在spark的简介中我们已经说过了,为了让spark的处理速度加快,其中有一个解决办法就是引入了一个分布式的弹性数据集--RDD
那什么是RDD:RDD(Resilient Distributed Dataset)弹性数据集,是spark中的最基本的数据抽象,虽然说RDD是一个数据集,但是,它不存储数据,他表示的是一个不可变的,可分区的元素并行计算的集合,允许用户在执行多个查询时将工作缓存到内存中,当后面的计算需要使用到这部分数据的时候可以直接调用,而且内存的运行速度较之磁盘的速度非常之快,极大的提升了spark的运行效率
RDD的属性:
1、A list of partiton:RDD是由一个个的partition组成的,每一个partition会被一个计算任务处理,并由最后一个RDD中的partiton的个数决定整个程序有多少并行的任务,,在创建任务的时候可以指定partition的个数,默认是程序分配的core的个数
2、A function for computing each partiton:RDD在进行计算的时候会使用一个conpute的核算函数,对迭代器进行复核,不需要每次保存结果,也就做到了和mapreduce的区别,在计算的时候不用每一次计算结果都落地磁盘然后在使用的时候重新读取磁盘进行计算
3、A list of dependencies on other RDDs :RDD没经过一个计算算子都会重新生成一个RDD,但RDD以来其他的RDD,这就构成了RDD之间的依赖关系,形成一个类似管道的通路,当有数据丢失的时候,可以根据依赖关系,直接去其他的RDD上重新计算生成,不用从头读取文件在计算,节省了时间和资源
4、Optuinally a partitioner for key-value RDDs:,如果RDD中的元素是二元组类型的,那么这个RDD就是KV格式的RDD,而在决定partiton的时候,就是根据RDD的key再决定将计算结果写入到哪一个分区中
5、Optionally, a list of preferred locations to conpute each spllit on:为了提升计算的性能,所以遵循计算向数据移动的理念,,RDD会提供一系列的最佳的计算位置,而且见底了网络和磁盘IO,提升了效率
在书写sparkRDD的运行程序的步骤,
1、将HDFS数据加载到RDD textfile
2、使用RDD的一系列方法(transdormation算子)对RDD中的数据进行转换
3、当遇到action类算子之后启动,触发执行
RDD的依赖关系以及区别
RDD分为宽依赖和窄依赖两种依赖关系,通过这两种依赖关系切割job,划分stage,将RDD分成不同的块进行计算
宽依赖:父与子的对应关系是一对多的关系,在运行过程中会发生shuffle,每一个RDD的执行要等上一个RDD的所有task都结束之后再运行,
窄依赖:父与子的对应关系是一对一的关系,在运行过程中不会发生shuffle,所有的RDD同时运行,没有先后关系
在计算RDD的时候的两种个算子
Transformation算子(懒执行,需要Action类算子进行触发):
1、不发生shuffle(map、flatmap)
2、发生shuffle(groupByKey),在分组过程中会发生磁盘或者网络之间的IO,这个过程我们称之为shuffle,关于shuffle会单独讲解
Action算子:触发程序执行的算子,会将程序推送到Executor上执行
控制类算子:cache。Persist,将RDD进行持久化,cache默认的持久化到内存中进行计算,而persist可以设置不同的持久化级别
1、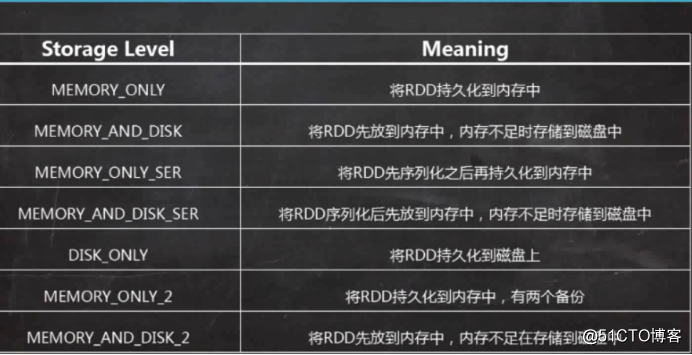
2、将数据持久化到内存中,提高了计算的效率
关于RDD的相关知识基本总结完了,但是,为了一个更加直观的方式展示,下面会介绍一个spark中的hello world案例----wordcount
特别的,RDD4中的每一个partition的数据是根据分区器的策略来决定的,默认是hashPartiton(就是根据key的hashcode与RDD4的分区数来取莫,决定这条记录要去哪一个分区,相同的key一定在一个分区中)