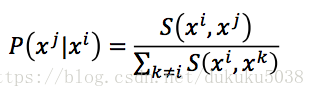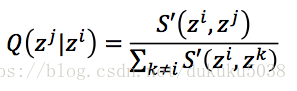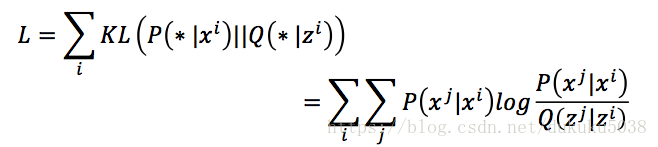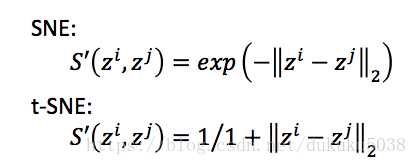临近编码 Neighbor Embedding
在非监督学习降维算法中,高纬度的数据,在他附近的数据我们可以看做是低纬度的,例如地球是三维度的,但是地图可以是二维的。
那我们就开始上算法
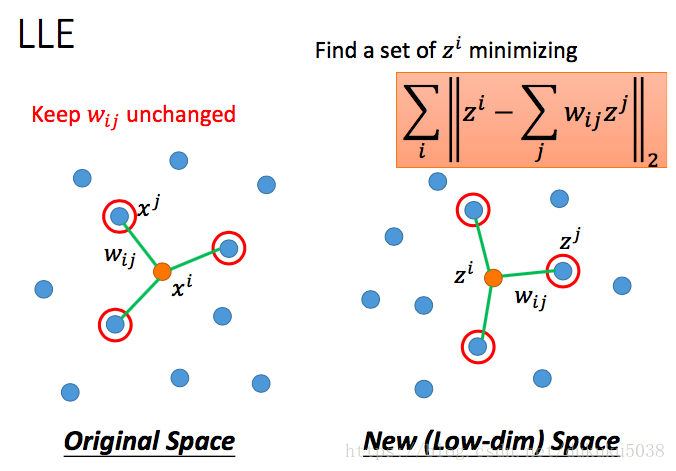
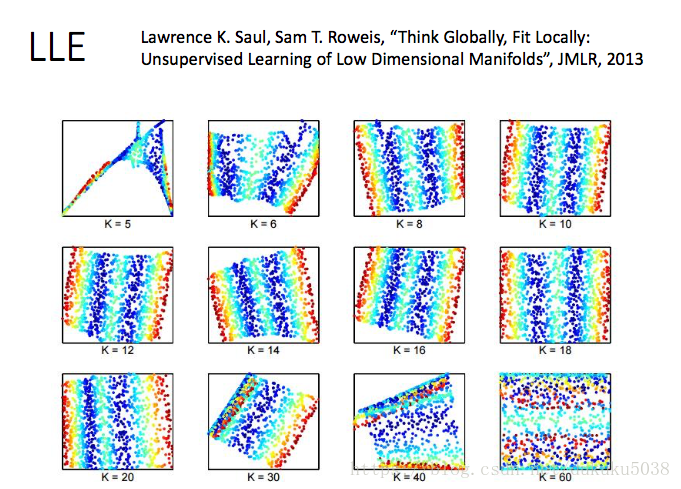
1. Locally Linear Embedding (LLE)
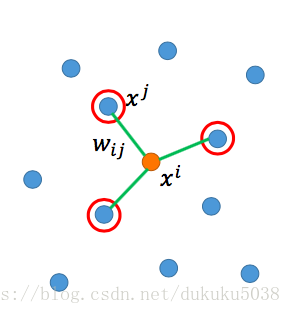
我们需要找到
来最小化:
找到
后,我们固定它,然后在z中进行判断
实验:
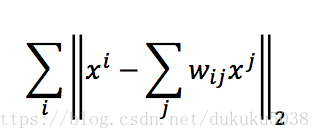

2. Laplacian Eigenmaps
我们回一下半监督模型中: 如果x1 和 x2 在高密度空间相似,那么他们的结果y1,y2也形似,S 衡量label 平滑度
如果x1 和 x2 在高密度空间相似,z1 和z2也相似
那么zi和zj等于0 怎么办?我们加入条件限制:

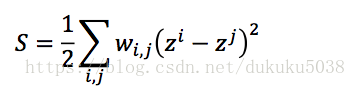

2. T-distributed Stochastic Neighbor Embedding (t-SNE)
前面提到的算法的问题是,相似的数据离得很近,但是很有可能会重叠
(1) t-SNE算法首先计算相似度(x和z分布)
我们需要找到z的集合,使得P和Q的相似度KL最小
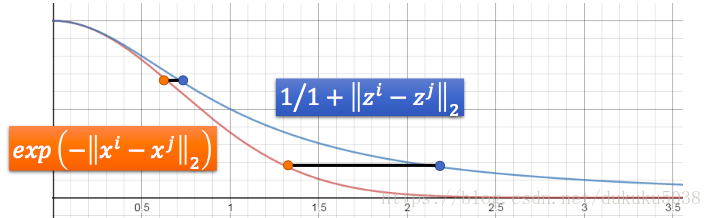
(2)衡量相似度函数的选择
横坐标是zi和zj的距离
可见t-SNE所使用的相似度函数,在距离增大的过程中,相似度下降较慢,更能区分不同的相似度,但是使用的时候注意,不应该是动态数据,而经常是训练好的静态数据做可视化。