这篇文章和skeleton based action recognition有关系,差别在于这篇文章不使用pose estimation估计好的人体关节坐标值,而是使用pose estimation得到的probability heatmap,考虑这个heatmap的演化进行动作识别。
摘要首先介绍大多数动作识别方法都是从整个video中识别人体动作,但是这种方法会受到很多影响,例如混乱的背景和一些non-action的动作,都会限制模型的表现。背景介绍完毕,开始介绍自己的工作,本文提出通过将人体动作视作pose estimation map的演化来进行动作识别,并且,本文不依赖于那些不精确的姿态估计结果,而是依赖于姿态估计的副产品——pose estimation map。
这个pose estimation map其实是pose estimation最终产物的前驱。从一个静态的图片中估计人体的关节的过程如下:首先,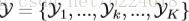
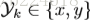
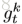
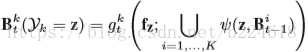
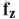
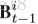
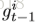
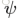
对于video第n帧,有K个不同的pose estimation map分别对应不同的关节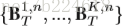

如上图所示的a到b的过程就是将每个关节的map取平均得到全身的map。而得到最终每个关节位置的预测值,其实就是从estimation map中取最大值就可以
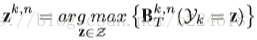
也就是从所有像素中选取值最大的,这个像素的坐标值作为第k个关节位置的预测。至此,video的每一帧都表示为一个heatmap和一个pose,video也就转化为了heatmap和poses的演化。
接下来介绍pose estimation map的演化。主要是将得到的heatmap的evolution压缩,每一个video变成一个body pose evolution image。首先介绍temporal rank pooling,对于一个video的heatmap的序列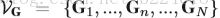
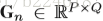
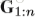
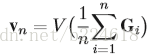
V是将一个matrix转化为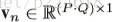
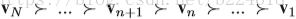
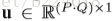
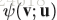
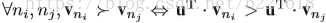

接着介绍spatial rank pooling,这个是考虑到temporal rank pooling主要保留了spatial的信息,而忽略了大多数temporal信息(作者对此的解释是让看上图的(d),看起来没有什么temporal的信息保留了,能看出来的是空间形状,这个理由是不是有点随意,还是我理解不够深?)。在每一个heatmap中,其实都有大量的冗余信息,因此,利用这种learning to rank的方法来将每一个heatmap表示成一个紧凑的compact feature,这个feature可以保留spatial的顺序。而将这些feature vector连起来就成了一个matrix,称为body shape evolution image,可以以一种紧凑的形式保留heatmap的时间和空间信息。下图展示了生成body shape evolution map的流程图
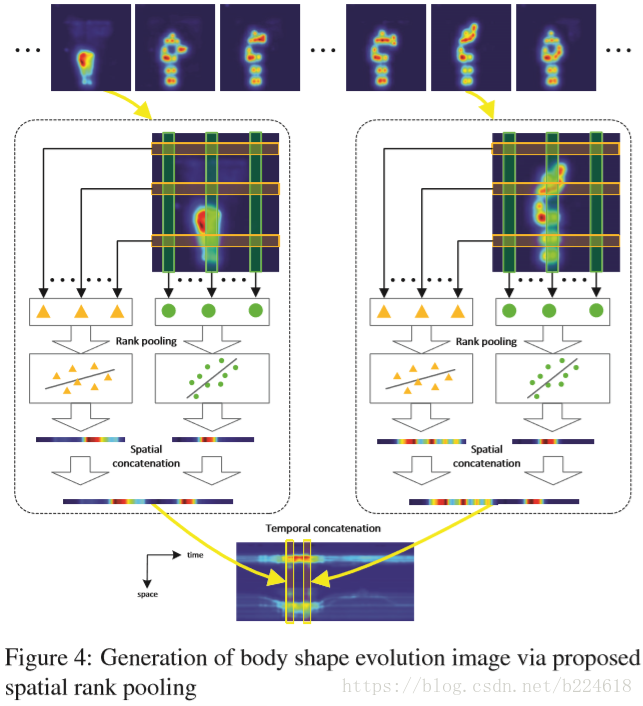
heatmap序列的第n帧被划分成P行,也就是说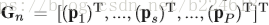
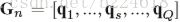
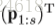
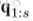
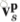
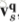
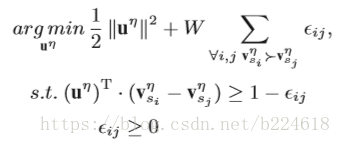
这里面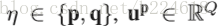
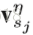
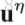
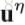

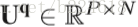
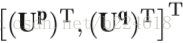
有了body shape evolution image,作者认为还是不够,认为这个image只是抓取了形状的信息,而没有考虑到每一个节点,因此又提出按照pose estimation的结果,将每一个节点编号,生成body pose image
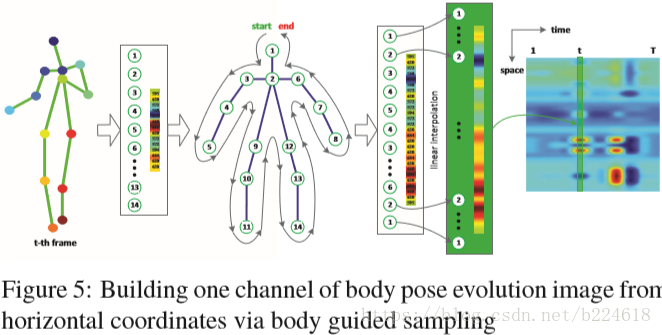
这个body pose image包含两个channel,每一个channel是根据x,y两个方向之一的坐标生成的。首先,所有的xy坐标值都被标准化为0,1之间的数,之后,按照人体的结构给关节编号,然后每个肢体(例如胳膊,腿这种两个关节之间的骨骼部分称之为肢体limb)都用两端的两个关节的坐标值进行线性插值增加五个节点(如上图所示,按照顺序在每两个原有的关节之间进行插值),这样,一帧人体骨架的一个坐标就处理好了,它构成了body pose image的一个channel的一行或一列,将所有帧都按此方法处理,就得到了body pose image的一个channel,xy坐标值都处理了就得到了完整的两个channel的body pose image。
最终进行分类的时候就是分别对body shape image和body pose image应用CNN,本文使用了imagenet上训练好的CNN模型,为了和这个已有的模型相适应,body shape image将自己的一个channel复制三份形成三个channel,body pose image通过添加一个全是0的channel得到三个channel。
总结:video中的每一帧确实都是有大量的冗余信息,本文巧妙地发现了这个问题,将每一帧有用的信息抓取出来,压缩成一个vector,然后将整个video转化为image,既保留了信息,又去除了大量冗余,还能利用已有的模型进行action识别。这里面有一点弄的不是很明白,就是temporal rank pooling和spatial rank pooling,temporal rank pooling具体是怎么优化的,能够让u包含了原image的信息,感觉文中写的好像有点太简单了,这样真的够吗?还有一个就是spatial rank pooling是怎么优化的,那个risk minimization和max-margin framework都是什么意思?