这是GermEval 2019 Task 1 – Shared task on hierarchical classification of blurbs的一个实验性文章,文中所关注的问题总体上来说属于文本分类,但根据所使用的数据集具体来说是一个关于层次化标签的文本多分类任务。相对于基本的文本分类所使用的数据集,本文中所使用的的GermEval2019中样本的内容包含:
- 标题
- 作者列表
- 描述性文本
- URL
- ISBN号
- 出版日期
根据任务的需求,每一个层次所包含的数据类型是不同的,而且根据具体层次的数据又有对应的标签。其中标题、作者列表和描述性文本所对应的的类别数为8、93和242。因此,针对于具体层次的分类难度是不同的。作者使用BERT来获取文档的表示,同时通过统计样本的元数据(如作者的个数、是否为学术性标题、标题所包含的单词数等)和基于维基百科的图嵌入模型(Graph embedding model)来为最后的分类提供额外的信息,从而最终提升分类模型的性能。
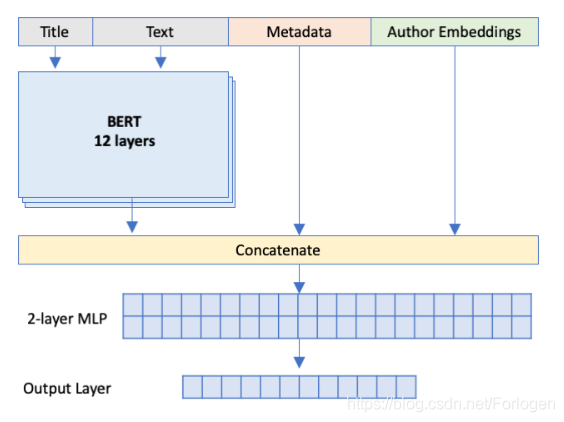
模型示意图如下所示,结构清晰,原理简单。首先通过BERT获取关于Title和Text的表示向量,在使用MLP进行分类预测前,将上述两种方式提供的额外信息表示和Title和Text的表示向量进行拼接,最后通过Softmax的全连接层进行类别预测。
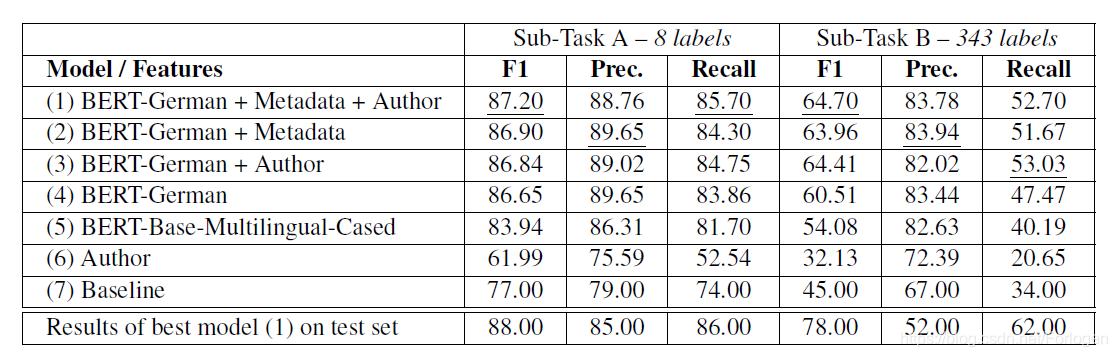
实验结果如下所示,通过消融实验可以看出额外提供的信息的确可以帮助提升分类模型的性能。
由于只是实验性文章,因此没有太多新的思想,详细的内容可见原文~
