半监督学习@机器学习
转载请标明出处,本篇文章允许转载,禁止抄袭
半监督学习
背景:当有标记样本远远少于未标记样本时,监督学习仅能利用有标记样本进行构建模型,未标记样本信息被浪费,且有标记样本较小,训练样本不足,学习模型的泛华效果不理想。
问题:能否在构建模型时,将未标记样本利用起来?
前言
涉及概念
1.有标记样本 :对每个xi都有一个yi与其对应;Dl={(x1,y1),(x2,y2),……,(xl,yl)}
2. 未标记样本:仅有xi,没有真实值yi与其对应;Du={xl+1,xl+2,……,xl+u}
3. 监督学习:即为有标记的学习,可通过模型f得到y_hat(预测值),与真实值y(或者叫标签label)进行比较。
4. 泛化能力:学得模型适用于新样本的能力。详情请见绪论
一、概念
- 让学习器不依赖外界交互、自动地利用未标记样本来提升学习性能,就是半监督学习
注:依赖外界交互:①先使用Dl训练一个模型,②使用这个模型去测试Du中的一个样本,③通过询问外部数据/模型得知本样本的标记,④将这个新获得的有标记的样本加入Dl中,⑤重新训练一个新模型。重复②③④⑤过程。 若每次都挑出对改善模型性能帮助大的数据,则只需较少的依赖外部数据就能构建出比较浅的模型,从而大幅度降低标记成本。这样的学习方式称为“主动学习”。其目标是使用尽量少的“查询”(依赖)来获得尽量好的性能。
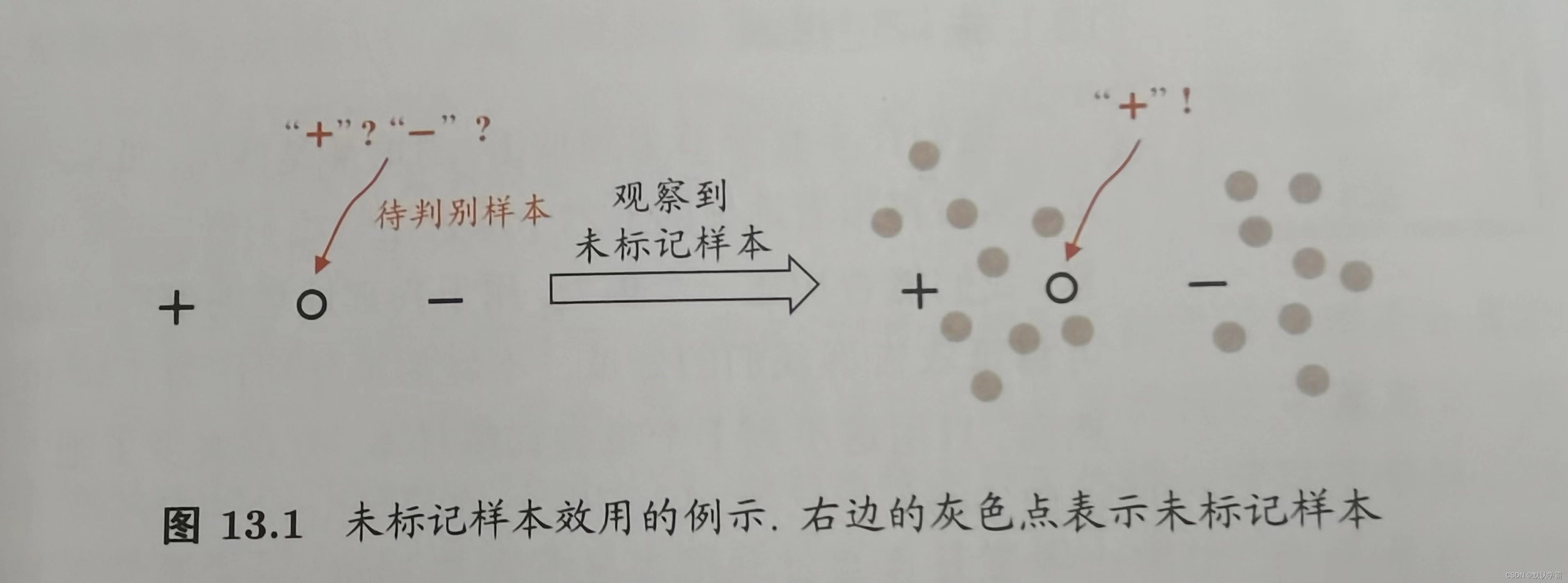
不依赖外部交互: 如图所示,当Dl仅有两个(一正一负)时,带判别样本恰处于两者中间,较难判别。当Du与Dl是从同样的数据源独立采样而来,则他们所包含的关于数据分布的信息对建立模型将大有脾益。如上图右边所示,同样只有两个有标记样本,但是引入未标记样本,我们可以看到数据分布,有较大的把握判定待判定样本为正例。
(一)假设
要利用未标记样本,要做一些将未标记样本所揭示的数据分布信息与类别标记相联系的假设。
常见有:聚类假设和流行假设
本质都是:相似的样本具有相似的输出
(二)划分
半监督学习进一步划分为纯半监督学习和直推学习
| 纯半监督学习 | 直推学习 | |
| 假设 | 未标记样本不是待预测数据 | 未标记样本是待预测数据 |
| 结果 | 希望学得的模型能够适用于既不属于Dl也不属于Du | 希望学得的模型能够适用于Du |
| 目的 | 在这些未标记样本上获得最优泛化性能 | |

图为主动学习、纯半监督学习、直推学习的区别
二、生成式方法
生成式方法是直接基于生成式模型的方法。
注:生成式模型:详情请见生成式模型和判别式模型
此类方法假设所有数据(无论是否有标记),都是由同一个潜在的模型“生成的”。
这个假设使得我们能够通过潜在模型的参数将未标记数据与学习目标联系起来(笔者认为是因为生成式模型能够在学习过程中,学习数据分布,更加注重类间相似度),而未标记数据的标记可看做模型的缺失参数,通常可基于EM算法进行极大似然估计求解。
- EM算法:常用的估计参数隐变量(缺失参数)的利器。
-
- E步:根据模型参数求隐变量
-
- M步:根据已观测变量和上一步求得的隐变量计算模型参数
-
- 循环迭代E,M步,直至收敛到局部最优解
- 极大似然估计:试图在待估参数的所有取值中找到一个能使数据出现的“可能性”最大的值。
此类方法的区别主要在于生成式模型的假设,不同的模型假设将产生不同的方法。
具体实现
对于给定数据集,其中样本为x,真实类别标记为y∈Y,其中Y={1,2,……,N}为所有可能的类别。
1,假设样本生成模型。得到样本概率密度函数:p(x)
(其中,概率密度函数的参数未知)
2,令f(x)∈Y表示模型f对x的预测标记。最大化后验概率并化简,得到关于模型未知参数的代数式(略,有需要的可以查看《西瓜书》p296)。
在此过程中,我们可以看出代数式中有一部分乘积是不涉及样本标记的,引入大量的无标记数据,可以有更大希望使得这一项的数据更为准确。从而通过未标记数据辅助提高分类模型的性能。
3,用E-M算法求解模型参数估计,不断迭代直至收敛,获得模型参数,即可进行分类。
优缺点
优点: 简单,易于实现,在有标记数据极少情况下,往往比其他方法性能更好。
缺点:模型假设必须准确,即假设生成式模型必须与真实数据分布吻合;否则利用未标记数据反而会降低泛化性能;在现实任务中,事先做出准确模型假设很难。
三、半监督SVM
半监督支持向量机简称S3VM,是支持向量机在半监督学习上的推广。
在不考虑未标记样本时,则为SVM,试图找到最大间隔划分超平面。
在考虑未标记样本时,则为S3VM,试图找到既能将两类有标记样本分开,且穿过数据的密度最低的区域进行划分。
半监督支持向量机中最著名的是TSVM,与标准SVM一样,也是针对二分类问题的学习方法。
算法思想:
对每个未标记样本进行正例/反例标记指派,在所有的可能中,寻求一个在所有样本中(包括有标记样本和指派过的未标记样本)间隔最大化的划分超平面。划分超平面确定后,每个样本当前指派的标记,即为预测结果。
半监督SVM是一个涉及巨大计算开销的大规模优化问题,因此,其研究重点为:如何设计出高效的优化求解策略。
四、图半监督学习
给定一个数据集,我们可将其映射为一个图,数据集中每个样本对应于图中一个结点,若两个样本之间的相似度很高(或相关性很强),则对应的结点之间存在一条边,边的“强度”正比于样本之间的相似度(或相关性)。我们可将标记样本所对应的结点想象为染过色,未标记样本为未染色。半监督学习就对应于"颜色"在图上扩散或传播的过程。一个图对应一个矩阵,这就是的我们能基于矩阵运算来进行半监督学习算法的推导与分析。(其中数学公式推导和算法思想过于繁琐,不再在此进行讲述,有需要的读者,详情请看《机器学习》周志华.p300。13.4图半监督学习)
优缺点
优点:概念清晰,且易于通过对所涉及矩阵运算的分析来探索算法性质。
缺点:
1.若样本数为O(m),算法中涉及的矩阵规模为O(m²),这使得此类算法很难直接处理大规模数据。
2.构图过程仅能考虑训练样本集,难以判知新样本在图中的位置。
在接受到新样本时,或将其加入原数据集对图进行重构并重新进行标记传播,或是需引入额外的预测机制。
五、基于分歧的方法
生成式方法、半监督SVM、图半监督学习等基于单学习器利用未标记数据。
基于分歧的方法使用多学习器,学习器之间的分歧对未标记数据的利用至关重要。
“协同训练”是此类方法的重要代表。 通过理解协同训练去理解基于分歧的方法。协同训练最初是针对“多视图”数据设计的,因此也被视为“多视图学习”的代表。
注:
多视图数据:在不少现实应用中,一个数据对象往往同时拥有多个“属性集”,每个属性集就构成了一个“视图”。
例如:对花朵数据集,有(<x1,x2,x3>,y),其中xi是样本在视图中的示例(基于该视图的一个属性向量),y是标记。对花朵数据集,则形式如(<视觉视图中的属性向量,嗅觉视图中的属性向量,触觉视图中的属性向量>,花朵种类),具体举例如下表:
| x1(视觉视图属性向量) | x2(嗅觉视图中的属性向量) | x3(触觉视图中的属性向量) | y(种类) |
| 红色 | 清香 | 花瓣光滑 | 玫瑰 |
| 花朵颜色鲜艳 | 味道比较淡 | 叶片边缘有锯齿感 | |
| 叶片明亮 | 花茎扎手 | ||
| 有刺 |
-
多视图具有相容互补性:
-
- 相容性:仅从x2视图上,我们无法得知是什么种类的花朵,但是加上x1视图信息,我们可以大概率判别为玫瑰;
-
- 互补性:另一种情况,我们仅从x1得知很可能是玫瑰,仅从x3得知也很可能是玫瑰,则我们可以很大可能判别为玫瑰。
协同训练算法思想:
协同训练正是很好的利用了多视图的“相容互补性”。
假设数据拥有两个充分且条件独立视图。
- 充分:指,每个视图都包含足以产生最优学习器的信息
- 条件独立:指,在给定类别标记条件下两个视图独立。
在上述假设条件下,用一个简单的办法来利用未标记数据:
1,在每个视图上基于有标记样本训练出一个分类器
2,让每个分类器分别去挑选自己“最有把握的”未标记样本赋予伪标记,并将伪标记样本提供给另一个分类器作为新增的有标记样本用于训练更新。
3,循环迭代第二步,直至两个分类器都不再变化,或达到预先设定的迭代轮数为止。
协同训练的好处
协同训练过程虽然简单,但经过理论证明,若两个视图充分且条件独立,则可利用未标记样本通过协同训练将弱分类器的泛化性能提升到任意高。在现实任务中,视图的条件独立性通常很难满足,因此性能提升不会那么大,但是研究表明,即便在更弱的条件下,协同训练仍可有效地提升弱分类器的性能。
在多视图数据上的协同训练算法之后,出现了许多变体,使得在单视图数据上也可使用协同训练,只需两个不同的学习器(不同视图、不同算法、不同数据采样、不同参数设置等)即可。
基于分歧的方法只需采用合适的基学习器,就能较少受到模型假设、损失函数非凸性和数据规模问题的影响,方法简单、理论坚实、适用广泛。
使用此方法,需生成具有显著分歧。性能尚可的多个学习器,当有标记样本很少,尤其是数据不具有多视图时,要做到这一点并不容易,需要有巧妙的设计。
六、半监督聚类
聚类是一种典型的无监督学习任务,然而在现实聚类任务中,我们往往能够获得一些额外的监督信息。于是可以通过半监督聚类来利用监督信息以获得更好的聚类效果。
注:
聚类:详情请见聚类
聚类任务获得的监督信息大致有两种类型:
1、监督信息为:“必连”与“勿连”约束,顾名思义,前者指样本必定属于一个簇,后者指样本必定不属于一个簇。代表算法:约束k均值算法。
2、监督信息是:少量的有标记样本。代表算法:约束种子k均值算法。
约束k均值算法与约束种子k均值算法
约束k均值算法思想:
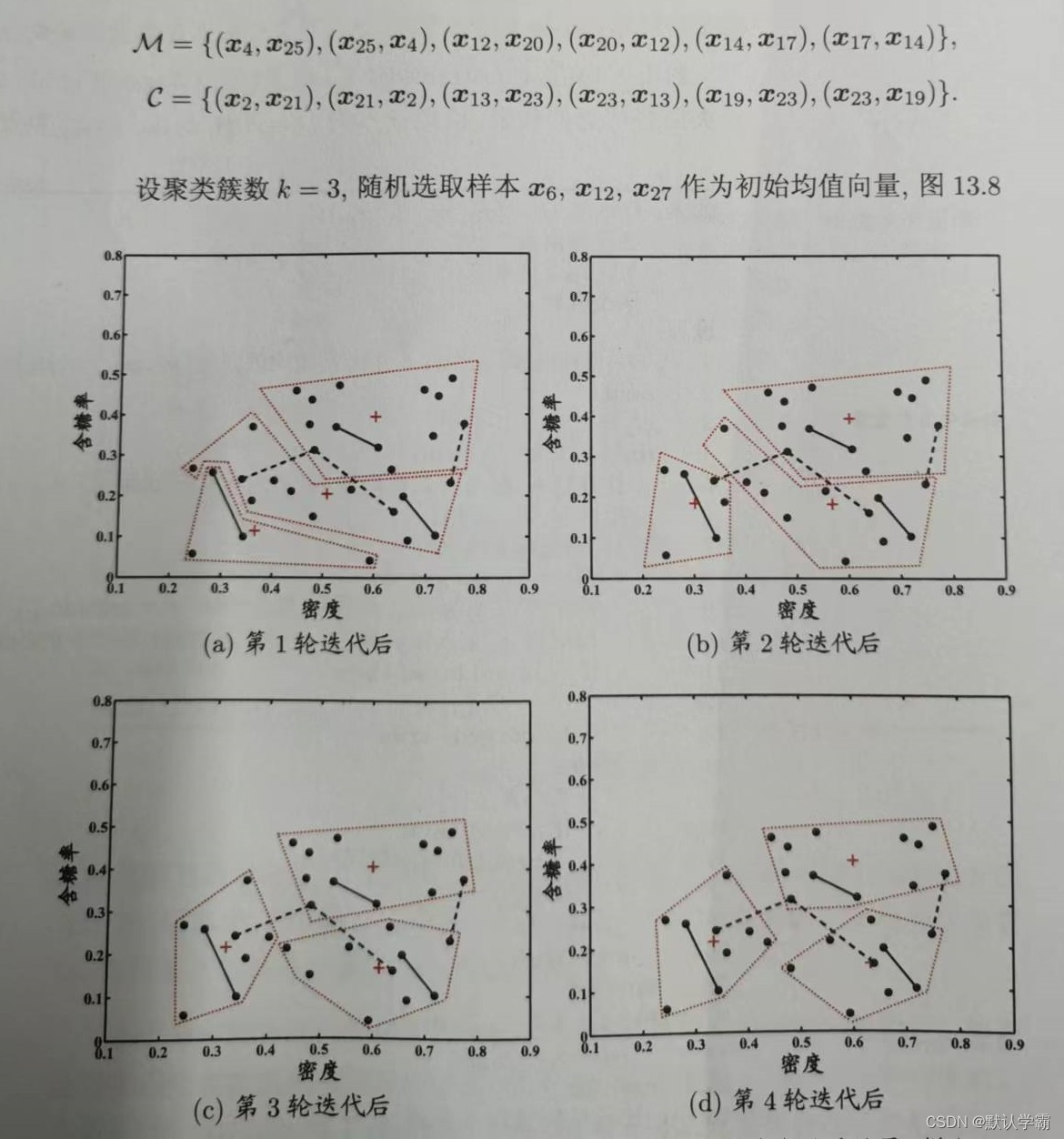
该算法是k均值算法的扩展,给定数据集D,以及必连关系集合M和勿连关系集合C,在聚类过程中,要满足M与C的约束得以满足,否则报错。循环迭代,直至均值向量不再发生变化。
算法描述:

示例迭代过程:
约束种子k均值算法思想:
直接将有标记数据作为“种子”,用他们初始化k均值算法的k个聚类中心,并且在聚类簇迭代更新过程中不改变种子样本的簇隶属关系,这样就得到了约束种子k均值算法。
算法描述:

示例迭代过程:

转载请标明出处,本篇文章允许转载,禁止抄袭