简述
这篇是在网上看了wiki之后写出来的代码。
附上一篇看过论文之后根据论文实现的版本:【论文阅读和实现】On Spectral Clustering: Analysis and an algorithm【Python实现】
In multivariate statistics and the clustering of data, spectral clustering techniques make use of the spectrum(eigenvalues) of the similarity matrix of the data to perform dimensionality reduction before clustering in fewer dimensions. The similarity matrix is provided as an input and consists of a quantitative assessment of the relative similarity of each pair of points in the dataset.1 在多元统计和数据聚类当中,谱聚类技术充分利用了数据的相似度矩阵光谱(特征值)来实现在聚类之前的降维到更小的维度下。这个相似度矩阵被提供作为输入,包括有在每对点之间的关联相似度的量化方法。
Given an enumerated set of data points, the similarity matrix may be defined as a symmetric matrix , where represents a measure of the similarity between data points with indices and .
给一个可数的点集,相似度矩阵可以被定义为一个对称矩阵 , 并且 表示的是有着下面的index的 和 两个点之间的相似度。
一般来说的谱聚类方法,就是会使用一些标准的聚类方法(包括有Kmean) 相关的拉普拉斯矩阵的特征向量上。 有很多种方式来定义拉普拉斯矩阵,每种都有自己的数学解读。并且因此这个聚类的也会有不同的解读。
这些相关的特征向量是一个基于最小的几个拉普拉斯矩阵的特征值,除了最小的那个0。为了计算的速度,这些特征向量经常被计算为拉普拉斯函数的最大的特征值对应的特征向量。
图问题的拉普拉斯矩阵被定义为
D是对角矩阵,然后对角元为对应节点的度。
一个非常著名相关的谱聚类技术,用到了normalized cuts algorithm ,被广泛用于图片分割。分割的时候,基于的特征想来是对称正则化拉普拉斯矩阵的第二小的特征。 这个矩阵被定义为
算法
To perform a spectral clustering we need 3 main steps:2
- Create a similarity graph between our N objects to cluster. 在N个对象上创建相似性矩阵
- Compute the first k eigenvectors of its Laplacian matrix to define a feature vector for each object. 计算出前k个拉普拉斯矩阵的特征向量,给每个点定义一个表征向量。
- Run k-means on these features to separate objects into k classes. 在这个表征向量上再做k-means
针对图算法
- 先构建图网络的链接
- 计算出拉普拉斯矩阵
- 做特征分解,得到特征向量,用于做表征向量
- 在这个基础上再做一般的聚类方法
还是一样的,为了封装性,我这就直接写了 函数内嵌套着函数~
import numpy as np
from sklearn.cluster import KMeans
def spectral_cluster(X, n_clusters=3, sigma=1, k=5, n_eigen=10):
def graph_building_KNN(X, k=5, sigma=1):
N = len(X)
S = np.zeros((N, N))
for i, x in enumerate(X):
S[i] = np.array([np.linalg.norm(x - xi) for xi in X])
S[i][i] = 0
graph = np.zeros((N, N))
for i, x in enumerate(X):
distance_top_n = np.argsort(S[i])[1: k+1]
for nid in distance_top_n:
graph[i][nid] = np.exp(-S[i][nid] / (2 * sigma ** 2))
return graph
graph = graph_building_KNN(X, k)
def laplacianMatrix(A):
dm = np.sum(A, axis=1)
D = np.diag(dm)
L = D - A
sqrtD = np.diag(1.0 / (dm ** 0.5))
return np.dot(np.dot(sqrtD, L), sqrtD)
L = laplacianMatrix(graph)
def smallNeigen(L, n_eigen):
eigval, eigvec = np.linalg.eig(L)
index = list(map(lambda x: x[1], sorted(zip(eigval, range(len(eigval))))[1:n_eigen+1]))
return eigvec[:, index]
H = smallNeigen(L, n_eigen)
kmeans = KMeans(n_clusters=n_clusters).fit(H)
return kmeans.labels_
- 测试
from sklearn import datasets
from sklearn.decomposition import PCA
iris = datasets.load_iris()
X_reduced = PCA(n_components=2).fit_transform(iris.data)
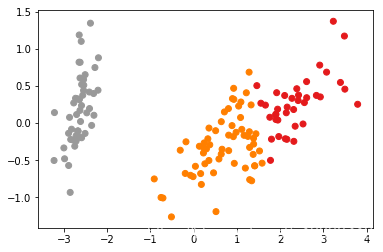
y = spectral_cluster(X_reduced, k=10, n_clusters=3)
plt.scatter(X_reduced[:, 0], X_reduced[:, 1], c=y, cmap=plt.cm.Set1)

- 实际图

有部分检测的不是很好,sklearn上的实现的版本,实际上改进之后的版本spectral-embedding,效果好很多。
- sklearn的谱聚类效果图