概述
1×1卷积首先是出现在Network in Network这篇论文当中,作者想要让网络变得更深,但并不是简单的去增加神经网络的层数。根据Aaditya Prakash (Adi)的观点,其实从某冲深度来讲用1×1卷积并不是是网络变得更深,而是更宽,这里的宽实际上是增加数据量,但是通过1×1的卷积我们就可以对原始图片做一个变换,得到一张新的图片,从而可以提高泛化的能力减小过拟合,;同时在这个过程中根据所选用的1×1卷积和filter的数目不同,可以实现跨通道的交互和信息的整合,而且还可以改变图片的维度.而且因为通过对维度的操作,虽然网络的层数增加了,但是网络的参数却可以大大减小,节省计算量。在实际应用的过程中,通常在卷积之后就跟着一个Relu之类的非线性层,把卷积的线性变成非线性,通过这个可以增加更多的非线性因素,理论上学习到更多的特征,包持feature map 尺寸不变(即不损失分辨率)的前提下大幅增加非线性特性,把网络做得很deep
基础背景
小白的话可以看一下,有背景知识就不用了。
卷积有很多地方可以看,这里需要注意的是图片从矩阵角度来讲,不要看作是一个平面,而是一个三维立方体,除了,height和width这个两个维度以外,第三个维度是图像的通道。这对于理解为什么1×1卷积能够实现跨通道的交互和信息的整合至关重要。而且1×1×F的卷积在数学上就等价与多层感知机,F是filter的数目,一个filter相当于就是对一张图片做一次卷积。
内容
1. 1×1卷积原理
因为是1×1的卷积,所以可以看成是在原图片的每一个像素都乘以了一个因子。以左图为例,两个filter因子分别记录为是
,
, 数学描述如下:
所以这也就解释了为什么实现跨通道的交互和信息的整合,而且还可以改变图片的维度
2. 减少参数
我们以googlelenet的网络结构举例子,左边的是没有使用1×1卷积的,右边是使用了1×1卷积的,我们来分别计算一下左右图参数的大小,在计算之前,先说明一下,previous
layer 输出的维度是(28×28×192)
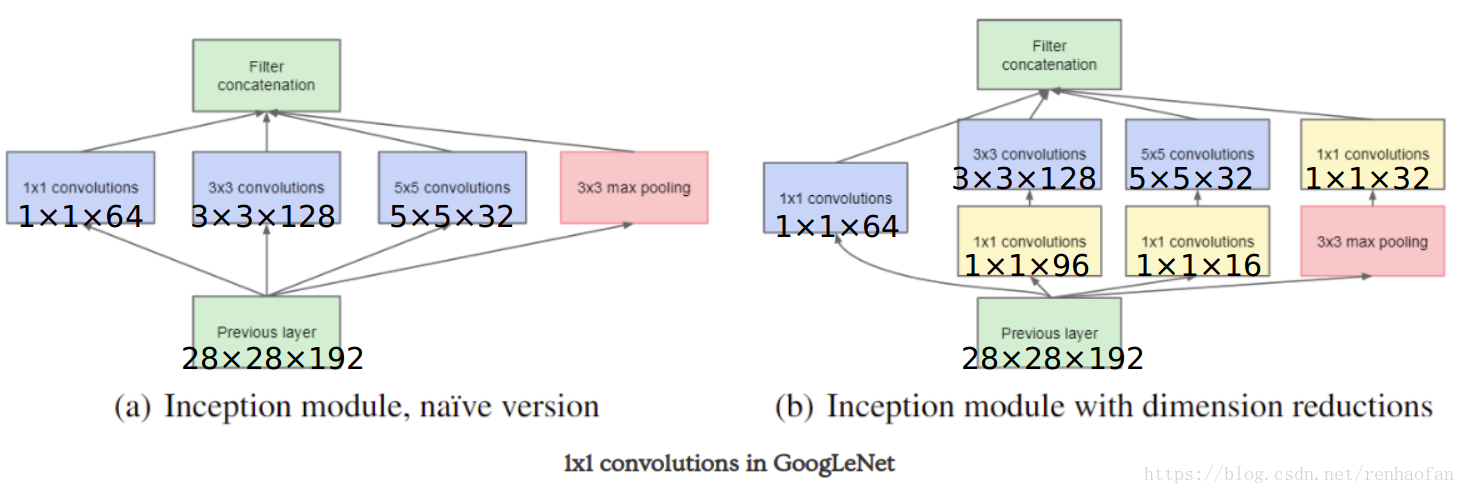
图a该层的参数为(1x1x192x64)+(3x3x192x128)+(5x5x192x32)
图b该层的参数为(1x1x192x64)+(1x1x192x96)+(1x1x192x16)+(3x3x96x128)+(5x5x16x32)+(1x1x192x32).
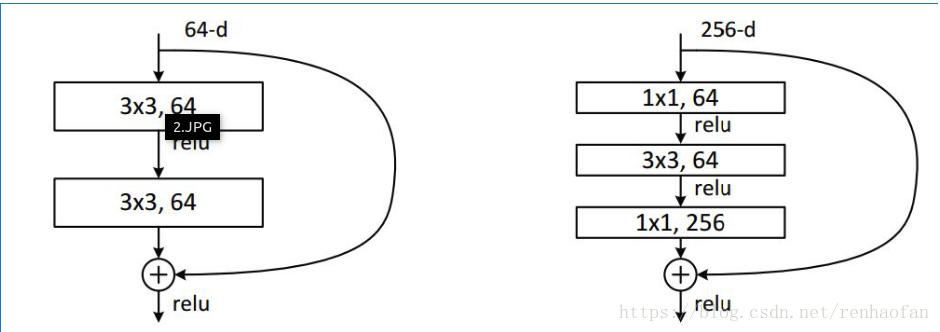
ResNet中同样利用了1×1卷积,在3×3卷积层的前后都使用了,不仅进行了降维,还进行了升维,使得卷积层的输入和输出的通道数都减小,参数数量进一步减少,如下图的结构: