目录
从大脑中汲取灵感(或者只是统计数据?) - 神经网络内部会发生什么
神经网络的工作原理,原因和深度。从大脑中汲取灵感。卷积神经网络(CNN)和递归神经网络(RNN)。真实世界的应用程序。
通过深度学习,我们仍在学习函数f,将输入X映射到输出Y,而测试数据损失最小,就像我们一直在做的那样。回想一下我们关于监督学习的第2.1部分的初步“问题陈述” :
Y = f(X)+ε
训练:机器从标记的训练数据中学习f
测试:机器根据未标记的测试数据预测Y.
现实世界是混乱的,所以有时f很复杂。在自然语言问题中,大量的词汇量意味着很多功能。视觉问题涉及大量关于像素的视觉信息。玩游戏需要根据具有许多可能未来的复杂场景做出决策。到目前为止,我们所掌握的学习技术在我们正在使用的数据并不是非常复杂的情况下表现得很好,但目前尚不清楚它们如何推广到这样的场景。
深度学习非常擅长学习f,特别是在数据复杂的情况下。事实上,人工神经网络被称为通用函数逼近器,因为它们能够学习任何函数,无论多么摇摆,只有一个隐藏层。
我们来看看图像分类的问题。我们将图像作为输入,并输出一个类(例如,狗,猫,汽车)。
从图形上看,解决图像分类的深度神经网络看起来像这样:
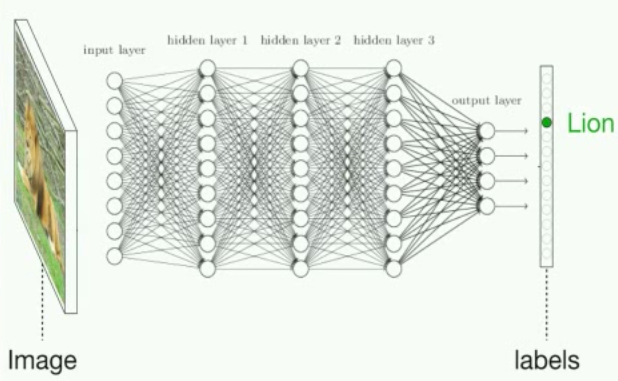
但实际上,这是一个拥有数百万个术语和大量参数的巨大数学方程式。输入X例如是由像素亮度的w- by- h矩阵表示的灰度图像。输出Y是类概率的向量。这意味着我们将每个类的概率作为输出作为正确的标签。如果这个神经网络运行良好,最高概率应该是正确的类。中间的层只是通过在每个隐藏层之后将激活 x 权重与非线性变换(激活函数)相加来进行一堆矩阵乘法,以使网络能够学习非线性函数。
令人难以置信的是,你可以使用梯度下降在完全相同的方式,我们用线性回归在做2.1部分以尽可能减少损失的方式来训练这些参数。因此,通过大量示例和大量梯度下降,模型可以学习如何正确地对动物图像进行分类。简而言之,这就是“深度学习”。
深度学习做得好,有些历史
人工神经网络实际上已存在很长时间了。他们的申请已经在历史上被称为控制论(1940 - 1960),联结(1980-1990),然后开始流行的深学习大约2006年的时候神经网络开始变得,很好,“更深”(Goodfellow等人2016)。但直到最近,我们才真正开始抓住它们的全部潜力。
正如安德烈·卡尔帕西(特斯拉的AI主任,我们倾向于认为是深度学习的萨满)所描述的那样,通常有“四个独立的因素阻碍人工智能:
- 计算(显而易见的一个:摩尔定律,GPU,ASIC),
- 数据(形式不错,不仅仅是在互联网上的某个地方 - 例如ImageNet),
- 算法(研究和想法,例如backprop,CNN,LSTM)和
- 基础设施(您下的软件 - Linux,TCP / IP,Git,ROS,PR2,AWS,AMT,TensorFlow等)“(Karpathy,2016)。
在过去十年左右的时间里,深度学习的全部潜力终于被(1)和(2)的进步所解锁,这反过来又导致了(3)和(4)的进一步突破 - 所以这个循环继续随着越来越多的人聚集在深度学习研究的前沿(想想你现在正在做什么!)
图片处理单元(GPU)的领先制造商NVIDIA的插图最初是为游戏而构建的,但结果非常适合深度神经网络所需的并行计算类型
在本节的其余部分,我们将提供生物学和统计学的一些背景,以解释神经网络内部发生的事情,然后通过深度学习的一些惊人应用进行讨论。最后,我们将链接到一些资源,这样您就可以自己应用深度学习,甚至可以使用笔记本电脑坐在睡衣的沙发上,以便在某些类型的问题上快速实现超过人类水平的表现。
从大脑中汲取灵感(或者只是统计数据?) - 神经网络内部会发生什么
神经元,特征学习和抽象层
当你阅读这些单词时,你没有检查每个单词的每个字母,或每个字母组成的每个像素,以得出单词的含义。您将抽象出细节并将事物分组为更高级别的概念:单词,短语,句子,段落。
Yuor abiilty to exaimne hgiher-lveel fteaures is waht aollws yuo to unedrtsand waht is hpapening in tihs snetecne wthiout too mcuh troulbe (or myabe yuo sned too mnay dnruk txets).
同样的事情发生在视觉中,不仅仅是在人类中,而是在动物的视觉系统中。
脑由神经元组成,其在被充分“激活”后通过向其他神经元发射电信号而“激发”。这些神经元在来自其他神经元的信号将增加到神经元的激活水平的程度方面具有延展性(含糊地说,连接神经元彼此的权重最终被训练以使神经连接更有用,就像参数一样在线性回归中可以训练以改善从输入到输出的映射。
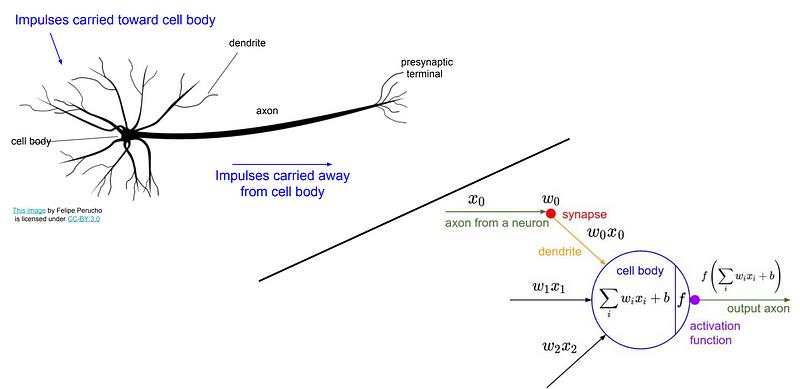
生物和人工神经元的并排插图,通过斯坦福大学的CS231n。这种类比不能太字面化 - 生物神经元可以做人工神经元不能做的事情,反之亦然 - 但是理解生物灵感是有用的。有关更多详细信息,请参阅维基百科对生物与人工神经元的描述。
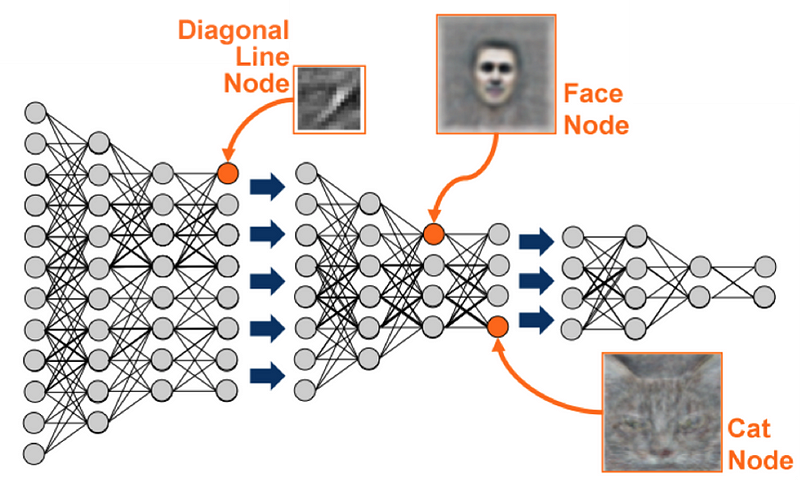
我们的生物网络以分层方式排列,因此某些神经元最终不会检测到我们周围世界的特定特征,而是更抽象的特征,即更低级特征的模式或分组。例如,人类视觉系统中的梭形面部区域专用于面部识别。

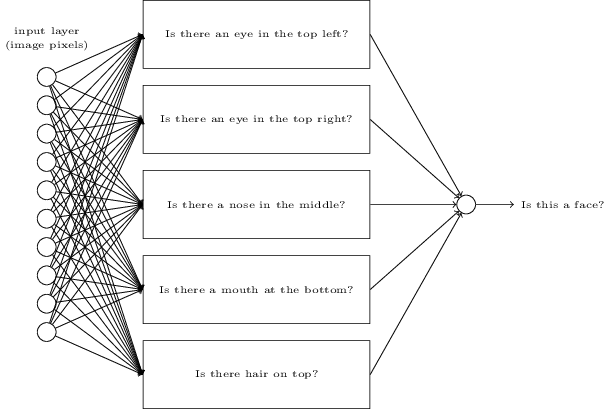
热门:通过NVIDIA学习越来越抽象的功能。下图:人工神经网络如何获取原始像素输入,开发中间“神经元”以检测更高级别的特征(例如,存在鼻子),并组合这些输出以创建最终输出。来自神经网络和深度学习的插图(尼尔森,2017)。
20世纪50年代,当研究人员David Hubel和Torsten Wiesel研究猫视觉皮层中的神经元时,发现了生物神经网络所呈现的这种等级结构。在将猫暴露于各种刺激之后,他们无法观察到神经活化:黑斑,光斑,挥手,甚至是杂志中女性的照片。但是在他们的沮丧中,当他们以一个对角线从投影仪上取下一张幻灯片时,他们注意到了一些神经活动!事实证明,非常特定角度的对角线边缘会导致某些神经元被激活。

通过了解神经元的背景
这是有意义的进化,因为自然环境通常是嘈杂和随机的(想象一个草地平原或岩石地形)。因此,当野生猫科动物感知到“边缘”,即与其背景形成对比的线时,这可能表明物体或生物在视野中。当边缘神经元的某些组合被激活时,这些激活将结合起来产生更抽象的激活,依此类推,直到最终的抽象是一个有用的概念,如“鸟”或“狼”。
深度神经网络背后的想法是模仿具有人造神经元层的类似结构。
为什么线性模型不起作用
借鉴斯坦福大学优秀的深度学习课程CS231n:卷积神经网络和视觉识别,想象一下我们想要训练一个神经网络,用以下正确的标签对图像进行分类:["plane", "car", "bird", "cat", "deer", "dog", "frog", "horse", "ship", "truck"]。
一种方法可以是使用训练示例构建每类图像的“模板”或平均图像,然后在测试期间使用最近邻算法来测量每个未分类图像的像素值的总距离,以每个模板。这种方法不涉及抽象层。它是一种线性模型,将每种图像的所有不同方向组合成一个平均模糊。
例如,它将需要所有的汽车 - 无论他们是面向左,右,中,还是无论他们的颜色 - 并平均他们。然后模板看起来相当模糊和模糊。

从斯坦福大学的CS231n中得到的例子:卷积神经网络和视觉识别,第2讲。
请注意,上面的马模板似乎有两个头。这并没有真正帮助我们:我们希望能够分别检测出正确的马或左侧的马,然后如果检测到其中任何一个功能,那么我们想说我们正在看一匹马。这种灵活性由深度神经网络提供,我们将在下一节中看到。
深度神经网络使用抽象层来处理图像分类问题
重复我们在本节前面解释的内容:输入图层将采用图像的原始像素亮度。最后一层将是类概率的输出向量(即图像是“猫”,“汽车”,“马”等的概率)
但是,我们不是学习将 输入与输出相关联的简单线性模型,而是构建网络的中间隐藏层,将学习越来越抽象的特征,这使我们不会失去复杂数据中的所有细微差别。
资料来源:Analytics Vidhya
正如我们描述动物大脑检测抽象特征一样,隐藏层中的人工神经元将学会检测抽象概念 - 无论哪个概念最有用于捕获最多信息并最大限度地减少网络输出精度的损失(这是一个实例)在网络内发生的无监督学习)。
这是以模型可解释性为代价的,因为当您添加更多隐藏层时,神经元开始表示越来越抽象且最终难以理解的特征 - 以至于您可能会听到深度学习被称为“黑盒优化”,其中您基本上只是随意地尝试一些东西,看看会发生什么,而不是真正理解里面发生的事情。
线性回归是可解释的,因为您决定了要在模型中包含哪些要素。深度神经网络更难以解释,因为这些特征是学习的,并且在英语的任何地方都没有解释。这一切都在机器的想象中。
一些扩展和进一步的概念值得注意
- 深度学习软件包。您很少需要从头开始实现神经网络的所有部分,因为现有的库和工具使深度学习实现更容易。其中有很多:TensorFlow,Caffe,Torch,Theano等等。
- 卷积神经网络(CNN)。CNN专门用于拍摄图像作为输入,并且对计算机视觉任务有效。它们也有助于深层强化学习。CNN的灵感来自于动物视觉皮层的工作方式,它们是我们在本文中引用的深度学习课程的重点,斯坦福大学的CS231n。
- 递归神经网络(RNN)。RNN具有内置记忆感,非常适合语言问题。它们在强化学习中也很重要,因为它们使代理能够跟踪事物的位置以及历史上发生的事情,即使这些元素不是一次全部可见。Christopher Olah 在语言问题的背景下写了一篇关于RNN和LSTM 的精彩演练。
- 深层强化学习。这是深度学习研究中最激动人心的领域之一,其中最近成就的核心是OpenAI击败专业Dota 2玩家,而DeepMind的AlphaGo在Go游戏中超越人类。我们将在第5部分深入探讨,但基本上我们的目标是将这篇文章中的所有技术应用于教授代理人以最大化奖励的问题。这可以应用于任何可以被游戏化的环境 - 从反恐精英或吃豆子等实际游戏,到自动驾驶汽车,交易股票,到(最终)现实生活和现实世界。
深度学习应用
深度学习正在几乎每个领域重塑世界。以下是深度学习可以做的令人难以置信的事情的一些例子......
- Facebook训练了一个由短期记忆增强的神经网络,以智能地回答关于指环王情节的问题。

来自FAIR(Facebook AI Research)的研究应用深度神经网络增强了单独的短期记忆,以智能地回答有关LOTR故事情节的问题。这是史诗的定义。
- 自动驾驶汽车依靠深度学习来完成视觉任务,例如了解道路标志,探测车道和识别障碍物。

资料来源:商业内幕
- 深度学习可以用于艺术生成等有趣的东西。一种叫做神经风格的工具可以令人印象深刻地模仿艺术家的风格,并用它来重新混合另一个图像。

梵高的星夜之夜的风格通过贾斯汀约翰逊的神经风格实现应用于斯坦福大学校园的照片:https://github.com/jcjohnson/neural-style
其他值得注意的例子包括:
- 预测药物发现的分子生物活性
- 用于照片和视频标记的面部和对象识别
- 为Google搜索结果提供支持
- 自然语言理解和生成,例如谷歌翻译
- 火星探险家机器人好奇号基于视觉检查自主选择值得检验的土壤目标
......还有很多很多。
现在去做吧!
我们在这里没有详细讨论如何在实践中建立神经网络,因为通过自己实现它们来更容易理解细节。这里有一些令人惊讶的动手实践入门资源。
- 利用神经网络的架构来了解不同的配置如何影响Google的神经网络游乐场的网络性能。
- 通过Google的本教程快速启动并运行:TensorFlow和深度学习,没有博士学位。以高于99%的准确度对手写数字进行分类,熟悉TensorFlow,并在3小时内学习深度学习概念。
- 然后,至少完成斯坦福大学CS231n的前几个讲座以及从头开始构建双层神经网络的第一个任务,以真正巩固本文所涵盖的概念。
更多资源
深度学习是一个广阔的学科领域。因此,我们还编写了一些我们在这个主题上遇到的最好的资源,以防你想要更深入。
- Deeplearning.ai,Andrew Ng的新深度学习课程,有关该主题的全面教学大纲
- CS231n:用于视觉识别的卷积神经网络,斯坦福大学的深度学习课程。我们见过的最好的治疗方法之一,有优秀的讲座和说明性的问题集
- 深度学习和神经网络 - 可访问但严谨
- 深度学习书 - 基础,更多数学
- Fast.ai - 更少理论,更多应用和黑色四四方方
- 见格雷格·布罗克曼(OpenAI的CTO)的回答这个问题:‘什么是回暖深度学习技能的工程师?最好的方法’ 上的Quora
接下来:玩一些游戏的时间!
最后,但最重要的是,第5部分:强化学习。
原文:https://medium.com/machine-learning-for-humans/neural-networks-deep-learning-cdad8aeae49b