版权声明:站在巨人的肩膀上学习。 https://blog.csdn.net/zgcr654321/article/details/83933715
chain rule:求导的链式法则。

接着上一节,我们想要minimize这个loss的值,我们需要计算梯度来更新w和b。

以一个neuron举例:

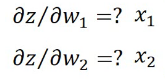 这个偏微分的结果就是输入x。
这个偏微分的结果就是输入x。

比如下面这个神经网络:

下面我们要计算这个偏微分:![]() 。这里的
。这里的![]() 以sigmoid函数为例。
以sigmoid函数为例。
比如我们的loss值如果是交叉熵函数,那么其实这个偏微分就是交叉熵函数的导数乘以sigmoid函数的导数。

我们现在假设![]() 和
和![]() 都已知,则
都已知,则

你可以把![]() 看成是另外一种neuron。
看成是另外一种neuron。

![]() 和
和![]() 是什么呢?
是什么呢?
假设后面的红色节点就是输出层,则

如果后面不是输出层,则继续往后推,就是递归思想,直到最后一层是输出层。

实际上就是建立一个反向的neural network,从输出层向前计算。

总结:
