文章目录
一、案例分析:Spark RDD实现单词计数
(一)案例概述
单词计数是学习分布式计算的入门程序,有很多种实现方式,例如MapReduce;使用Spark提供的RDD算子可以更加轻松地实现单词计数。
在IntelliJ IDEA中新建Maven管理的Spark项目,并在该项目中使用Scala语言编写Spark的WordCount程序,最后将项目打包提交到Spark集群(Standalone模式)中运行。
(二)实现步骤
1、新建Maven管理的Spark项目
在IDEA中选择File→new→Project…,在弹出的窗口中选择左侧的Maven项,然后在右侧勾选Create fromarchetype复选框并选择下方出现的org.scala-tools.archetypes:scala-archetype-simple项(表示使用scala-archetype-simple模板构建Maven项目)。
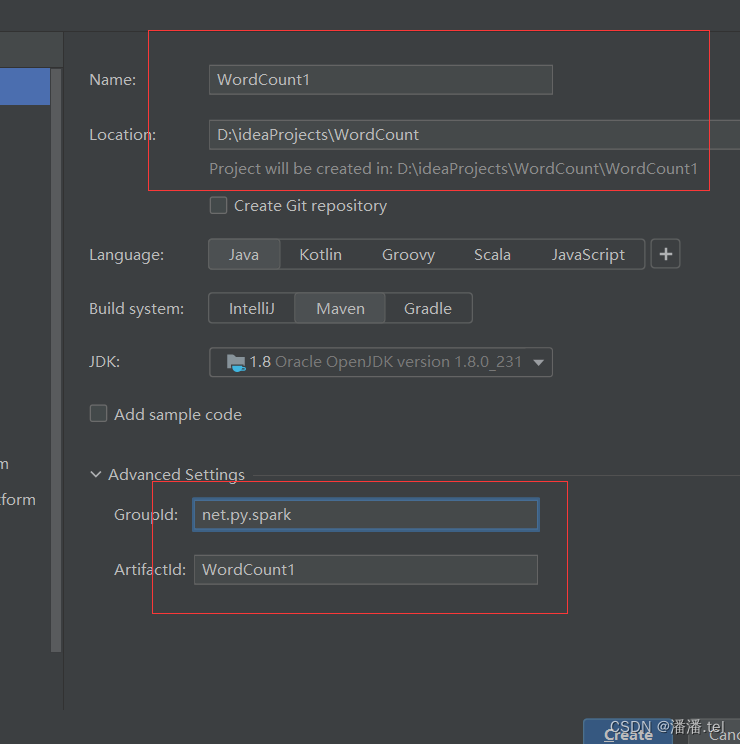
在弹出的窗口中填写GroupId与ArtifactId,Version保持默认设置即可,然后单击Next按钮
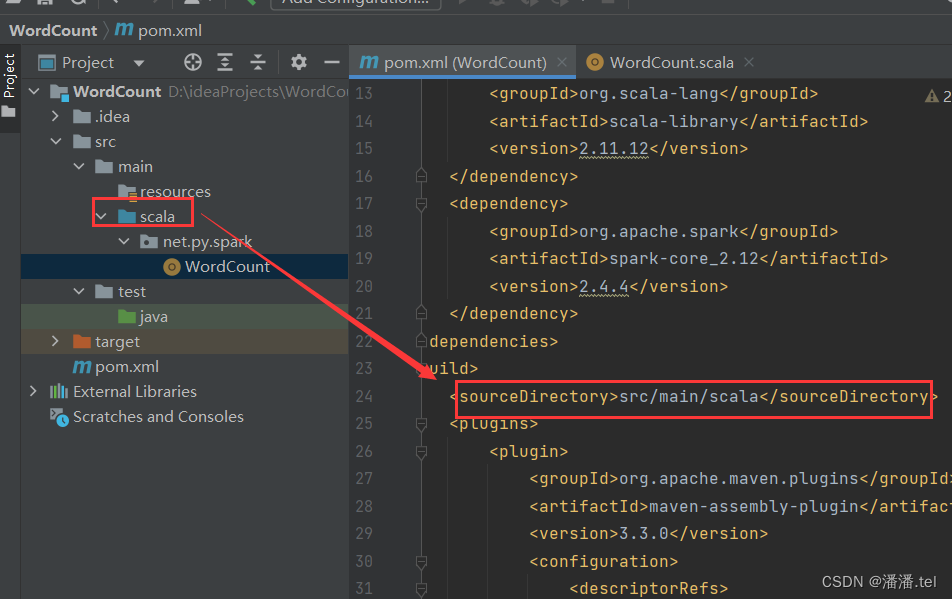
2、添加Scala和Spark依赖
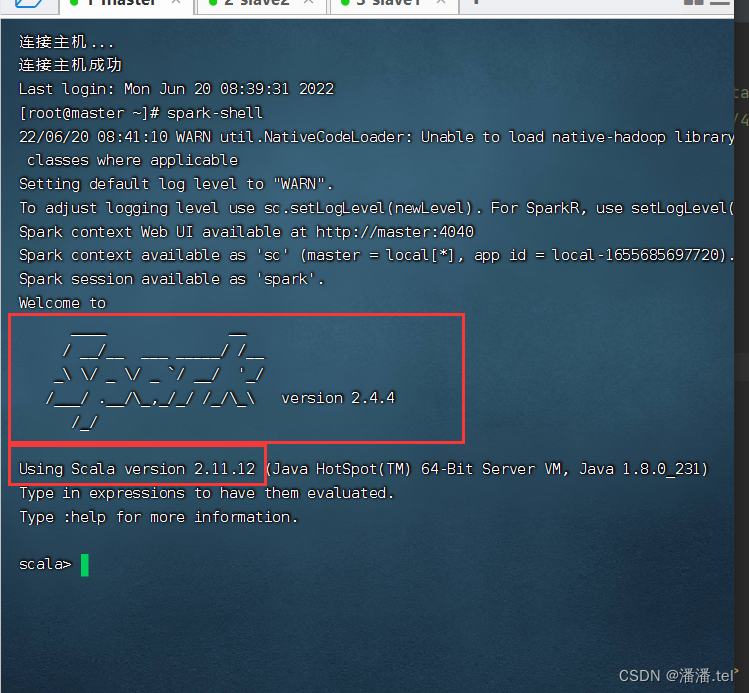
启动spark-shell,可以看到Spark2.4.4使用Scala2.11.12
在pom.xml文件里添加Scala2.11.12和Spark 2.4.4依赖,添加Maven构建插件
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>net.py.spark</groupId>
<artifactId>WordCount</artifactId>
<version>1.0-SNAPSHOT</version>
<dependencies>
<dependency>
<groupId>org.scala-lang</groupId>
<artifactId>scala-library</artifactId>
<version>2.11.12</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.12</artifactId>
<version>2.4.4</version>
</dependency>
</dependencies>
<build>
<sourceDirectory>src/main/scala</sourceDirectory>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-assembly-plugin</artifactId>
<version>3.3.0</version>
<configuration>
<descriptorRefs>
<descriptorRef>jar-with-dependencies</descriptorRef>
</descriptorRefs>
<archive>
<manifest>
<!--设置Spark应用的入口类-->
<mainClass>net.hw.spark.WordCount</mainClass>
</manifest>
</archive>
</configuration>
<executions>
<execution>
<id>make-assembly</id>
<phase>package</phase>
<goals>
<goal>single</goal>
</goals>
</execution>
</executions>
</plugin>
<plugin>
<groupId>net.alchim31.maven</groupId>
<artifactId>scala-maven-plugin</artifactId>
<version>3.3.2</version>
<executions>
<execution>
<id>scala-compile-first</id>
<phase>process-resources</phase>
<goals>
<goal>add-source</goal>
<goal>compile</goal>
</goals>
</execution>
<execution>
<id>scala-test-compile</id>
<phase>process-test-resources</phase>
<goals>
<goal>testCompile</goal>
</goals>
</execution>
</executions>
</plugin>
</plugins>
</build>
</project>
3、创建WordCount对象
在net.py.spark包里创建wordcount对象
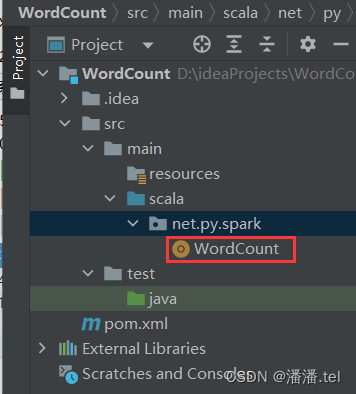
package net.py.spark
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object WordCount {
def main(args: Array[String]): Unit = {
// 创建SparkConf对象,存储应用程序配置信息
val conf = new SparkConf()
.setAppName("Spark-WordCount") // 设置应用程序名称,可在Spark WebUI中显示
.setMaster("spark://master:7077") // 设置集群Master节点访问地址
// 创建SparkContext对象,该对象是提交Spark应用程序的入口
val sc = new SparkContext(conf)
// 读取指定路径(程序执行时传入的第一个参数)的文件内容,生成一个RDD
val rdd: RDD[String] = sc.textFile(args(0))
// 对rdd进行处理
rdd.flatMap(_.split(" ")) // 将RDD的每个元素按照空格进行拆分并将结果合并为一个新RDD
.map((_, 1)) //将RDD中的每个单词和数字1放到一个元组里,即(word,1)
.reduceByKey(_ + _) //对单词根据key进行聚合,对相同的key进行value的累加
.sortBy(_._2, false) // 按照单词数量降序排列
.saveAsTextFile(args(1)) //保存结果到指定的路径(取程序执行时传入的第二个参数)
//停止SparkContext,结束该任务
sc.stop();
}
}
4、上传Spark应用程序到master虚拟机
将WordCount-1.0-SNAPSHOT.jar上传到master虚拟机/home/py目录
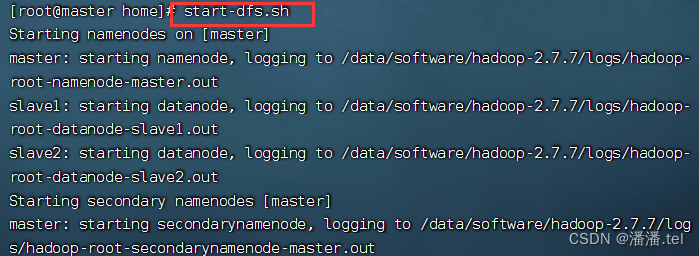
5、启动HDFS服务
执行命令:start-dfs.sh
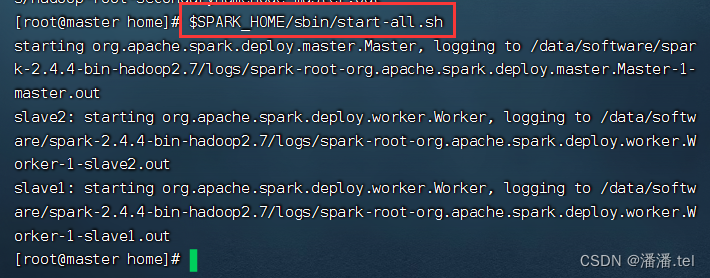
6、启动Spark集群
执行命令:$SPARK_HOME/sbin/start-all.sh

7、上传单词文件到HDFS指定目录
创建单词文件word.txt
上传到HDFS的/wordcount目录
8、执行WordCount程序
(1)提交应用程序到集群中运行
执行命令:
[root@master home]# spark-submit --master spark://master:7077 -class net.py.spark.WordCount WordCount-1.0-SNAPSHOT.jar hdfs://master:9000/wordcount hdfs://master:9000/wordcount_output
(2)命令参数解析
–master:Spark Master节点的访问路径。由于在WordCount程序中已经通过setMaster()方法指定了该路径,因此该参数可以省略。
–class:SparkWordCount程序主类的访问全路径(包名.类名)。
hdfs://master:9000/wordcount:单词数据的来源路径。该路径下的所有文件都将参与统计。
hdfs://master:9000/wordcount_output:统计结果的输出路径。与MapReduce一样,该目录不应提前存在,Spark会自动创建。
(3)Spark WebUI界面查看 应用程序信息
应用程序运行的过程中,可以访问Spark的WebUI http://master:8080/,查看正在运行的程序的状态信息(也可以查看已经完成的应用程序)