大多数基于视频的动作识别方法选择从整个视频中提取特征来识别动作。杂乱的背景和非动作的运动限制了这些方法的性能,因为它们缺乏对人体运动的明确建模。根据人体姿态估计的最新进展,本文提出了一种新的识别人体动作的姿态估计地图的进化方法。我们观察到,姿态估计图作为姿态估计的副产品,保留了更丰富的人体线索,从而有利于动作识别,而不是依赖视频中不准确的人体姿态估计。具体来说,位姿估计图的演化可以分解为热图的演化,例如概率地图的演化,以及二维人体位姿估计的演化,分别表示身体形态和姿态的变化。考虑到热图的稀疏性,我们采用空间秩池的方法将热图的演化集合为一个体型演化图像。由于体型进化图像不区分身体部位,我们设计了身体引导采样将姿态的进化汇总为形体进化图像。利用深度卷积神经网络预测动作标签,探讨了两种图像之间的互补特性。在NTU RGB+D、UTD-MHAD和PennAction数据集上的实验验证了该方法的有效性。
动机和目的
从视频中识别人的动作已经研究了几十年,因为这项任务在智能监控、人机交互和基于内容的视频检索等方面有多种应用。现有方法[22,43,37,24,1]的本质属性是学习映射,将视频转换为动作标签的功能。由于这些方法不能直接区分人体和视频,因此容易受到杂波和背景非动作运动的影响。
为了解决这一局限性,另一种解决方案是检测人体[39]并估计每一帧的身体姿态。这种方法在深度视频中的人类动作识别领域工作得很好,例如微软的Kinect[55, 27]。利用[36]精确的人体姿态估计方法,从每一深度帧中检测出三维姿态,将深度视频中的人体运动简化为三维姿态序列[52]。最近的深度学习模型,如CNNRNN[9]和LSTM[26,25]在提取的3D姿态上取得了较高的性能,优于依赖raw的方法[32,50]。
3D人体姿态的成功启发了我们去估计2D人体姿势从视频动作识别。然而,尽管2D位姿估计有了重大进展。在图像和视频中[51,5,46,2,4],性能仍然不如深度视频中的3D位姿估计。图1说明了利用最先进的姿态估计方法[4]从视频帧估计的姿态。由于复杂的背景和人体部位的自遮挡,估计出的姿态不完全可靠,可能会误解人体的形态在图1 (b)的第一行中,白边框中的多模态位姿估计图表示了人的手的位置。该地图包含两个峰值,其中ground truth的位置与最高峰值不对应,因此提供了对手位置的错误估计。

图1:从视频帧中估计的姿态和热图(平均姿态估计图)的互补特性。(a)将来自PennAction数据集[54]的动作“棒球投球”简化为两个帧。红圈和红星分别表示手和脚。(b)姿态估计不准确,估计的姿态不能准确标注人体部位。例如,我们给出了手的姿态估计图,其中多个峰值导致错误的预测。(c)虽然热图不能区分身体部位,但它们提供了更丰富的信息来反映人体形状。
为了更好地利用姿态估计图,我们提出将姿态估计图的演化直接建模用于动作识别,而不是依赖于从姿态估计图中得到的不准确的二维姿态。在无花果。1 (c),热图(平均姿态估计图)提供更丰富的信息,以反映人体形状。
方法概述及贡献
我们的方法如图2所示。给定视频的每一帧,我们使用卷积姿态机来预测身体各部分的姿态估计图。表示这些姿态估计图的目的是同时保留整体线索和局部线索,前者反映了较少受噪声影响的整体形状,后者详细描述了身体部位的位置。
为此,我们对人体各部位的姿态估计图进行平均,生成平均的姿态估计图(热图)为每帧。热图的时间演化可以反映人体形态的运动。与原始的RGB图像不同,热图是稀疏的。考虑到巨大的空间冗余,我们开发了一种空间秩池方法来压缩热图作为一个紧凑而有信息的特征向量,空间秩池的优点在于,它可以有效抑制空间冗余,且不会显著丢失热图的空间分布信息。对特征向量进行时间级联,构造出二维形体演化图像,反映了形体的时间演化。
由于体型进化图像不能区分身体部位,我们进一步从身体各部位的姿态估计图中预测关节位置,生成每一帧的姿态。
由于估计的位姿关节数量有限,我们利用人体结构来指导对更丰富的位姿关节进行采样来表示人体。所有位姿关节的时间级联构成了反映身体部位时间演化的体姿进化图像。直观地看,形体演化图像和姿态演化图像有利于形体的一般动作识别和身体部位的精细动作识别。因此,两幅图像都被CNNs探索,以产生鉴别特征,这些特征被后期融合来预测动作标签。一般来说,我们的贡献是三倍的。
考虑到从视频中估计的不准确的2D姿态,我们通过将动作识别为姿态估计地图的进化而不是不可靠的2D身体姿态来提高人体动作识别的性能。
将姿态估计图的演化描述为形体演化图和形体演化图,它们以简洁的方式捕捉整个身体和身体特定部位的运动。该方法在NTU RGB+D、UTD-MHAD和PennAction数据集上取得了最先进的性能。
基于位置的3D动作识别
3D姿态提供了直接的物理解释,从人类的行动,从深度视频。手工制作的特性[42,47,13]被设计用于描述三维姿态的演化。近年来,深度神经网络被引入到姿态的空间结构和时间动力学建模中。例如,Du等[9]首先使用分层RNN进行基于位置的动作识别。Liu等[25]扩展了这一思想,提出了时空LSTM,用于学习时空域。提高LSTM的注意能力,即全局上下文感知注意。
视频动作识别
局部特征与运动相关,在一定程度上对杂乱的背景具有鲁棒性。利用时空兴趣点(STIPs)[22]和密集轨迹[43]提取和描述局部时空模式。在这些基本特征的基础上,提出了多特征最大边缘分层贝叶斯模型[49]和一种新的特征增强技术——多跳跃特征叠加[21],以学习更有特色的特征。由于局部特征忽略全局关系,整体特征采用双流卷积netwo编码,它通过时空融合卷积网络来学习时空特征。在此网络基础上,进一步探讨了时空结构之间的关系[11,45]。与两流网络不同的是,动作的时空信息可以在输入到网络神经网络之前进行融合。Fernando等人[12]提出了秩池化方法,将所有视频帧聚合成一个紧凑的表示。Bilen等[1]将秩池化方法与CNN深度合并,生成高效的动态图像网络,
人类的行为是身体运动固有的结构模式。最近的研究[56,31,14,38,30]提取了整个人体或身体部位,而不是整个视频进行动作分析。与此同时,人类的行为识别和结合姿态估计任务提取姿态引导特征用于识别。Wang et al.[41]改进了现有的位姿估计方法,设计了位姿特征来捕获身体部位的时空构型。Xiaohan等人[48]提出了一种将动作识别和姿态估计的训练与测试相结合的框架。它们将动作分解为姿态,姿态再进一步分解为中等水平的st -part和parts。最近,Du等人[8]提出了一种端到端递归网络,该网络可以利用人体姿态的重要时空进化在统一框架下辅助动作识别。与姿态特征[41]和姿态引导的颜色特征[48,8]不同,本文仅从姿态估计图中识别人类动作,这是之前没有研究过的动作识别任务。
生成姿态估计地图
本节预测视频的每一帧的姿态估计图(图3 (a)),然后生成一个热图(图3 (b))和一个位姿(图3 (c))表示每一帧。姿态估计映射:从单幅图像中估计人体姿态的任务可以建模为结构预测问题。在[34]中,提出了一种姿态机序列预测人体关节的姿态估计映射,其中先前预测的姿态估计映射迭代地改进后续阶段的估计。令Yk∈{x, y}表示体关节k处的坐标集。结构输出可表示为Y = {Y1,…,即,…, YK},其中K为体关节总数。在第tth阶段训练多分类器gkt预测第k个体关节。对于图像位置z,为姿态估计映射将其分配到第k个体关节,公式为:
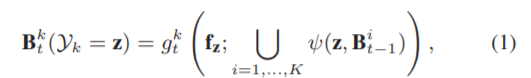
其中fz是z位置的颜色特征,而B it−1是g it−1预测的姿态估计图∪是向量拼接的操作符,而而钧则是从之前的位姿估计映射中计算上下文特征的特征函数。T阶段后,生成的姿态估计图用于预测人体关节的位置,姿态机[34]采用带随机森林的增强分类器对学习能力较弱的学习者进行分类。相反,本文采用了卷积造成机[46,4],将姿态机与卷积的架构结合起来,不需要图形模型风格推断,提高了造成机器的性能。
Heatmaps & pose:对于视频的第n帧,有K种姿态估计映射,即{B1, nT,……BK, nT},生成。为了减少位姿估计图的冗余度,我们将其描述为热图Gn和位姿Ln。热图Gn可以表示为:

反映了全球的体型。Ln位姿可以表示为{zk,n}kk =1,其中zk,n通常是通过后验(MAP)准则[4]:

其中Z∈R2表示图像上的所有位置。到目前为止,视频的每一帧都被描述为热图和姿势。换句话说,视频被转化为热图的演变和姿态的演变。
位姿估计地图的演化
本节描述了利用时间秩池将热图作为体型演化图像进行演化(图3 (d)),在此基础上发展空间秩池(图3 (e))。进一步,采用人体引导采样的方法将姿态的演化描述为人体姿态演化图像(图3 (f))。利用网络神经网络学习了两幅图像间的互补性质。

图3:从两个视频中提取的特征的比较。(a)左视频表示动作“wave”,右视频表示动作“扔”。(b)热图的演变。每个热图都是一个灰度图像。为了便于观察,我们使用colormap根据灰度值来突出热图。(c)姿势的演变。每个关节用特定的颜色显示。为了便于观察,我们还把四肢涂成绿色。(d)采用时间秩池(t-rk)实现体型进化图像。(e)利用空间秩池(s-rk)实现体型演化图像。(f)人体引导采样实现的人体姿态进化图像。
时间秩池:作为一种鲁棒且紧凑的视频表示方法,时间秩池[12,1]能够通过学习排序的方法聚合整个视频的时间相关信息。编码的时间信息表示帧间的时间顺序,是一个鲁棒特征,对不同类型的输入数据不那么敏感。由于热图不同于自然图像,我们将热图作为一种新的数据类型,并应用时间级别池对热图的演化进行编码。假设一个序列VG = {G1,…, Gn,…, GN}包含N个热图,和
Gn∈RP×Q为P行Q列的第n个框架。G1:n可映射到定义为:
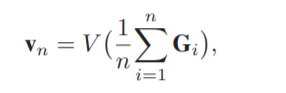
其中函数V将一个矩阵重塑为一个向量,vn∈R(P·Q)×1。让vn + 1≻vn表示时间顺序关系vn + 1 vn。自然约束帧间vN≻……≻vn + 1≻vn≻……≻v1。时间秩池(t-rk)[12]优化参数u∈R(P·Q)线性函数的x 1 (v;u)确保这一点∀倪新泽西,vni≻vnj⇔uT·vni > uT·vnj。采用参数u表示时间秩pooling方法,隐式编码序列的外观演化信息。空间秩池化:将u重塑为相同大小的输入框,便于观察。所示
图3 (d),时间秩池方法主要保留空间信息,忽略大部分时间信息。为了改进这一点,我们提出一个建议:
空间秩池法(s-rk)考虑了空间和时间信息。观察发现,每个热图都存在巨大的空间冗余。因此,我们利用学习排序的方法,将每个热图缩减为一个紧凑的特征,具有保持空间顺序的能力。将所有的特征向量按照时间顺序进行拼接,得到一幅形体演化图像,可以更紧凑地保留热图的时空信息生成体型演化图像的流程如图4所示。具体来说,我们将序列V的第n个帧划分为P行,即:Gn = [(p1)T…,(ps)T,…(页)T]T或Q列,也就是,Gn = [q1,……, qs,……, qQ]。与Eq. 4相似,将函数V应用于map (p1:s))T和q1:s到vps和vqs,分别。利用结构风险最小化和最大保证金框架,目标被定义为:
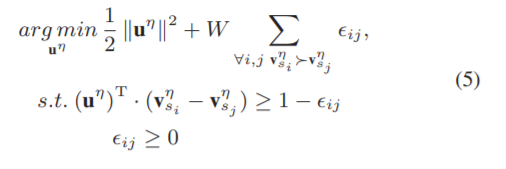
![]() 帧,我们按照时间顺序将向量拼接,得到
帧,我们按照时间顺序将向量拼接,得到![]() 其中U被称为体型进化形象。
其中U被称为体型进化形象。
体姿采样:由于体姿进化图像只考虑累积的姿态估计图的形状,而不区分不同的关节,所以我们需要体姿进化图像考虑各个具体关节的信息。为此,本节从关节处构建人体姿态进化图像,通过人体引导采样对关节进行密集采样,以表示人体的具体姿态假设一个序列VL = {L1,…, Ln,…,LN}包含N个pose,其中LN ={z k, n}kk =1, zk,n = (xk,n, yk,n),表示第K个关节的水平和垂直坐标。当:

图4:提出的空间秩池生成体型演化图像

图5:通过人体引导采样,从水平坐标构建人体姿态进化图像的一条通道
在拍摄姿势序列时,人体和深度视频之间的距离并不完全相同。换句话说,不同的姿态序列有它们自己的尺度,这使得相同类型的动作具有内部变化。为此,{{x k,n}K K = 1}N N =1和{{y k, N}K K = 1}N N =1被标准化,分别从0变到1:
o分别从0变到1。为了对位姿关节的时空演化进行简洁的编码,我们将预处理后的位姿序列VL表示为人体位姿演化图像。由于原始估计的姿态关节过于稀疏,无法代表人体,我们根据人体结构对关节标签进行排序,并采用线性插值的方法从姿态肢体中提取丰富的点从水平坐标构建人体位姿进化图像一条通道的管道如图5所示。同样可以建立垂直坐标下人体姿态进化图像的另一个通道。数学上,让x n = [x1, n,…, xK的n]T和y n = [y1, n,…,即“n]T表示生成的关节的坐标向量,其中K’为采样的关节总数。在我们的实验中,通过对每个肢体上的五个关节进行采样,可以粗略地表示出姿态肢体。假设K = 14,且肢数为K−1,则K’可计算为K + (K−1)×5 = 79。体位姿进化图像形成两条通道为[x]1,……, xN)和[y1,……yN],分别表示水平坐标和垂直坐标。两种通道反映了关节的时间演化,密集采样表示人体的姿态。
后期融合:将视频I c分别表示为形体进化图像和形体姿态进化图像,其中c表示一批中用于训练的第cth个样本。由于CNN在图像分类任务上取得了成功,我们使用预先训练好的CNN模型用于迁移学习的Imagenet[7]。由于这两幅图像所包含的空间结构明显不同,所以我们使用单独的CNN来探究它们的深层特征。为适应现有CNN模型,将形体进化图像的单通道重复三次,形成3通道图像,将人体姿态进化图像的两个通道与一个零值通道相结合,形成了一个自适应自适应通道三路的形象。令{I c m}2 m=1表示这两个图像。为了提高收敛速度,对输入图像进行均值去除。然后用CNN对每幅彩色图像进行处理。图片我c m,最后的输出Υm fullyconnected (f c)层是通过将softmax函数归一化得到后验概率:概率(r |我c m) = eΥr m /R j = 1 eΥj m,这表明图像的概率我属于第r类行动。R是a的总数我们的模型的目标函数是最小化最大似然损失函数L (Im) =−2 c=1 ln r r=1个叫(r−sc) prob(r | I c m),其中r= sc等于1,否则等于0,sc为I c m的ground truth label, c为批大小。对于序列I,它的最终类得分是两个后端得分的平均值:score(r | I) = 122 m=1 prob(r |Im),其中prob(r |Im)是Im属于第rth操作类的概率。
数据集和设置
PennAction数据集[54]包含15个动作类别和2326个序列。由于所有的序列都是从互联网上收集的,复杂的身体遮挡,大的外观和运动变化,使其具有挑战性:
表1:NTU RGB+D、UTD-MHAD和评价体型进化图像和体位姿进化图像
PennAction数据集。BPI是body pose evolution image的缩写。BSI是体型进化图像的缩写。BSI (t-rk)是用时间级别池实现BSI的缩写。BSI (s-rk)是用空间秩池实现BSI的缩写。为了加快计算速度,采用近似秩池[1]实现秩池方法。与姿态相关的动作识别[48,8]。我们按照[48]将数据一分为二以进行训练和测试。估计姿态1的快照如图6所示。


实现细节:在我们的模型中,每个CNN包含5个卷积层和3个fc层。第一层和第二层f c包含4096个神经元,第三层神经元的数量等于action类的总数。设置过滤器尺寸为11×11、5×5、3×3,分别是3×3和3×3。当地响应Normaliza采用tion (LRN)、max pooling和ReLU神经元,dropout正则化率设为0.5。网络权值通过将动量值设为0.9,权值衰减设为0.00005的小批量随机梯度下降来学习。学习率设置为0.001,最大训练周期设置为60。当CNN模型在训练集上达到99%的准确率时,训练程序提前停止。在每个周期的mini-batch C样品是由随机抽样从训练集图像。南大RGB + D数据集,UTD-MHAD数据集和PenAction数据集,C是设置为64,16和16,考虑训练集的规模。减少的效果随机参数初始化和随机抽样,我们对五次重复CNN模型的训练和报告的平均结果。实现基于
火枪:一张泰坦X卡,16G内存。
2D姿态和3D姿态深度视频:由于从视频中估计的姿态失去了深度线索,我们开始评估深度信息对基于姿态的人类动作识别的重要性。在表1中,从深度视频中提取的三维位姿序列描述为三通道体位姿演化图像,通过
CNN预测动作标签。这种方法称为“S2”。
通过设置所有的深度通道的值为零,2D位姿序列从深度视频代替。这种方法称为“S1”。没有使用深度通道,精度从89.44%下降到85.53%