文章目录
Applications(Task) and Model
- Linear Regression
- 用途: 定价(房屋, 债卷, 股票), 资产, 物质成分浓度

- 用途: 定价(房屋, 债卷, 股票), 资产, 物质成分浓度
Model Representation
- model : 下面的一次式
- parameter : theta
- 根据训练数据, 学习合适的theta0, theta1

- 一般的机器学习包含 预测 和 训练两个过程
- 重点是训练过程(确定参数)
Cost Functions of task
- 损失函数用来衡量theta0, theta1是否合适
- 采用squared error(平方误差)的方法
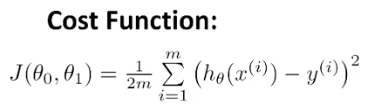
- 损失函数越小, 就说明模型拟合数据效果越好
- 目标 : 求二次函数的最小值, 求导, 导数为0
- 这里的x, y为常量, theta0, theta1为自变量
- m 表示 训练样本的个数
- n 表示每个样本的特征数
- (x, y) 训练样本
- x : 一个数
- x : 一个向量 (列向量)
- X : 多个向量(矩阵)
- 右上角的(i) : 表示第i个训练样本
损失函数为什么是二次方
- 绝对值和一次函数也可以一定程度上衡量误差, 但是一次函数中theta也是一次, 求导后就没了theta, 无法确定theta大小.
- 如果把所有参数theta组合列出来, 然后分别计算损失函数的值, 从中挑选一个最小的, 复杂度太大
- 求导法可以直奔优化的主题, 求导等于0的目的是为了确定参数theta
- 如果是三次方, 虽然导数有零点, 但是三次函数没有最小值(最小值在无穷小处), 当theta取一个无穷小值时, 虽然损失函数最小, 但是模型不是最优的(该theta无法很好的进行预测). 损失函数最小和模型最优要结合起来.
- 三次方的时候, 该损失函数其实没有意义 (并不能代表预测值和专家标注之间的距离)
Optimization
- 目标 : 使用带标注的训练数据挑选出最好的参数组合 (theta0, theta1). (训练过程)
- 方法 (针对的是损失函数 而不是 模型函数)
- 解析式求导
- 梯度下降法
解析式求导法

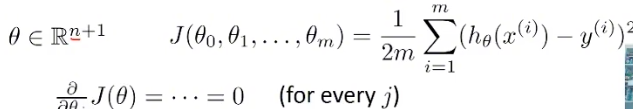
- 的数目是维度+1, 因为还有theta0作为截距, 不作为自变量.
- 损失函数相对于每一个theta参数进行求导, 模型参数之间需要相互独立