它的主要思想是把所有的数据看做空间中的点,这些点之间可以用边连接起来。距离较远的两个点之间的边权重值较低,而距离较近的两个点之间的边权重值较高,通过对所有数据点组成的图进行切图,让切图后不同的子图间边权重和尽可能的低,而子图内的边权重和尽可能的高,从而达到聚类的目的。

构建邻接矩阵W的方法有三类。ϵ-邻近法,K邻近法和全连接法。
ϵ-邻近法:两点间的权重要不就是ϵ,要不就是0,没有其他的信息,距离远近度量很不精确。
K邻近法:

全连接法:可以选择不同的核函数来定义边权重,常用的有多项式核函数,高斯核函数和Sigmoid核函数。最常用的是高斯核函数RBF,此时相似矩阵和邻接矩阵相同:
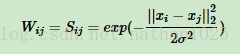
拉普拉斯矩阵L=D−W。D即为我们第二节讲的度矩阵,它是一个对角矩阵,而W即为我们第二节讲的邻接矩阵。
对于任意的向量f,我们有


例子一
1.以下是简单的用KNN方式获得的相似度矩阵

标记最接近自己的k个数据,w[i][k] = 1 其实可以用dis_martix来赋值
for idx,each in enumerate(dis_matrix):
index_array = np.argsort(each)
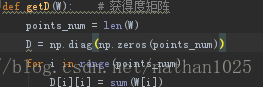
W[idx][index_array[1:k+1]] = 1 # 距离最短的是自己2.接下来是度矩阵
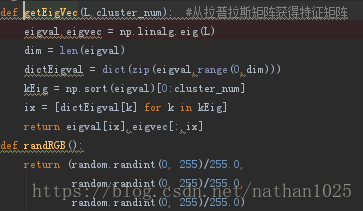
3.根据L跟最后分类的num数,来获得特征向量
eigval,eigvec = getEigVec(L,cluster_num)可以看到是选取最小的num个特征
4.用其他聚类方法进行聚类
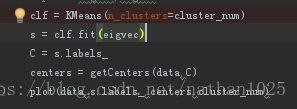
例二:
1.用核函数,获取相似矩阵
from sklearn.metrics.pairwise import rbf_kernelW = similarity_function(points)
2.度矩阵
D = np.diag(np.sum(W, axis=1))
3 拉普拉斯矩阵

4.算出前k小的特征向量

5. 用其他聚类算法进行聚类

https://blog.csdn.net/asd991936157/article/details/54314853
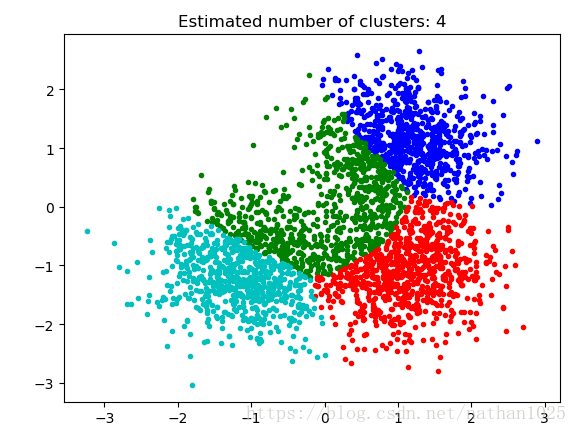
例三:
直接sklearn
from sklearn.cluster import spectral_clustering
n_clusters_ = 4 lables = spectral_clustering(metrics_metrix, n_clusters=n_clusters_)