问题非常好,但模型可能更难以解释。
练习材料和进一步阅读
2.2a - 逻辑回归
Data School 对逻辑回归有一个很好的深入指南。我们还将继续向您介绍统计学习简介。请参阅第4章关于逻辑回归,第9章关于支持向量机。
要实现逻辑回归,我们建议您处理此问题集。不幸的是,你必须在网站上注册才能完成它。这就是生活。
2.2b - Down SVM兔子洞
要深入研究SVM背后的数学,请观看Patrick Winston教授的麻省理工学院6.034 课程:人工智能。并查看本教程以完成Python实现。
原文:https://medium.com/machine-learning-for-humans/supervised-learning-2-5c1c23f3560d